CLOSED FORM (TIKHONOV) VERSUS GRADIENT DESCENT
Hi! nice explanations for the intuitive and top-notch mathematical approaches there. I just wanted to add some specificities that, where not "problem-solving", may definitely help to speed up and give some consistency to the process of finding a good regularization hyperparameter.
I assume that you are talking about the L2 (a.k. "weight decay") regularization, linearly weighted by the lambda term, and that you are optimizing the weights of your model either with the closed-form Tikhonov equation (highly recommended for low-dimensional linear regression models), or with some variant of gradient descent with backpropagation. And that in this context, you want to choose the value for lambda that provides best generalization ability.
CLOSED FORM (TIKHONOV)
If you are able to go the Tikhonov way with your model (Andrew Ng says under 10k dimensions, but this suggestion is at least 5 years old) Wikipedia - determination of the Tikhonov factor offers an interesting closed-form solution, which has been proven to provide the optimal value. But this solution probably raises some kind of implementation issues (time complexity/numerical stability) I'm not aware of, because there is no mainstream algorithm to perform it. This 2016 paper looks very promising though and may be worth a try if you really have to optimize your linear model to its best.
- For a quicker prototype implementation, this 2015 Python package seems to deal with it iteratively, you could let it optimize and then extract the final value for the lambda:
In this new innovative method, we have derived an iterative approach to solving the general Tikhonov regularization problem, which converges to the noiseless solution, does not depend strongly on the choice of lambda, and yet still avoids the inversion problem.
And from the GitHub README of the project:
InverseProblem.invert(A, be, k, l) #this will invert your A matrix, where be is noisy be, k is the no. of iterations, and lambda is your dampening effect (best set to 1)
GRADIENT DESCENT
All links of this part are from Michael Nielsen's amazing online book "Neural Networks and Deep Learning", recommended reading!
For this approach it seems to be even less to be said: the cost function is usually non-convex, the optimization is performed numerically and the performance of the model is measured by some form of cross validation (see Overfitting and Regularization and why does regularization help reduce overfitting if you haven't had enough of that). But even when cross-validating, Nielsen suggests something: you may want to take a look at this detailed explanation on how does the L2 regularization provide a weight decaying effect, but the summary is that it is inversely proportional to the number of samples n, so when calculating the gradient descent equation with the L2 term,
just use backpropagation, as usual, and then add (λ/n)*w to the partial derivative of all the weight terms.
And his conclusion is that, when wanting a similar regularization effect with a different number of samples, lambda has to be changed proportionally:
we need to modify the regularization parameter. The reason is because the size n of the training set has changed from n=1000 to n=50000, and this changes the weight decay factor 1−learning_rate*(λ/n). If we continued to use λ=0.1 that would mean much less weight decay, and thus much less of a regularization effect. We compensate by changing to λ=5.0.
This is only useful when applying the same model to different amounts of the same data, but I think it opens up the door for some intuition on how it should work, and, more importantly, speed up the hyperparametrization process by allowing you to finetune lambda in smaller subsets and then scale up.
For choosing the exact values, he suggests in his conclusions on how to choose a neural network's hyperparameters the purely empirical approach: start with 1 and then progressively multiply÷ by 10 until you find the proper order of magnitude, and then do a local search within that region. In the comments of this SE related question, the user Brian Borchers suggests also a very well known method that may be useful for that local search:
- Take small subsets of the training and validation sets (to be able to make many of them in a reasonable amount of time)
- Starting with
λ=0 and increasing by small amounts within some region, perform a quick training&validation of the model and plot both loss functions
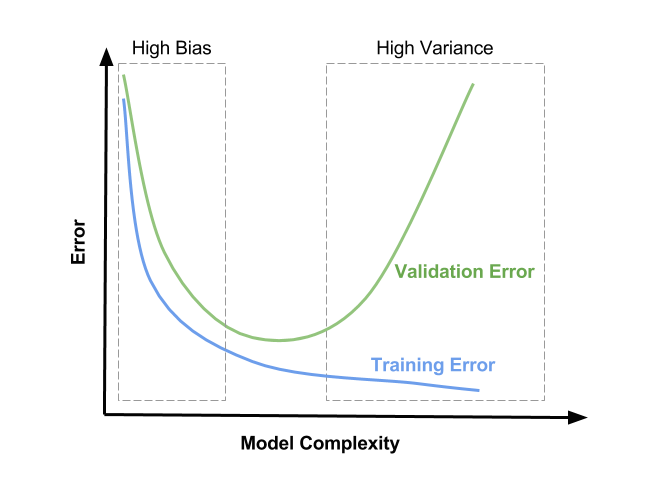
- You will observe three things:
- The CV loss function will be consistently higher than the training one, since your model is optimized for the training data exclusively (EDIT: After some time I've seen a MNIST case where adding L2 helped the CV loss decrease faster than the training one until convergence. Probably due to the ridiculous consistency of the data and a suboptimal hyperparametrization though).
- The training loss function will have its minimum for
λ=0, and then increase with the regularization, since preventing the model from optimally fitting the training data is exactly what regularization does.
- The CV loss function will start high at
λ=0, then decrease, and then start increasing again at some point (EDIT: this assuming that the setup is able to overfit for λ=0, i.e. the model has enough power and no other regularization means are heavily applied).
- The optimal value for
λ will be probably somewhere around the minimum of the CV loss function, it also may depend a little on how does the training loss function look like. See the picture for a possible (but not the only one) representation of this: instead of "model complexity" you should interpret the x axis as λ being zero at the right and increasing towards the left.
![L2 diagnostics: instead of "model complexity" one should interpret the x axis **as λ being zero at the right and increasing towards the left]()
Hope this helps! Cheers,
Andres