I want to merge two dictionaries into a new dictionary.
x = {'a': 1, 'b': 2}
y = {'b': 3, 'c': 4}
z = merge(x, y)
>>> z
{'a': 1, 'b': 3, 'c': 4}
Whenever a key k is present in both dictionaries, only the value y[k] should be kept.
I want to merge two dictionaries into a new dictionary.
x = {'a': 1, 'b': 2}
y = {'b': 3, 'c': 4}
z = merge(x, y)
>>> z
{'a': 1, 'b': 3, 'c': 4}
Whenever a key k is present in both dictionaries, only the value y[k] should be kept.
For dictionaries x and y, their shallowly-merged dictionary z takes values from y, replacing those from x.
In Python 3.9.0 or greater (released 17 October 2020, PEP-584, discussed here):
z = x | y
In Python 3.5 or greater:
z = {**x, **y}
In Python 2, (or 3.4 or lower) write a function:
def merge_two_dicts(x, y):
z = x.copy() # start with keys and values of x
z.update(y) # modifies z with keys and values of y
return z
and now:
z = merge_two_dicts(x, y)
Say you have two dictionaries and you want to merge them into a new dictionary without altering the original dictionaries:
x = {'a': 1, 'b': 2}
y = {'b': 3, 'c': 4}
The desired result is to get a new dictionary (z) with the values merged, and the second dictionary's values overwriting those from the first.
>>> z
{'a': 1, 'b': 3, 'c': 4}
A new syntax for this, proposed in PEP 448 and available as of Python 3.5, is
z = {**x, **y}
And it is indeed a single expression.
Note that we can merge in with literal notation as well:
z = {**x, 'foo': 1, 'bar': 2, **y}
and now:
>>> z
{'a': 1, 'b': 3, 'foo': 1, 'bar': 2, 'c': 4}
It is now showing as implemented in the release schedule for 3.5, PEP 478, and it has now made its way into the What's New in Python 3.5 document.
However, since many organizations are still on Python 2, you may wish to do this in a backward-compatible way. The classically Pythonic way, available in Python 2 and Python 3.0-3.4, is to do this as a two-step process:
z = x.copy()
z.update(y) # which returns None since it mutates z
In both approaches, y will come second and its values will replace x's values, thus b will point to 3 in our final result.
If you are not yet on Python 3.5 or need to write backward-compatible code, and you want this in a single expression, the most performant while the correct approach is to put it in a function:
def merge_two_dicts(x, y):
"""Given two dictionaries, merge them into a new dict as a shallow copy."""
z = x.copy()
z.update(y)
return z
and then you have a single expression:
z = merge_two_dicts(x, y)
You can also make a function to merge an arbitrary number of dictionaries, from zero to a very large number:
def merge_dicts(*dict_args):
"""
Given any number of dictionaries, shallow copy and merge into a new dict,
precedence goes to key-value pairs in latter dictionaries.
"""
result = {}
for dictionary in dict_args:
result.update(dictionary)
return result
This function will work in Python 2 and 3 for all dictionaries. e.g. given dictionaries a to g:
z = merge_dicts(a, b, c, d, e, f, g)
and key-value pairs in g will take precedence over dictionaries a to f, and so on.
Don't use what you see in the formerly accepted answer:
z = dict(x.items() + y.items())
In Python 2, you create two lists in memory for each dict, create a third list in memory with length equal to the length of the first two put together, and then discard all three lists to create the dict. In Python 3, this will fail because you're adding two dict_items objects together, not two lists -
>>> c = dict(a.items() + b.items())
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for +: 'dict_items' and 'dict_items'
and you would have to explicitly create them as lists, e.g. z = dict(list(x.items()) + list(y.items())). This is a waste of resources and computation power.
Similarly, taking the union of items() in Python 3 (viewitems() in Python 2.7) will also fail when values are unhashable objects (like lists, for example). Even if your values are hashable, since sets are semantically unordered, the behavior is undefined in regards to precedence. So don't do this:
>>> c = dict(a.items() | b.items())
This example demonstrates what happens when values are unhashable:
>>> x = {'a': []}
>>> y = {'b': []}
>>> dict(x.items() | y.items())
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
Here's an example where y should have precedence, but instead the value from x is retained due to the arbitrary order of sets:
>>> x = {'a': 2}
>>> y = {'a': 1}
>>> dict(x.items() | y.items())
{'a': 2}
Another hack you should not use:
z = dict(x, **y)
This uses the dict constructor and is very fast and memory-efficient (even slightly more so than our two-step process) but unless you know precisely what is happening here (that is, the second dict is being passed as keyword arguments to the dict constructor), it's difficult to read, it's not the intended usage, and so it is not Pythonic.
Here's an example of the usage being remediated in django.
Dictionaries are intended to take hashable keys (e.g. frozensets or tuples), but this method fails in Python 3 when keys are not strings.
>>> c = dict(a, **b)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: keyword arguments must be strings
From the mailing list, Guido van Rossum, the creator of the language, wrote:
I am fine with declaring dict({}, **{1:3}) illegal, since after all it is abuse of the ** mechanism.
and
Apparently dict(x, **y) is going around as "cool hack" for "call x.update(y) and return x". Personally, I find it more despicable than cool.
It is my understanding (as well as the understanding of the creator of the language) that the intended usage for dict(**y) is for creating dictionaries for readability purposes, e.g.:
dict(a=1, b=10, c=11)
instead of
{'a': 1, 'b': 10, 'c': 11}
Despite what Guido says,
dict(x, **y)is in line with the dict specification, which btw. works for both Python 2 and 3. The fact that this only works for string keys is a direct consequence of how keyword parameters work and not a short-coming of dict. Nor is using the ** operator in this place an abuse of the mechanism, in fact, ** was designed precisely to pass dictionaries as keywords.
Again, it doesn't work for 3 when keys are not strings. The implicit calling contract is that namespaces take ordinary dictionaries, while users must only pass keyword arguments that are strings. All other callables enforced it. dict broke this consistency in Python 2:
>>> foo(**{('a', 'b'): None})
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: foo() keywords must be strings
>>> dict(**{('a', 'b'): None})
{('a', 'b'): None}
This inconsistency was bad given other implementations of Python (PyPy, Jython, IronPython). Thus it was fixed in Python 3, as this usage could be a breaking change.
I submit to you that it is malicious incompetence to intentionally write code that only works in one version of a language or that only works given certain arbitrary constraints.
More comments:
dict(x.items() + y.items())is still the most readable solution for Python 2. Readability counts.
My response: merge_two_dicts(x, y) actually seems much clearer to me, if we're actually concerned about readability. And it is not forward compatible, as Python 2 is increasingly deprecated.
{**x, **y}does not seem to handle nested dictionaries. the contents of nested keys are simply overwritten, not merged [...] I ended up being burnt by these answers that do not merge recursively and I was surprised no one mentioned it. In my interpretation of the word "merging" these answers describe "updating one dict with another", and not merging.
