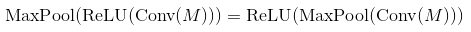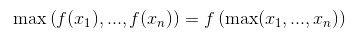The theory from these links show that the order of Convolutional Network is: Convolutional Layer - Non-linear Activation - Pooling Layer.
- Neural networks and deep learning (equation (125)
- Deep learning book (page 304, 1st paragraph)
- Lenet (the equation)
- The source in this headline
But, in the last implementation from those sites, it said that the order is: Convolutional Layer - Pooling Layer - Non-linear Activation
I've tried too to explore a Conv2D operation syntax, but there is no activation function, it's only convolution with flipped kernel. Can someone help me to explain why is this happen?