Yes! It really is more numerically stable.
For the case that you're looking at, the numbers [0.0, 0.1, ..., 0.9], note that under round-ties-to-away, only four of those numbers are rounding down (0.1 through 0.4), five are rounded up, and one (0.0) is unchanged by the rounding operation, and then of course that pattern repeats for 1.0 through 1.9, 2.0 through 2.9, etc. So on average, more values are rounded away from zero than towards it. But under round-ties-to-even, we'd get:
- five values rounding down and four rounding up in
[0.0, 0.9]
- four values rounding down and five rounding up in
[1.0, 1.9]
and so on. On average, we get the same number of values rounding up as rounding down. More importantly, the expected error introduced by the rounding is (under suitable assumptions on the distribution of the inputs) closer to zero.
Here's a quick demonstration using Python. To avoid difficulties due to Python 2 / Python 3 differences in the builtin round function, we give two Python-version-agnostic rounding functions:
def round_ties_to_even(x):
"""
Round a float x to the nearest integer, rounding ties to even.
"""
if x < 0:
return -round_ties_to_even(-x) # use symmetry
int_part, frac_part = divmod(x, 1)
return int(int_part) + (
frac_part > 0.5
or (frac_part == 0.5 and int_part % 2.0 == 1.0))
def round_ties_away_from_zero(x):
"""
Round a float x to the nearest integer, rounding ties away from zero.
"""
if x < 0:
return -round_ties_away_from_zero(-x) # use symmetry
int_part, frac_part = divmod(x, 1)
return int(int_part) + (frac_part >= 0.5)
Now we look at the average error introduced by applying these two functions on one-digit-after-the-point decimal values in the range [50.0, 100.0]:
>>> test_values = [n / 10.0 for n in range(500, 1001)]
>>> errors_even = [round_ties_to_even(value) - value for value in test_values]
>>> errors_away = [round_ties_away_from_zero(value) - value for value in test_values]
And we use the recently-added statistics standard library module to compute the mean and standard deviation of those errors:
>>> import statistics
>>> statistics.mean(errors_even), statistics.stdev(errors_even)
(0.0, 0.2915475947422656)
>>> statistics.mean(errors_away), statistics.stdev(errors_away)
(0.0499001996007984, 0.28723681870533313)
The key point here is that errors_even has zero mean: the average error is zero. But errors_away has positive mean: the average error is biased away from zero.
A more realistic example
Here's a semi-realistic example that demonstrates the bias from round-ties-away-from-zero in a numerical algorithm. We're going to compute the sum of a list of floating-point numbers, using the pairwise summation algorithm. This algorithm breaks the sum to be computed into two roughly equal parts, recursively sums those two parts, then adds the results. It's substantially more accurate than a naive sum, but typically not as good as more sophisticated algorithms like Kahan summation. It's the algorithm that's used by NumPy's sum function. Here's a simple Python implementation.
import operator
def pairwise_sum(xs, i, j, add=operator.add):
"""
Return the sum of floats xs[i:j] (0 <= i <= j <= len(xs)),
using pairwise summation.
"""
count = j - i
if count >= 2:
k = (i + j) // 2
return add(pairwise_sum(xs, i, k, add),
pairwise_sum(xs, k, j, add))
elif count == 1:
return xs[i]
else: # count == 0
return 0.0
We've included a parameter add to the function above, representing the operation to be used for addition. By default, it uses Python's normal addition algorithm, which on a typical machine will resolve to the standard IEEE 754 addition, using round-ties-to-even rounding mode.
We want to look at the expected error from the pairwise_sum function, using both standard addition and using a round-ties-away-from-zero version of addition. Our first problem is that we don't have an easy and portable way to change the hardware's rounding mode from within Python, and a software implementation of binary floating-point would be large and slow. Fortunately, there's a trick we can use to get round-ties-away-from-zero while still using the hardware floating-point. For the first part of that trick, we can employ Knuth's "2Sum" algorithm to add two floats and obtain the correctly-rounded sum together with the exact error in that sum:
def exact_add(a, b):
"""
Add floats a and b, giving a correctly rounded sum and exact error.
Mathematically, a + b is exactly equal to sum + error.