Yes. I must refer you back to the question, which is asking for a shallow merge of two dictionaries, with the first's values being overwritten by the second's - in a single expression.
Assuming two dictionaries of dictionaries, one might recursively merge them in a single function, but you should be careful not to modify the dictionaries from either source, and the surest way to avoid that is to make a copy when assigning values. As keys must be hashable and are usually therefore immutable, it is pointless to copy them:
from copy import deepcopy
def dict_of_dicts_merge(x, y):
z = {}
overlapping_keys = x.keys() & y.keys()
for key in overlapping_keys:
z[key] = dict_of_dicts_merge(x[key], y[key])
for key in x.keys() - overlapping_keys:
z[key] = deepcopy(x[key])
for key in y.keys() - overlapping_keys:
z[key] = deepcopy(y[key])
return z
Usage:
>>> x = {'a':{1:{}}, 'b': {2:{}}}
>>> y = {'b':{10:{}}, 'c': {11:{}}}
>>> dict_of_dicts_merge(x, y)
{'b': {2: {}, 10: {}}, 'a': {1: {}}, 'c': {11: {}}}
Coming up with contingencies for other value types is far beyond the scope of this question, so I will point you at my answer to the canonical question on a "Dictionaries of dictionaries merge".
These approaches are less performant, but they will provide correct behavior.
They will be much less performant than copy and update or the new unpacking because they iterate through each key-value pair at a higher level of abstraction, but they do respect the order of precedence (latter dictionaries have precedence)
You can also chain the dictionaries manually inside a dict comprehension:
{k: v for d in dicts for k, v in d.items()} # iteritems in Python 2.7
or in Python 2.6 (and perhaps as early as 2.4 when generator expressions were introduced):
dict((k, v) for d in dicts for k, v in d.items()) # iteritems in Python 2
itertools.chain will chain the iterators over the key-value pairs in the correct order:
from itertools import chain
z = dict(chain(x.items(), y.items())) # iteritems in Python 2
I'm only going to do the performance analysis of the usages known to behave correctly. (Self-contained so you can copy and paste yourself.)
from timeit import repeat
from itertools import chain
x = dict.fromkeys('abcdefg')
y = dict.fromkeys('efghijk')
def merge_two_dicts(x, y):
z = x.copy()
z.update(y)
return z
min(repeat(lambda: {**x, **y}))
min(repeat(lambda: merge_two_dicts(x, y)))
min(repeat(lambda: {k: v for d in (x, y) for k, v in d.items()}))
min(repeat(lambda: dict(chain(x.items(), y.items()))))
min(repeat(lambda: dict(item for d in (x, y) for item in d.items())))
In Python 3.8.1, NixOS:
>>> min(repeat(lambda: {**x, **y}))
1.0804965235292912
>>> min(repeat(lambda: merge_two_dicts(x, y)))
1.636518670246005
>>> min(repeat(lambda: {k: v for d in (x, y) for k, v in d.items()}))
3.1779992282390594
>>> min(repeat(lambda: dict(chain(x.items(), y.items()))))
2.740647904574871
>>> min(repeat(lambda: dict(item for d in (x, y) for item in d.items())))
4.266070580109954
$ uname -a
Linux nixos 4.19.113 #1-NixOS SMP Wed Mar 25 07:06:15 UTC 2020 x86_64 GNU/Linux
{**{(0, 1):2}} -> {(0, 1): 2} –
Aristaeus dict1 and dict2 have some keys in common, {**dict1, **dict2} raises TypeError: type object got multiple values for keyword argument common_key_name. I guess I'll stay with {dict1, **dict2} and string keys. –
Childbirth x and y did you use in the benchmarks? And I find dict((k, v) ... for k, v in d.items()) somewhat clumsy and artificially inefficient. No need to unpack and repack every item. I think it should be dict(item ... for item in d.items()). –
Spec dict((k, v) ...) a bit higher in your post, btw. And I just thought of another solution that I think hasn't been mentioned yet: dict([*x.items(), *y.items()]). It's a bit slower for me than the chain one. –
Spec dict(**y) is for creating dictionaries for readability purposes". I would argue that it's also to make the code less error prone, because dict(a=17, b=19, a=23) would fail with "SyntaxError: keyword argument repeated", while {"a": 17, "b": 19, "a": 23} would not (with 23 overwriting 17) and your accidental double key "a" would've gone unnoticed. Of course, if you want to allow double keys (I cannot see why, though), then {...} syntax is the way to go. Many linters, of course, warn of double keys. –
Belfort dict definition]". Of course you'd want proper updates between multiple dictionaries, but I don't see the purpose inside a single definition (like two "a" keys in my example). –
Belfort x | y to be like {**y, **x}, not {**x, **y} –
Sargassum x | y is confusing to read, as @Sargassum explained it is counter-intuitive. I prefer x |= y which is going to mutate x with new values from y and reads far clearer! –
Placement dict_of_dicts_merge() function took 29 times longer than {**x, **y}. sigh. –
Cluny dict_of_dicts_merge is slower because it's a recursive deep copy, so the comparison is a bit unfair. –
Aristaeus In your case, you can do:
z = dict(list(x.items()) + list(y.items()))
This will, as you want it, put the final dict in z, and make the value for key b be properly overridden by the second (y) dict's value:
>>> x = {'a': 1, 'b': 2}
>>> y = {'b': 10, 'c': 11}
>>> z = dict(list(x.items()) + list(y.items()))
>>> z
{'a': 1, 'c': 11, 'b': 10}
If you use Python 2, you can even remove the list() calls. To create z:
>>> z = dict(x.items() + y.items())
>>> z
{'a': 1, 'c': 11, 'b': 10}
If you use Python version 3.9.0a4 or greater, you can directly use:
>>> x = {'a': 1, 'b': 2}
>>> y = {'b': 10, 'c': 11}
>>> z = x | y
>>> z
{'a': 1, 'c': 11, 'b': 10}
An alternative:
z = x.copy()
z.update(y)
Update is not one of the "core" functions that people tend to use a lot. –
Kanarese (lambda z: z.update(y) or z)(x.copy()) :P –
Banquer Indeed pythonic! –
Procter Another, more concise, option:
z = dict(x, **y)
Note: this has become a popular answer, but it is important to point out that if y has any non-string keys, the fact that this works at all is an abuse of a CPython implementation detail, and it does not work in Python 3, or in PyPy, IronPython, or Jython. Also, Guido is not a fan. So I can't recommend this technique for forward-compatible or cross-implementation portable code, which really means it should be avoided entirely.
This probably won't be a popular answer, but you almost certainly do not want to do this. If you want a copy that's a merge, then use copy (or deepcopy, depending on what you want) and then update. The two lines of code are much more readable - more Pythonic - than the single line creation with .items() + .items(). Explicit is better than implicit.
