The data looks like this -
+-----------+-----------+-----------------------------+
| id| point| data|
+-----------------------------------------------------+
| abc| 6|{"key1":"124", "key2": "345"}|
| dfl| 7|{"key1":"777", "key2": "888"}|
| 4bd| 6|{"key1":"111", "key2": "788"}|
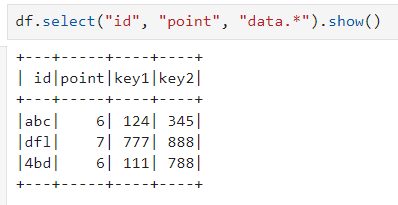
I am trying to break it into the following format.
+-----------+-----------+-----------+-----------+
| id| point| key1| key2|
+------------------------------------------------
| abc| 6| 124| 345|
| dfl| 7| 777| 888|
| 4bd| 6| 111| 788|
The explode function explodes the dataframe into multiple rows. But that is not the desired solution.
Note: This solution does not answers my questions. PySpark "explode" dict in column
schema = spark.read.json(df.rdd.map(lambda row: row.data)).schema– Salver