(2022) Use Server Side Rendering if possible, and generate URLs with Pushstate
Google can and will run JavaScript now so it is very possible to build a site using only JavaScript provided you create a sensible URL structure. However, pagespeed has become a progressively more important ranking factor and typically pages built clientside perform poorly on initial render.
Serverside rendering (SSR) can help by allowing your pages to be pre-generated on the server. Your html containst the div that will be used as the page root, but this is not an empty div, it contains the html that the JavaScript would have generated if it were allowed to run.
The client downloads the HTML and renders it giving a very fast initial load, then it executes the JavaScript replacing the content of the root div with generated content in a process known as hydration.
Many newer frameworks come with SSR built in, notably NextJS.
(2015) Use PushState and Precomposition
The current (2015) way to do this is using the JavaScript pushState method.
PushState changes the URL in the top browser bar without reloading the page. Say you have a page containing tabs. The tabs hide and show content, and the content is inserted dynamically, either using AJAX or by simply setting display:none and display:block to hide and show the correct tab content.
When the tabs are clicked, use pushState to update the URL in the address bar. When the page is rendered, use the value in the address bar to determine which tab to show. Angular routing will do this for you automatically.
Precomposition
There are two ways to hit a PushState Single Page App (SPA)
- Via PushState, where the user clicks a PushState link and the content is AJAXed in.
- By hitting the URL directly.
The initial hit on the site will involve hitting the URL directly. Subsequent hits will simply AJAX in content as the PushState updates the URL.
Crawlers harvest links from a page then add them to a queue for later processing. This means that for a crawler, every hit on the server is a direct hit, they don't navigate via Pushstate.
Precomposition bundles the initial payload into the first response from the server, possibly as a JSON object. This allows the Search Engine to render the page without executing the AJAX call.
There is some evidence to suggest that Google might not execute AJAX requests. More on this here:
https://web.archive.org/web/20160318211223/http://www.analog-ni.co/precomposing-a-spa-may-become-the-holy-grail-to-seo
Search Engines can read and execute JavaScript
Google has been able to parse JavaScript for some time now, it's why they originally developed Chrome, to act as a full featured headless browser for the Google spider. If a link has a valid href attribute, the new URL can be indexed. There's nothing more to do.
If clicking a link in addition triggers a pushState call, the site can be navigated by the user via PushState.
Search Engine Support for PushState URLs
PushState is currently supported by Google and Bing.
Google
Here's Matt Cutts responding to Paul Irish's question about PushState for SEO:
http://youtu.be/yiAF9VdvRPw
Here is Google announcing full JavaScript support for the spider:
http://googlewebmastercentral.blogspot.de/2014/05/understanding-web-pages-better.html
The upshot is that Google supports PushState and will index PushState URLs.
See also Google webmaster tools' fetch as Googlebot. You will see your JavaScript (including Angular) is executed.
Bing
Here is Bing's announcement of support for pretty PushState URLs dated March 2013:
http://blogs.bing.com/webmaster/2013/03/21/search-engine-optimization-best-practices-for-ajax-urls/
Don't use HashBangs #!
Hashbang URLs were an ugly stopgap requiring the developer to provide a pre-rendered version of the site at a special location. They still work, but you don't need to use them.
Hashbang URLs look like this:
domain.example/#!path/to/resource
This would be paired with a metatag like this:
<meta name="fragment" content="!">
Google will not index them in this form, but will instead pull a static version of the site from the escaped_fragments URL and index that.
Pushstate URLs look like any ordinary URL:
domain.example/path/to/resource
The difference is that Angular handles them for you by intercepting the change to document.location dealing with it in JavaScript.
If you want to use PushState URLs (and you probably do) take out all the old hash style URLs and metatags and simply enable HTML5 mode in your config block.
Testing your site
Google Webmaster tools now contains a tool which will allow you to fetch a URL as Google, and render JavaScript as Google renders it.
https://www.google.com/webmasters/tools/googlebot-fetch
Generating PushState URLs in Angular
To generate real URLs in Angular, rather than # prefixed ones, set HTML5 mode on your $locationProvider object.
$locationProvider.html5Mode(true);
Server Side
Since you are using real URLs, you will need to ensure the same template (plus some precomposed content) gets shipped by your server for all valid URLs. How you do this will vary depending on your server architecture.
Sitemap
Your app may use unusual forms of navigation, for example hover or scroll. To ensure Google is able to drive your app, I would probably suggest creating a sitemap, a simple list of all the URLs your app responds to. You can place this at the default location (/sitemap or /sitemap.xml), or tell Google about it using webmaster tools.
It's a good idea to have a sitemap anyway.
Browser support
Pushstate works in IE10. In older browsers, Angular will automatically fall back to hash style URLs
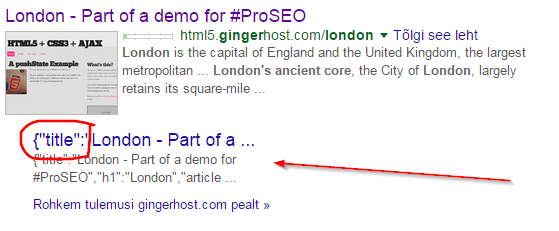
A demo page
The following content is rendered using a pushstate URL with precomposition:
http://html5.gingerhost.com/london
As can be verified, at this link, the content is indexed and is appearing in Google.
Serving 404 and 301 Header status codes
Because the search engine will always hit your server for every request, you can serve header status codes from your server and expect Google to see them.
{kind=link}