In addition, when you use .items() (pre Python 3.0), you're creating a new list that contains the items from the dict. If your dictionaries are large, then that is quite a lot of overhead (two large lists that will be thrown away as soon as the merged dict is created). update() can work more efficiently, because it can run through the second dict item-by-item.
In terms of time:
>>> timeit.Timer("dict(x, **y)", "x = dict(zip(range(1000), range(1000)))\ny=dict(zip(range(1000,2000), range(1000,2000)))").timeit(100000)
15.52571702003479
>>> timeit.Timer("temp = x.copy()\ntemp.update(y)", "x = dict(zip(range(1000), range(1000)))\ny=dict(zip(range(1000,2000), range(1000,2000)))").timeit(100000)
15.694622993469238
>>> timeit.Timer("dict(x.items() + y.items())", "x = dict(zip(range(1000), range(1000)))\ny=dict(zip(range(1000,2000), range(1000,2000)))").timeit(100000)
41.484580039978027
IMO the tiny slowdown between the first two is worth it for the readability. In addition, keyword arguments for dictionary creation was only added in Python 2.3, whereas copy() and update() will work in older versions.
In a follow-up answer, you asked about the relative performance of these two alternatives:
z1 = dict(x.items() + y.items())
z2 = dict(x, **y)
On my machine, at least (a fairly ordinary x86_64 running Python 2.5.2), alternative z2 is not only shorter and simpler but also significantly faster. You can verify this for yourself using the timeit module that comes with Python.
Example 1: identical dictionaries mapping 20 consecutive integers to themselves:
% python -m timeit -s 'x=y=dict((i,i) for i in range(20))' 'z1=dict(x.items() + y.items())'
100000 loops, best of 3: 5.67 usec per loop
% python -m timeit -s 'x=y=dict((i,i) for i in range(20))' 'z2=dict(x, **y)'
100000 loops, best of 3: 1.53 usec per loop
z2 wins by a factor of 3.5 or so. Different dictionaries seem to yield quite different results, but z2 always seems to come out ahead. (If you get inconsistent results for the same test, try passing in -r with a number larger than the default 3.)
Example 2: non-overlapping dictionaries mapping 252 short strings to integers and vice versa:
% python -m timeit -s 'from htmlentitydefs import codepoint2name as x, name2codepoint as y' 'z1=dict(x.items() + y.items())'
1000 loops, best of 3: 260 usec per loop
% python -m timeit -s 'from htmlentitydefs import codepoint2name as x, name2codepoint as y' 'z2=dict(x, **y)'
10000 loops, best of 3: 26.9 usec per loop
z2 wins by about a factor of 10. That's a pretty big win in my book!
After comparing those two, I wondered if z1's poor performance could be attributed to the overhead of constructing the two item lists, which in turn led me to wonder if this variation might work better:
from itertools import chain
z3 = dict(chain(x.iteritems(), y.iteritems()))
A few quick tests, e.g.
% python -m timeit -s 'from itertools import chain; from htmlentitydefs import codepoint2name as x, name2codepoint as y' 'z3=dict(chain(x.iteritems(), y.iteritems()))'
10000 loops, best of 3: 66 usec per loop
lead me to conclude that z3 is somewhat faster than z1, but not nearly as fast as z2. Definitely not worth all the extra typing.
This discussion is still missing something important, which is a performance comparison of these alternatives with the "obvious" way of merging two lists: using the update method. To try to keep things on an equal footing with the expressions, none of which modify x or y, I'm going to make a copy of x instead of modifying it in-place, as follows:
z0 = dict(x)
z0.update(y)
A typical result:
% python -m timeit -s 'from htmlentitydefs import codepoint2name as x, name2codepoint as y' 'z0=dict(x); z0.update(y)'
10000 loops, best of 3: 26.9 usec per loop
In other words, z0 and z2 seem to have essentially identical performance. Do you think this might be a coincidence? I don't....
In fact, I'd go so far as to claim that it's impossible for pure Python code to do any better than this. And if you can do significantly better in a C extension module, I imagine the Python folks might well be interested in incorporating your code (or a variation on your approach) into the Python core. Python uses dict in lots of places; optimizing its operations is a big deal.
You could also write this as
z0 = x.copy()
z0.update(y)
as Tony does, but (not surprisingly) the difference in notation turns out not to have any measurable effect on performance. Use whichever looks right to you. Of course, he's absolutely correct to point out that the two-statement version is much easier to understand.
items() is not catenable, and iteritems does not exist. –
Viviparous In Python 3.0 and later, you can use collections.ChainMap which groups multiple dicts or other mappings together to create a single, updateable view:
>>> from collections import ChainMap
>>> x = {'a':1, 'b': 2}
>>> y = {'b':10, 'c': 11}
>>> z = dict(ChainMap({}, y, x))
>>> for k, v in z.items():
print(k, '-->', v)
a --> 1
b --> 10
c --> 11
Update for Python 3.5 and later: You can use PEP 448 extended dictionary packing and unpacking. This is fast and easy:
>>> x = {'a':1, 'b': 2}
>>> y = {'b':10, 'c': 11}
>>> {**x, **y}
{'a': 1, 'b': 10, 'c': 11}
Update for Python 3.9 and later: You can use the PEP 584 union operator:
>>> x = {'a':1, 'b': 2}
>>> y = {'b':10, 'c': 11}
>>> x | y
{'a': 1, 'b': 10, 'c': 11}
del on say a ChainMap c will delete the first mapping of that key. –
Unseam dict to avoid that, i.e.: dict(ChainMap({}, y, x)) –
Hecatomb ChainMap in the most reasonable way, thank you for it! –
Bainite I wanted something similar, but with the ability to specify how the values on duplicate keys were merged, so I hacked this out (but did not heavily test it). Obviously this is not a single expression, but it is a single function call.
def merge(d1, d2, merge_fn=lambda x,y:y):
"""
Merges two dictionaries, non-destructively, combining
values on duplicate keys as defined by the optional merge
function. The default behavior replaces the values in d1
with corresponding values in d2. (There is no other generally
applicable merge strategy, but often you'll have homogeneous
types in your dicts, so specifying a merge technique can be
valuable.)
Examples:
>>> d1
{'a': 1, 'c': 3, 'b': 2}
>>> merge(d1, d1)
{'a': 1, 'c': 3, 'b': 2}
>>> merge(d1, d1, lambda x,y: x+y)
{'a': 2, 'c': 6, 'b': 4}
"""
result = dict(d1)
for k,v in d2.iteritems():
if k in result:
result[k] = merge_fn(result[k], v)
else:
result[k] = v
return result
def deepupdate(original, update):
"""
Recursively update a dict.
Subdict's won't be overwritten but also updated.
"""
for key, value in original.iteritems():
if key not in update:
update[key] = value
elif isinstance(value, dict):
deepupdate(value, update[key])
return updateDemonstration:
pluto_original = {
'name': 'Pluto',
'details': {
'tail': True,
'color': 'orange'
}
}
pluto_update = {
'name': 'Pluutoo',
'details': {
'color': 'blue'
}
}
print deepupdate(pluto_original, pluto_update)Outputs:
{
'name': 'Pluutoo',
'details': {
'color': 'blue',
'tail': True
}
}Thanks rednaw for edits.
