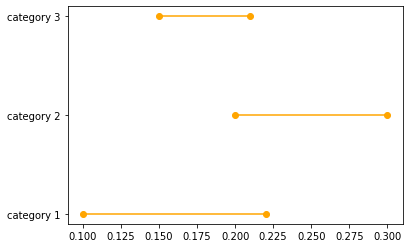
For a confidence interval across categories, building on what omer sagi suggested, let's say if we have a Pandas data frame with a column that contains categories (like category 1, category 2, and category 3) and another that has continuous data (like some kind of rating), here's a function using pd.groupby() and scipy.stats to plot difference in means across groups with confidence intervals:
import pandas as pd
import numpy as np
import scipy.stats as st
def plot_diff_in_means(data: pd.DataFrame, col1: str, col2: str):
"""
Given data, plots difference in means with confidence intervals across groups
col1: categorical data with groups
col2: continuous data for the means
"""
n = data.groupby(col1)[col2].count()
# n contains a pd.Series with sample size for each category
cat = list(data.groupby(col1, as_index=False)[col2].count()[col1])
# 'cat' has the names of the categories, like 'category 1', 'category 2'
mean = data.groupby(col1)[col2].agg('mean')
# The average value of col2 across the categories
std = data.groupby(col1)[col2].agg(np.std)
se = std / np.sqrt(n)
# Standard deviation and standard error
lower = st.t.interval(alpha = 0.95, df=n-1, loc = mean, scale = se)[0]
upper = st.t.interval(alpha = 0.95, df =n-1, loc = mean, scale = se)[1]
# Calculates the upper and lower bounds using SciPy
for upper, mean, lower, y in zip(upper, mean, lower, cat):
plt.plot((lower, mean, upper), (y, y, y), 'b.-')
# for 'b.-': 'b' means 'blue', '.' means dot, '-' means solid line
plt.yticks(
range(len(n)),
list(data.groupby(col1, as_index = False)[col2].count()[col1])
)
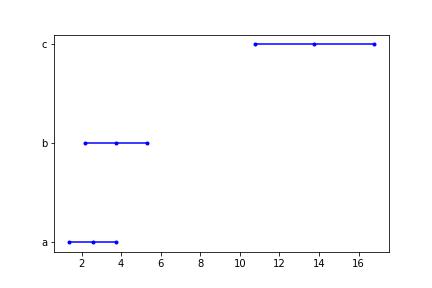
Given hypothetical data:
cat = ['a'] * 10 + ['b'] * 10 + ['c'] * 10
a = np.linspace(0.1, 5.0, 10)
b = np.linspace(0.5, 7.0, 10)
c = np.linspace(7.5, 20.0, 10)
rating = np.concatenate([a, b, c])
dat_dict = dict()
dat_dict['cat'] = cat
dat_dict['rating'] = rating
test_dat = pd.DataFrame(dat_dict)
which would look like this (but with more rows of course):
| cat |
rating |
| a |
0.10000 |
| a |
0.64444 |
| b |
0.50000 |
| b |
0.12222 |
| c |
7.50000 |
| c |
8.88889 |
We can use the function to plot a difference in means with a confidence interval:
plot_diff_in_means(data = test_dat, col1 = 'cat', col2 = 'rating')
which gives us the following graph:
![Enter image description here]()