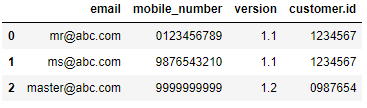
I need to format the contents of a Json file in a certain format in a pandas DataFrame so that I can run pandassql to transform the data and run it through a scoring model.
file = C:\scoring_model\json.js (contents of 'file' are below)
{
"response":{
"version":"1.1",
"token":"dsfgf",
"body":{
"customer":{
"customer_id":"1234567",
"verified":"true"
},
"contact":{
"email":"[email protected]",
"mobile_number":"0123456789"
},
"personal":{
"gender": "m",
"title":"Dr.",
"last_name":"Muster",
"first_name":"Max",
"family_status":"single",
"dob":"1985-12-23",
}
}
}
I need the dataframe to look like this (obviously all values on same row, tried to format it best as possible for this question):
version | token | customer_id | verified | email | mobile_number | gender |
1.1 | dsfgf | 1234567 | true | [email protected] | 0123456789 | m |
title | last_name | first_name |family_status | dob
Dr. | Muster | Max | single | 23.12.1985
I have looked at all the other questions on this topic, have tried various ways to load Json file into pandas
with open(r'C:\scoring_model\json.js', 'r') as f:
c = pd.read_json(f.read())
with open(r'C:\scoring_model\json.js', 'r') as f:
c = f.readlines()
tried pd.Panel() in this solution Python Pandas: How to split a sorted dictionary in a column of a dataframe with dataframe results from [yo = f.readlines()]. I thought about trying to split contents of each cell based on ("") and find a way to put the split contents into different columns but no luck so far.