I benchmarked the suggested with perfplot and found that
x | y # Python 3.9+
is the fastest solution together with the good old
{**x, **y}
and
temp = x.copy()
temp.update(y)
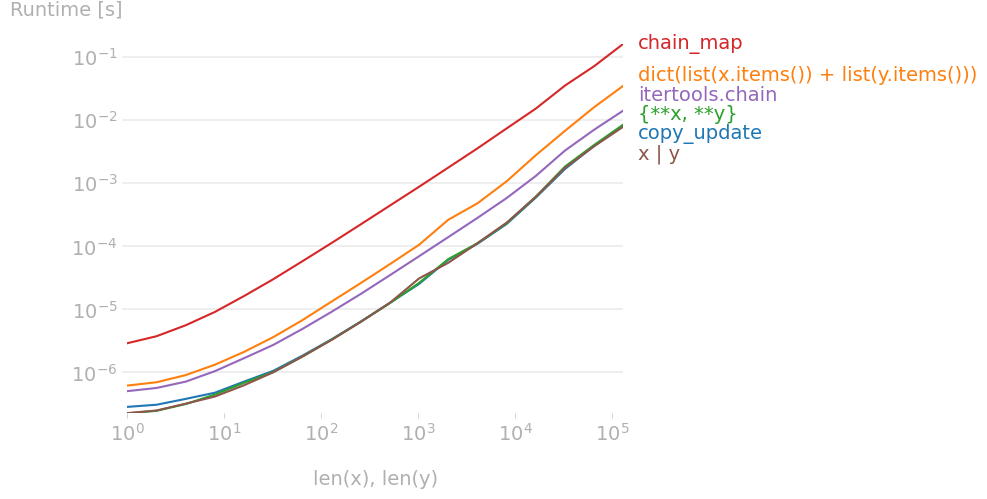
Code to reproduce the plot:
from collections import ChainMap
from itertools import chain
import perfplot
def setup(n):
x = dict(zip(range(n), range(n)))
y = dict(zip(range(n, 2 * n), range(n, 2 * n)))
return x, y
def copy_update(x, y):
temp = x.copy()
temp.update(y)
return temp
def add_items(x, y):
return dict(list(x.items()) + list(y.items()))
def curly_star(x, y):
return {**x, **y}
def chain_map(x, y):
return dict(ChainMap({}, y, x))
def itertools_chain(x, y):
return dict(chain(x.items(), y.items()))
def python39_concat(x, y):
return x | y
b = perfplot.bench(
setup=setup,
kernels=[
copy_update,
add_items,
curly_star,
chain_map,
itertools_chain,
python39_concat,
],
labels=[
"copy_update",
"dict(list(x.items()) + list(y.items()))",
"{**x, **y}",
"chain_map",
"itertools.chain",
"x | y",
],
n_range=[2 ** k for k in range(18)],
xlabel="len(x), len(y)",
equality_check=None,
)
b.save("out.png")
b.show()
x_1 | x_2 | ... | x_n –
Mantoman Python 3.5 (PEP 448) allows a nicer syntax option:
x = {'a': 1, 'b': 1}
y = {'a': 2, 'c': 2}
final = {**x, **y}
final
# {'a': 2, 'b': 1, 'c': 2}
Or even
final = {'a': 1, 'b': 1, **x, **y}
In Python 3.9 you also use | and |= with the below example from PEP 584
d = {'spam': 1, 'eggs': 2, 'cheese': 3}
e = {'cheese': 'cheddar', 'aardvark': 'Ethel'}
d | e
# {'spam': 1, 'eggs': 2, 'cheese': 'cheddar', 'aardvark': 'Ethel'}
dict(x, **y)-solution? As you (@CarlMeyer) mentioned within the note of your own answer (https://mcmap.net/q/36055/-how-do-i-merge-two-dictionaries-in-a-single-expression-in-python) Guido considers that solution illegal. –
Internationale dict(x, **y) for the (very good) reason that it relies on y only having keys which are valid keyword argument names (unless you are using CPython 2.7, where the dict constructor cheats). This objection/restriction does not apply to PEP 448, which generalizes the ** unpacking syntax to dict literals. So this solution has the same concision as dict(x, **y), without the downside. –
Eagleeyed x = {'a':1, 'b': 2}
y = {'b':10, 'c': 11}
z = dict(x.items() + y.items())
print z
For items with keys in both dictionaries ('b'), you can control which one ends up in the output by putting that one last.
itertools.chain(x.items(), y.items()) could also be used. –
Foretopsail The best version I could think while not using copy would be:
from itertools import chain
x = {'a':1, 'b': 2}
y = {'b':10, 'c': 11}
dict(chain(x.iteritems(), y.iteritems()))
It's faster than dict(x.items() + y.items()) but not as fast as n = copy(a); n.update(b), at least on CPython. This version also works in Python 3 if you change iteritems() to items(), which is automatically done by the 2to3 tool.
Personally I like this version best because it describes fairly good what I want in a single functional syntax. The only minor problem is that it doesn't make completely obvious that values from y takes precedence over values from x, but I don't believe it's difficult to figure that out.
While the question has already been answered several times, this simple solution to the problem has not been listed yet.
x = {'a':1, 'b': 2}
y = {'b':10, 'c': 11}
z4 = {}
z4.update(x)
z4.update(y)
It is as fast as z0 and the evil z2 mentioned above, but easy to understand and change.
z4 = {} and change the next line to z4 = x.copy() -- better than just good code doesn't do unnecessary things (which makes it even more readable and maintainable). –
Heist def dict_merge(a, b):
c = a.copy()
c.update(b)
return c
new = dict_merge(old, extras)
Among such shady and dubious answers, this shining example is the one and only good way to merge dicts in Python, endorsed by dictator for life Guido van Rossum himself! Someone else suggested half of this, but did not put it in a function.
print dict_merge(
{'color':'red', 'model':'Mini'},
{'model':'Ferrari', 'owner':'Carl'})
gives:
{'color': 'red', 'owner': 'Carl', 'model': 'Ferrari'}
Be Pythonic. Use a comprehension:
z={k: v for d in [x,y] for k, v in d.items()}
>>> print z
{'a': 1, 'c': 11, 'b': 10}
If you think lambdas are evil then read no further. As requested, you can write the fast and memory-efficient solution with one expression:
x = {'a':1, 'b':2}
y = {'b':10, 'c':11}
z = (lambda a, b: (lambda a_copy: a_copy.update(b) or a_copy)(a.copy()))(x, y)
print z
{'a': 1, 'c': 11, 'b': 10}
print x
{'a': 1, 'b': 2}
As suggested above, using two lines or writing a function is probably a better way to go.
