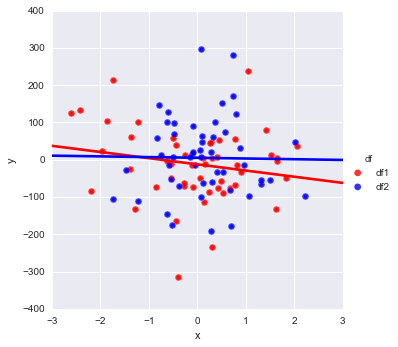
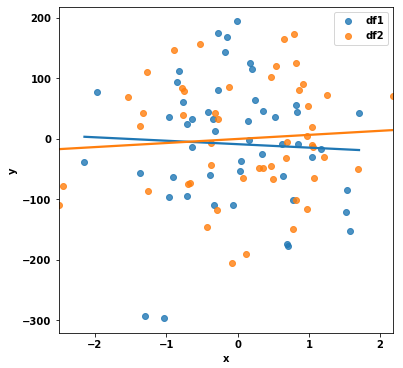
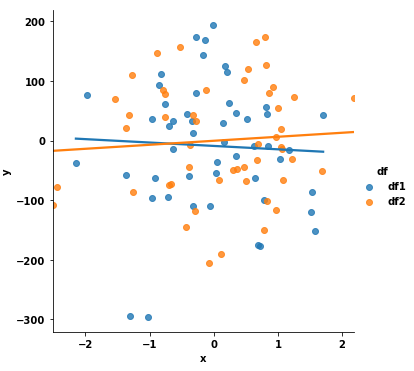
Given the following:
import numpy as np
import pandas as pd
import seaborn as sns
np.random.seed(365)
x1 = np.random.randn(50)
y1 = np.random.randn(50) * 100
x2 = np.random.randn(50)
y2 = np.random.randn(50) * 100
df1 = pd.DataFrame({'x1':x1, 'y1': y1})
df2 = pd.DataFrame({'x2':x2, 'y2': y2})
sns.lmplot('x1', 'y1', df1, fit_reg=True, ci = None)
sns.lmplot('x2', 'y2', df2, fit_reg=True, ci = None)
This will create 2 separate plots. How can I add the data from df2 onto the SAME graph? All the seaborn examples I have found online seem to focus on how you can create adjacent graphs (say, via the 'hue' and 'col_wrap' options). Also, I prefer not to use the dataset examples where an additional column might be present as this does not have a natural meaning in the project I am working on.
If there is a mixture of matplotlib/seaborn functions that are required to achieve this, I would be grateful if someone could help illustrate.