"""
# This is Knuth's 2Sum algorithm. See section 4.3.2 of the Handbook
# of Floating-Point Arithmetic for exposition and proof.
sum = a + b
bv = sum - a
error = (a - (sum - bv)) + (b - bv)
return sum, error
With this in hand, we can easily use the error term to determine when the exact sum is a tie. We have a tie if and only if error is nonzero and sum + 2*error is exactly representable, and in that case sum and sum + 2*error are the two floats nearest that tie. Using this idea, here's a function that adds two numbers and gives a correctly rounded result, but rounds ties away from zero.
def add_ties_away(a, b):
"""
Return the sum of a and b. Ties are rounded away from zero.
"""
sum, error = exact_add(a, b)
sum2, error2 = exact_add(sum, 2.0*error)
if error2 or not error:
# Not a tie.
return sum
else:
# Tie. Choose the larger of sum and sum2 in absolute value.
return max([sum, sum2], key=abs)
Now we can compare results. sample_sum_errors is a function that generates a list of floats in the range [1, 2], adds them using both normal round-ties-to-even addition and our custom round-ties-away-from-zero version, compares with the exact sum and returns the errors for both versions, measured in units in the last place.
import fractions
import random
def sample_sum_errors(sample_size=1024):
"""
Generate `sample_size` floats in the range [1.0, 2.0], sum
using both addition methods, and return the two errors in ulps.
"""
xs = [random.uniform(1.0, 2.0) for _ in range(sample_size)]
to_even_sum = pairwise_sum(xs, 0, len(xs))
to_away_sum = pairwise_sum(xs, 0, len(xs), add=add_ties_away)
# Assuming IEEE 754, each value in xs becomes an integer when
# scaled by 2**52; use this to compute an exact sum as a Fraction.
common_denominator = 2**52
exact_sum = fractions.Fraction(
sum(int(m*common_denominator) for m in xs),
common_denominator)
# Result will be in [1024, 2048]; 1 ulp in this range is 2**-44.
ulp = 2**-44
to_even_error = (fractions.Fraction(to_even_sum) - exact_sum) / ulp
to_away_error = (fractions.Fraction(to_away_sum) - exact_sum) / ulp
return to_even_error, to_away_error
Here's an example run:
>>> sample_sum_errors()
(1.6015625, 9.6015625)
So that's an error of 1.6 ulps using the standard addition, and an error of 9.6 ulps when rounding ties away from zero. It certainly looks as though the ties-away-from-zero method is worse, but a single run isn't particularly convincing. Let's do this 10000 times, with a different random sample each time, and plot the errors we get. Here's the code:
import statistics
import numpy as np
import matplotlib.pyplot as plt
def show_error_distributions():
errors = [sample_sum_errors() for _ in range(10000)]
to_even_errors, to_away_errors = zip(*errors)
print("Errors from ties-to-even: "
"mean {:.2f} ulps, stdev {:.2f} ulps".format(
statistics.mean(to_even_errors),
statistics.stdev(to_even_errors)))
print("Errors from ties-away-from-zero: "
"mean {:.2f} ulps, stdev {:.2f} ulps".format(
statistics.mean(to_away_errors),
statistics.stdev(to_away_errors)))
ax1 = plt.subplot(2, 1, 1)
plt.hist(to_even_errors, bins=np.arange(-7, 17, 0.5))
ax2 = plt.subplot(2, 1, 2)
plt.hist(to_away_errors, bins=np.arange(-7, 17, 0.5))
ax1.set_title("Errors from ties-to-even (ulps)")
ax2.set_title("Errors from ties-away-from-zero (ulps)")
ax1.xaxis.set_visible(False)
plt.show()
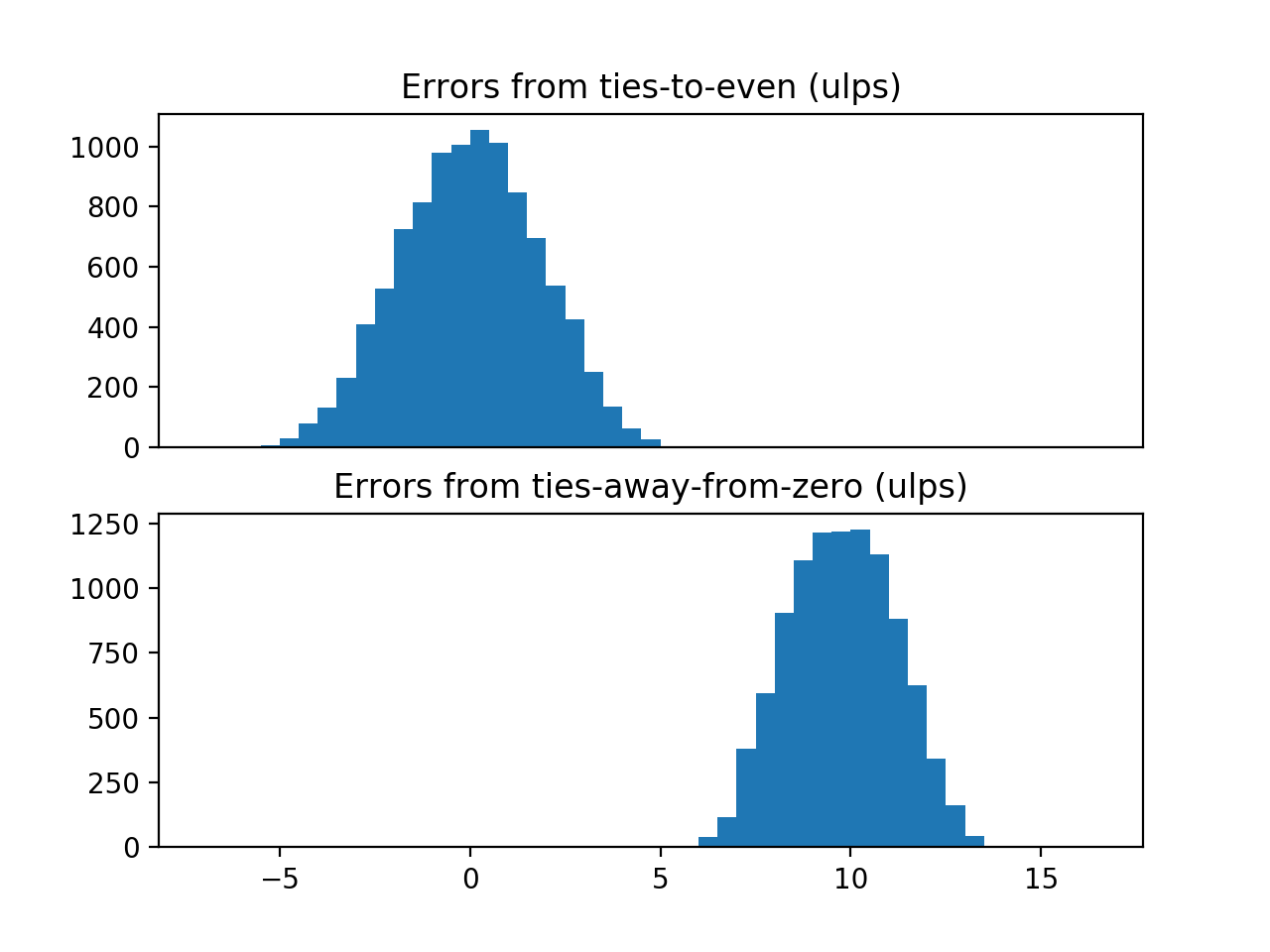
When I run the above function on my machine, I see:
Errors from ties-to-even: mean 0.00 ulps, stdev 1.81 ulps
Errors from ties-away-from-zero: mean 9.76 ulps, stdev 1.40 ulps
and I get the following plot:
![histograms of errors from the two rounding methods]()
I was planning to go one step further and perform a statistical test for bias on the two samples, but the bias from the ties-away-from-zero method is so marked that that looks unnecessary. Interestingly, while the ties-away-from-zero method gives poorer result, it does give a smaller spread of errors.
0.0through0.9, four have been rounded down, five have been rounded up, and one has remained unchanged. – Instrumentation1.0. Addepsilon/2, subtractepsilon/2, repeat. Mathematically, no matter how often you repeat, the result should be1.0. With half-way-up rounding, you'll slowly creep towards2.0. – Skeen