In python3, the items method no longer returns a list, but rather a view, which acts like a set. In this case you'll need to take the set union since concatenating with + won't work:
dict(x.items() | y.items())
For python3-like behavior in version 2.7, the viewitems method should work in place of items:
dict(x.viewitems() | y.viewitems())
I prefer this notation anyways since it seems more natural to think of it as a set union operation rather than concatenation (as the title shows).
Edit:
A couple more points for python 3. First, note that the dict(x, **y) trick won't work in python 3 unless the keys in y are strings.
Also, Raymond Hettinger's Chainmap answer is pretty elegant, since it can take an arbitrary number of dicts as arguments, but from the docs it looks like it sequentially looks through a list of all the dicts for each lookup:
Lookups search the underlying mappings successively until a key is found.
This can slow you down if you have a lot of lookups in your application:
In [1]: from collections import ChainMap
In [2]: from string import ascii_uppercase as up, ascii_lowercase as lo; x = dict(zip(lo, up)); y = dict(zip(up, lo))
In [3]: chainmap_dict = ChainMap(y, x)
In [4]: union_dict = dict(x.items() | y.items())
In [5]: timeit for k in union_dict: union_dict[k]
100000 loops, best of 3: 2.15 µs per loop
In [6]: timeit for k in chainmap_dict: chainmap_dict[k]
10000 loops, best of 3: 27.1 µs per loop
So about an order of magnitude slower for lookups. I'm a fan of Chainmap, but looks less practical where there may be many lookups.
Two dictionaries
def union2(dict1, dict2):
return dict(list(dict1.items()) + list(dict2.items()))
n dictionaries
def union(*dicts):
return dict(itertools.chain.from_iterable(dct.items() for dct in dicts))
sum has bad performance. See https://mathieularose.com/how-not-to-flatten-a-list-of-lists-in-python/
Simple solution using itertools that preserves order (latter dicts have precedence)
# py2
from itertools import chain, imap
merge = lambda *args: dict(chain.from_iterable(imap(dict.iteritems, args)))
# py3
from itertools import chain
merge = lambda *args: dict(chain.from_iterable(map(dict.items, args)))
And it's usage:
>>> x = {'a':1, 'b': 2}
>>> y = {'b':10, 'c': 11}
>>> merge(x, y)
{'a': 1, 'b': 10, 'c': 11}
>>> z = {'c': 3, 'd': 4}
>>> merge(x, y, z)
{'a': 1, 'b': 10, 'c': 3, 'd': 4}
Abuse leading to a one-expression solution for Matthew's answer:
>>> x = {'a':1, 'b': 2}
>>> y = {'b':10, 'c': 11}
>>> z = (lambda f=x.copy(): (f.update(y), f)[1])()
>>> z
{'a': 1, 'c': 11, 'b': 10}
You said you wanted one expression, so I abused lambda to bind a name, and tuples to override lambda's one-expression limit. Feel free to cringe.
You could also do this of course if you don't care about copying it:
>>> x = {'a':1, 'b': 2}
>>> y = {'b':10, 'c': 11}
>>> z = (x.update(y), x)[1]
>>> z
{'a': 1, 'b': 10, 'c': 11}
If you don't mind mutating x,
x.update(y) or x
Simple, readable, performant. You know update() always returns None, which is a false value. So the above expression will always evaluate to x, after updating it.
Most mutating methods in the standard library (like .update()) return None by convention, so this kind of pattern will work on those too. However, if you're using a dict subclass or some other method that doesn't follow this convention, then or may return its left operand, which may not be what you want. Instead, you can use a tuple display and index, which works regardless of what the first element evaluates to (although it's not quite as pretty):
(x.update(y), x)[-1]
If you don't have x in a variable yet, you can use lambda to make a local without using an assignment statement. This amounts to using lambda as a let expression, which is a common technique in functional languages, but is maybe unpythonic.
(lambda x: x.update(y) or x)({'a': 1, 'b': 2})
Although it's not that different from the following use of the new walrus operator (Python 3.8+ only),
(x := {'a': 1, 'b': 2}).update(y) or x
especially if you use a default argument:
(lambda x={'a': 1, 'b': 2}: x.update(y) or x)()
If you do want a copy, PEP 584 style x | y is the most Pythonic on 3.9+. If you must support older versions, PEP 448 style {**x, **y} is easiest for 3.5+. But if that's not available in your (even older) Python version, the let expression pattern works here too.
(lambda z=x.copy(): z.update(y) or z)()
(That is, of course, nearly equivalent to (z := x.copy()).update(y) or z, but if your Python version is new enough for that, then the PEP 448 style will be available.)
New in Python 3.9: Use the union operator (|) to merge dicts similar to sets:
>>> d = {'a': 1, 'b': 2}
>>> e = {'a': 9, 'c': 3}
>>> d | e
{'a': 9, 'b': 2, 'c': 3}
For matching keys, the right dict takes precedence.
This also works for |= to modify a dict in-place:
>>> e |= d # e = e | d
>>> e
{'a': 1, 'c': 3, 'b': 2}
Drawing on ideas here and elsewhere I've comprehended a function:
def merge(*dicts, **kv):
return { k:v for d in list(dicts) + [kv] for k,v in d.items() }
Usage (tested in python 3):
assert (merge({1:11,'a':'aaa'},{1:99, 'b':'bbb'},foo='bar')==\
{1: 99, 'foo': 'bar', 'b': 'bbb', 'a': 'aaa'})
assert (merge(foo='bar')=={'foo': 'bar'})
assert (merge({1:11},{1:99},foo='bar',baz='quux')==\
{1: 99, 'foo': 'bar', 'baz':'quux'})
assert (merge({1:11},{1:99})=={1: 99})
You could use a lambda instead.
(For Python 2.7* only; there are simpler solutions for Python 3*.)
If you're not averse to importing a standard library module, you can do
from functools import reduce
def merge_dicts(*dicts):
return reduce(lambda a, d: a.update(d) or a, dicts, {})
(The or a bit in the lambda is necessary because dict.update always returns None on success.)
It's so silly that .update returns nothing.
I just use a simple helper function to solve the problem:
def merge(dict1,*dicts):
for dict2 in dicts:
dict1.update(dict2)
return dict1
Examples:
merge(dict1,dict2)
merge(dict1,dict2,dict3)
merge(dict1,dict2,dict3,dict4)
merge({},dict1,dict2) # this one returns a new copy
There will be a new option when Python 3.8 releases (scheduled for 20 October, 2019), thanks to PEP 572: Assignment Expressions. The new assignment expression operator := allows you to assign the result of the copy and still use it to call update, leaving the combined code a single expression, rather than two statements, changing:
newdict = dict1.copy()
newdict.update(dict2)
to:
(newdict := dict1.copy()).update(dict2)
while behaving identically in every way. If you must also return the resulting dict (you asked for an expression returning the dict; the above creates and assigns to newdict, but doesn't return it, so you couldn't use it to pass an argument to a function as is, a la myfunc((newdict := dict1.copy()).update(dict2))), then just add or newdict to the end (since update returns None, which is falsy, it will then evaluate and return newdict as the result of the expression):
(newdict := dict1.copy()).update(dict2) or newdict
Important caveat: In general, I'd discourage this approach in favor of:
newdict = {**dict1, **dict2}
The unpacking approach is clearer (to anyone who knows about generalized unpacking in the first place, which you should), doesn't require a name for the result at all (so it's much more concise when constructing a temporary that is immediately passed to a function or included in a list/tuple literal or the like), and is almost certainly faster as well, being (on CPython) roughly equivalent to:
newdict = {}
newdict.update(dict1)
newdict.update(dict2)
but done at the C layer, using the concrete dict API, so no dynamic method lookup/binding or function call dispatch overhead is involved (where (newdict := dict1.copy()).update(dict2) is unavoidably identical to the original two-liner in behavior, performing the work in discrete steps, with dynamic lookup/binding/invocation of methods.
It's also more extensible, as merging three dicts is obvious:
newdict = {**dict1, **dict2, **dict3}
where using assignment expressions won't scale like that; the closest you could get would be:
(newdict := dict1.copy()).update(dict2), newdict.update(dict3)
or without the temporary tuple of Nones, but with truthiness testing of each None result:
(newdict := dict1.copy()).update(dict2) or newdict.update(dict3)
either of which is obviously much uglier, and includes further inefficiencies (either a wasted temporary tuple of Nones for comma separation, or pointless truthiness testing of each update's None return for or separation).
The only real advantage to the assignment expression approach occurs if:
sets and dicts (both of them support copy and update, so the code works roughly as you'd expect it to)dict itself, and must preserve the type and semantics of the left hand side (rather than ending up with a plain dict). While myspecialdict({**speciala, **specialb}) might work, it would involve an extra temporary dict, and if myspecialdict has features plain dict can't preserve (e.g. regular dicts now preserve order based on the first appearance of a key, and value based on the last appearance of a key; you might want one that preserves order based on the last appearance of a key so updating a value also moves it to the end), then the semantics would be wrong. Since the assignment expression version uses the named methods (which are presumably overloaded to behave appropriately), it never creates a dict at all (unless dict1 was already a dict), preserving the original type (and original type's semantics), all while avoiding any temporaries.The problem I have with solutions listed to date is that, in the merged dictionary, the value for key "b" is 10 but, to my way of thinking, it should be 12. In that light, I present the following:
import timeit
n=100000
su = """
x = {'a':1, 'b': 2}
y = {'b':10, 'c': 11}
"""
def timeMerge(f,su,niter):
print "{:4f} sec for: {:30s}".format(timeit.Timer(f,setup=su).timeit(n),f)
timeMerge("dict(x, **y)",su,n)
timeMerge("x.update(y)",su,n)
timeMerge("dict(x.items() + y.items())",su,n)
timeMerge("for k in y.keys(): x[k] = k in x and x[k]+y[k] or y[k] ",su,n)
#confirm for loop adds b entries together
x = {'a':1, 'b': 2}
y = {'b':10, 'c': 11}
for k in y.keys(): x[k] = k in x and x[k]+y[k] or y[k]
print "confirm b elements are added:",x
0.049465 sec for: dict(x, **y)
0.033729 sec for: x.update(y)
0.150380 sec for: dict(x.items() + y.items())
0.083120 sec for: for k in y.keys(): x[k] = k in x and x[k]+y[k] or y[k]
confirm b elements are added: {'a': 1, 'c': 11, 'b': 12}
cytoolz.merge_with (toolz.readthedocs.io/en/latest/…) –
Overthrust from collections import Counter
dict1 = {'a':1, 'b': 2}
dict2 = {'b':10, 'c': 11}
result = dict(Counter(dict1) + Counter(dict2))
This should solve your problem.
.update() instead of +. This is because, if the sum results to a value of 0 for any of the keys, Counter will delete it. –
Vulnerary This can be done with a single dict comprehension:
>>> x = {'a':1, 'b': 2}
>>> y = {'b':10, 'c': 11}
>>> { key: y[key] if key in y else x[key]
for key in set(x) + set(y)
}
In my view the best answer for the 'single expression' part as no extra functions are needed, and it is short.
>>> x = {'a':1, 'b': 2}
>>> y = {'b':10, 'c': 11}
>>> x, z = dict(x), x.update(y) or x
>>> x
{'a': 1, 'b': 2}
>>> y
{'c': 11, 'b': 10}
>>> z
{'a': 1, 'c': 11, 'b': 10}
x with its copy. If x is a function argument this won't work (see example) –
Venenose Python 3.9+ only
Merge (|) and update (|=) operators have been added to the built-in dict class.
>>> d = {'spam': 1, 'eggs': 2, 'cheese': 3}
>>> e = {'cheese': 'cheddar', 'aardvark': 'Ethel'}
>>> d | e
{'spam': 1, 'eggs': 2, 'cheese': 'cheddar', 'aardvark': 'Ethel'}
The augmented assignment version operates in-place:
>>> d |= e
>>> d
{'spam': 1, 'eggs': 2, 'cheese': 'cheddar', 'aardvark': 'Ethel'}
See PEP 584
In Python 3.9
Based on PEP 584, the new version of Python introduces two new operators for dictionaries: union (|) and in-place union (|=). You can use | to merge two dictionaries, while |= will update a dictionary in place:
>>> pycon = {2016: "Portland", 2018: "Cleveland"}
>>> europython = {2017: "Rimini", 2018: "Edinburgh", 2019: "Basel"}
>>> pycon | europython
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
>>> pycon |= europython
>>> pycon
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
If d1 and d2 are two dictionaries, then d1 | d2 does the same as {**d1, **d2}. The | operator is used for calculating the union of sets, so the notation may already be familiar to you.
One advantage of using | is that it works on different dictionary-like types and keeps the type through the merge:
>>> from collections import defaultdict
>>> europe = defaultdict(lambda: "", {"Norway": "Oslo", "Spain": "Madrid"})
>>> africa = defaultdict(lambda: "", {"Egypt": "Cairo", "Zimbabwe": "Harare"})
>>> europe | africa
defaultdict(<function <lambda> at 0x7f0cb42a6700>,
{'Norway': 'Oslo', 'Spain': 'Madrid', 'Egypt': 'Cairo', 'Zimbabwe': 'Harare'})
>>> {**europe, **africa}
{'Norway': 'Oslo', 'Spain': 'Madrid', 'Egypt': 'Cairo', 'Zimbabwe': 'Harare'}
You can use a defaultdict when you want to effectively handle missing keys. Note that | preserves the defaultdict, while {**europe, **africa} does not.
There are some similarities between how | works for dictionaries and how + works for lists. In fact, the + operator was originally proposed to merge dictionaries as well. This correspondence becomes even more evident when you look at the in-place operator.
The basic use of |= is to update a dictionary in place, similar to .update():
>>> libraries = {
... "collections": "Container datatypes",
... "math": "Mathematical functions",
... }
>>> libraries |= {"zoneinfo": "IANA time zone support"}
>>> libraries
{'collections': 'Container datatypes', 'math': 'Mathematical functions',
'zoneinfo': 'IANA time zone support'}
When you merge dictionaries with |, both dictionaries need to be of a proper dictionary type. On the other hand, the in-place operator (|=) is happy to work with any dictionary-like data structure:
>>> libraries |= [("graphlib", "Functionality for graph-like structures")]
>>> libraries
{'collections': 'Container datatypes', 'math': 'Mathematical functions',
'zoneinfo': 'IANA time zone support',
'graphlib': 'Functionality for graph-like structures'}
I know this does not really fit the specifics of the questions ("one liner"), but since none of the answers above went into this direction while lots and lots of answers addressed the performance issue, I felt I should contribute my thoughts.
Depending on the use case it might not be necessary to create a "real" merged dictionary of the given input dictionaries. A view which does this might be sufficient in many cases, i. e. an object which acts like the merged dictionary would without computing it completely. A lazy version of the merged dictionary, so to speak.
In Python, this is rather simple and can be done with the code shown at the end of my post. This given, the answer to the original question would be:
z = MergeDict(x, y)
When using this new object, it will behave like a merged dictionary but it will have constant creation time and constant memory footprint while leaving the original dictionaries untouched. Creating it is way cheaper than in the other solutions proposed.
Of course, if you use the result a lot, then you will at some point reach the limit where creating a real merged dictionary would have been the faster solution. As I said, it depends on your use case.
If you ever felt you would prefer to have a real merged dict, then calling dict(z) would produce it (but way more costly than the other solutions of course, so this is just worth mentioning).
You can also use this class to make a kind of copy-on-write dictionary:
a = { 'x': 3, 'y': 4 }
b = MergeDict(a) # we merge just one dict
b['x'] = 5
print b # will print {'x': 5, 'y': 4}
print a # will print {'y': 4, 'x': 3}
Here's the straight-forward code of MergeDict:
class MergeDict(object):
def __init__(self, *originals):
self.originals = ({},) + originals[::-1] # reversed
def __getitem__(self, key):
for original in self.originals:
try:
return original[key]
except KeyError:
pass
raise KeyError(key)
def __setitem__(self, key, value):
self.originals[0][key] = value
def __iter__(self):
return iter(self.keys())
def __repr__(self):
return '%s(%s)' % (
self.__class__.__name__,
', '.join(repr(original)
for original in reversed(self.originals)))
def __str__(self):
return '{%s}' % ', '.join(
'%r: %r' % i for i in self.iteritems())
def iteritems(self):
found = set()
for original in self.originals:
for k, v in original.iteritems():
if k not in found:
yield k, v
found.add(k)
def items(self):
return list(self.iteritems())
def keys(self):
return list(k for k, _ in self.iteritems())
def values(self):
return list(v for _, v in self.iteritems())
ChainMap which is available in Python 3 only and which does more or less what my code does. So shame on me for not reading everything carefully enough. But given that this only exists for Python 3, please take my answer as a contribution for the Python 2 users ;-) –
Dilks This is an expression for Python 3.5 or greater that merges dictionaries using reduce:
>>> from functools import reduce
>>> l = [{'a': 1}, {'b': 2}, {'a': 100, 'c': 3}]
>>> reduce(lambda x, y: {**x, **y}, l, {})
{'a': 100, 'b': 2, 'c': 3}
Note: this works even if the dictionary list is empty or contains only one element.
For a more efficient merge on Python 3.9 or greater, the lambda can be replaced directly by operator.ior:
>>> from functools import reduce
>>> from operator import ior
>>> l = [{'a': 1}, {'b': 2}, {'a': 100, 'c': 3}]
>>> reduce(ior, l, {})
{'a': 100, 'b': 2, 'c': 3}
For Python 3.8 or less, the following can be used as an alternative to ior:
>>> from functools import reduce
>>> l = [{'a': 1}, {'b': 2}, {'a': 100, 'c': 3}]
>>> reduce(lambda x, y: x.update(y) or x, l, {})
{'a': 100, 'b': 2, 'c': 3}
operator.ior instead. –
Lennyleno Using a dict comprehension, you may
x = {'a':1, 'b': 2}
y = {'b':10, 'c': 11}
dc = {xi:(x[xi] if xi not in list(y.keys())
else y[xi]) for xi in list(x.keys())+(list(y.keys()))}
gives
>>> dc
{'a': 1, 'c': 11, 'b': 10}
Note the syntax for if else in comprehension
{ (some_key if condition else default_key):(something_if_true if condition
else something_if_false) for key, value in dict_.items() }
... in list(y.keys()) instead of just ... in y. –
Galluses A union of the OP's two dictionaries would be something like:
{'a': 1, 'b': 2, 10, 'c': 11}
Specifically, the union of two entities(x and y) contains all the elements of x and/or y.
Unfortunately, what the OP asks for is not a union, despite the title of the post.
My code below is neither elegant nor a one-liner, but I believe it is consistent with the meaning of union.
From the OP's example:
x = {'a':1, 'b': 2}
y = {'b':10, 'c': 11}
z = {}
for k, v in x.items():
if not k in z:
z[k] = [(v)]
else:
z[k].append((v))
for k, v in y.items():
if not k in z:
z[k] = [(v)]
else:
z[k].append((v))
{'a': [1], 'b': [2, 10], 'c': [11]}
Whether one wants lists could be changed, but the above will work if a dictionary contains lists (and nested lists) as values in either dictionary.
union, for clarity. –
Eagleeyed {'a': 1, 'b': (2, 10), 'c': 11} …? –
Dilks You can use toolz.merge([x, y]) for this.
I was curious if I could beat the accepted answer's time with a one line stringify approach:
I tried 5 methods, none previously mentioned - all one liner - all producing correct answers - and I couldn't come close.
So... to save you the trouble and perhaps fulfill curiosity:
import json
import yaml
import time
from ast import literal_eval as literal
def merge_two_dicts(x, y):
z = x.copy() # start with x's keys and values
z.update(y) # modifies z with y's keys and values & returns None
return z
x = {'a':1, 'b': 2}
y = {'b':10, 'c': 11}
start = time.time()
for i in range(10000):
z = yaml.load((str(x)+str(y)).replace('}{',', '))
elapsed = (time.time()-start)
print (elapsed, z, 'stringify yaml')
start = time.time()
for i in range(10000):
z = literal((str(x)+str(y)).replace('}{',', '))
elapsed = (time.time()-start)
print (elapsed, z, 'stringify literal')
start = time.time()
for i in range(10000):
z = eval((str(x)+str(y)).replace('}{',', '))
elapsed = (time.time()-start)
print (elapsed, z, 'stringify eval')
start = time.time()
for i in range(10000):
z = {k:int(v) for k,v in (dict(zip(
((str(x)+str(y))
.replace('}',' ')
.replace('{',' ')
.replace(':',' ')
.replace(',',' ')
.replace("'",'')
.strip()
.split(' '))[::2],
((str(x)+str(y))
.replace('}',' ')
.replace('{',' ').replace(':',' ')
.replace(',',' ')
.replace("'",'')
.strip()
.split(' '))[1::2]
))).items()}
elapsed = (time.time()-start)
print (elapsed, z, 'stringify replace')
start = time.time()
for i in range(10000):
z = json.loads(str((str(x)+str(y)).replace('}{',', ').replace("'",'"')))
elapsed = (time.time()-start)
print (elapsed, z, 'stringify json')
start = time.time()
for i in range(10000):
z = merge_two_dicts(x, y)
elapsed = (time.time()-start)
print (elapsed, z, 'accepted')
results:
7.693928956985474 {'c': 11, 'b': 10, 'a': 1} stringify yaml
0.29134678840637207 {'c': 11, 'b': 10, 'a': 1} stringify literal
0.2208399772644043 {'c': 11, 'b': 10, 'a': 1} stringify eval
0.1106564998626709 {'c': 11, 'b': 10, 'a': 1} stringify replace
0.07989692687988281 {'c': 11, 'b': 10, 'a': 1} stringify json
0.005082368850708008 {'c': 11, 'b': 10, 'a': 1} accepted
What I did learn from this is that JSON approach is the fastest way (of those attempted) to return a dictionary from string-of-dictionary; much faster (about 1/4th of the time) of what I considered to be the normal method using ast. I also learned that, the YAML approach should be avoided at all cost.
Yes, I understand that this is not the best/correct way. I was curious if it was faster, and it isn't; I posted to prove it so.
json approach is faster than ast.literal_eval, but it's also not as comprehensive. It can't handle Python literals not in the JSON spec, so no tuples, sets, frozensets, bools (it can handle JSON bools, but not the result of stringifying a Python bool directly), etc. ast.literal_eval is slower, but at least some of that is a consequence of handling more complex inputs. That said, I'm pretty sure it could be faster if they bothered to optimize it, it's just pretty rare that evaluating strings of Python literals is the chokepoint in code. –
Mcclary I think my ugly one-liners are just necessary here.
z = next(z.update(y) or z for z in [x.copy()])
# or
z = (lambda z: z.update(y) or z)(x.copy())
P.S. This is a solution working in both versions of Python. I know that Python 3 has this {**x, **y} thing and it is the right thing to use (as well as moving to Python 3 if you still have Python 2 is the right thing to do).
A method is deep merging. Making use of the | operator in 3.9+ for the use case of dict new being a set of default settings, and dict existing being a set of existing settings in use. My goal was to merge in any added settings from new without over writing existing settings in existing. I believe this recursive implementation will allow one to upgrade a dict with new values from another dict.
def merge_dict_recursive(new: dict, existing: dict):
merged = new | existing
for k, v in merged.items():
if isinstance(v, dict):
if k not in existing:
# The key is not in existing dict at all, so add entire value
existing[k] = new[k]
merged[k] = merge_dict_recursive(new[k], existing[k])
return merged
Example test data:
new
{'dashboard': True,
'depth': {'a': 1, 'b': 22222, 'c': {'d': {'e': 69}}},
'intro': 'this is the dashboard',
'newkey': False,
'show_closed_sessions': False,
'version': None,
'visible_sessions_limit': 9999}
existing
{'dashboard': True,
'depth': {'a': 5},
'intro': 'this is the dashboard',
'newkey': True,
'show_closed_sessions': False,
'version': '2021-08-22 12:00:30.531038+00:00'}
merged
{'dashboard': True,
'depth': {'a': 5, 'b': 22222, 'c': {'d': {'e': 69}}},
'intro': 'this is the dashboard',
'newkey': True,
'show_closed_sessions': False,
'version': '2021-08-22 12:00:30.531038+00:00',
'visible_sessions_limit': 9999}
Deep merge of dicts:
from typing import List, Dict
from copy import deepcopy
def merge_dicts(*from_dicts: List[Dict], no_copy: bool=False) -> Dict :
""" no recursion deep merge of two dicts
By default creates fresh Dict and merges all to it.
no_copy = True, will merge all dicts to a fist one in a list without copy.
Why? Sometime I need to combine one dictionary from "layers".
The "layers" are not in use and dropped immediately after merging.
"""
if no_copy:
xerox = lambda x:x
else:
xerox = deepcopy
result = xerox(from_dicts[0])
for _from in from_dicts[1:]:
merge_queue = [(result, _from)]
for _to, _from in merge_queue:
for k, v in _from.items():
if k in _to and isinstance(_to[k], dict) and isinstance(v, dict):
# key collision add both are dicts.
# add to merging queue
merge_queue.append((_to[k], v))
continue
_to[k] = xerox(v)
return result
Usage:
print("=============================")
print("merge all dicts to first one without copy.")
a0 = {"a":{"b":1}}
a1 = {"a":{"c":{"d":4}}}
a2 = {"a":{"c":{"f":5}, "d": 6}}
print(f"a0 id[{id(a0)}] value:{a0}")
print(f"a1 id[{id(a1)}] value:{a1}")
print(f"a2 id[{id(a2)}] value:{a2}")
r = merge_dicts(a0, a1, a2, no_copy=True)
print(f"r id[{id(r)}] value:{r}")
print("=============================")
print("create fresh copy of all")
a0 = {"a":{"b":1}}
a1 = {"a":{"c":{"d":4}}}
a2 = {"a":{"c":{"f":5}, "d": 6}}
print(f"a0 id[{id(a0)}] value:{a0}")
print(f"a1 id[{id(a1)}] value:{a1}")
print(f"a2 id[{id(a2)}] value:{a2}")
r = merge_dicts(a0, a1, a2)
print(f"r id[{id(r)}] value:{r}")
The question is tagged python-3x but, taking into account that it's a relatively recent addition and that the most voted, accepted answer deals extensively with a Python 2.x solution, I dare add a one liner that draws on an irritating feature of Python 2.x list comprehension, that is name leaking...
$ python2
Python 2.7.13 (default, Jan 19 2017, 14:48:08)
[GCC 6.3.0 20170118] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> x = {'a':1, 'b': 2}
>>> y = {'b':10, 'c': 11}
>>> [z.update(d) for z in [{}] for d in (x, y)]
[None, None]
>>> z
{'a': 1, 'c': 11, 'b': 10}
>>> ...
I'm happy to say that the above doesn't work any more on any version of Python 3.
© 2022 - 2024 — McMap. All rights reserved.
{kind=link}
{**x, **y}method. However, theitemsapproach can be made workable by convertingdictitemstolistlikedict(list(x.items()), list(y.items())). – Subito