I'm using Pipeline and ColumnTransformer modules from sklearn library to perform feature engineering on my dataset.
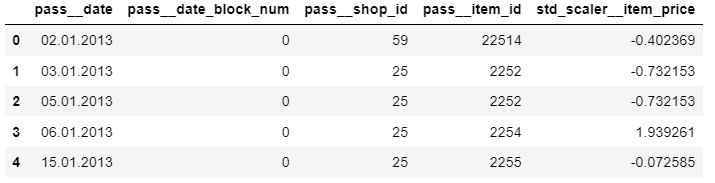
The dataset initially looks like this:
| date | date_block_num | shop_id | item_id | item_price |
|---|---|---|---|---|
| 02.01.2013 | 0 | 59 | 22154 | 999.00 |
| 03.01.2013 | 0 | 25 | 2552 | 899.00 |
| 05.01.2013 | 0 | 25 | 2552 | 899.00 |
| 06.01.2013 | 0 | 25 | 2554 | 1709.05 |
| 15.01.2013 | 0 | 25 | 2555 | 1099.00 |
$> data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2935849 entries, 0 to 2935848
Data columns (total 6 columns):
# Column Dtype
--- ------ -----
0 date object
1 date_block_num object
2 shop_id object
3 item_id object
4 item_price float64
dtypes: float64(2), int64(3), object(1)
memory usage: 134.4+ MB
Then I have the following transformations:
num_column_transformer = ColumnTransformer(
transformers=[
("std_scaler", StandardScaler(), make_column_selector(dtype_include=np.number)),
],
remainder="passthrough"
)
num_pipeline = Pipeline(
steps=[
("percent_item_cnt_day_per_shop", PercentOverTotalAttributeWholeAdder(
attribute_percent_name="shop_id",
attribute_total_name="item_cnt_day",
new_attribute_name="%_item_cnt_day_per_shop")
),
("percent_item_cnt_day_per_item", PercentOverTotalAttributeWholeAdder(
attribute_percent_name="item_id",
attribute_total_name="item_cnt_day",
new_attribute_name="%_item_cnt_day_per_item")
),
("percent_sales_per_shop", SalesPerAttributeOverTotalSalesAdder(
attribute_percent_name="shop_id",
new_attribute_name="%_sales_per_shop")
),
("percent_sales_per_item", SalesPerAttributeOverTotalSalesAdder(
attribute_percent_name="item_id",
new_attribute_name="%_sales_per_item")
),
("num_column_transformer", num_column_transformer),
]
)
The first four Transformers create four new different numeric variables and the last one applies StandardScaler over all the numerical values of the dataset.
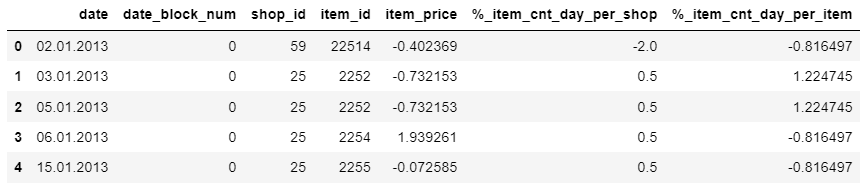
After executing it, I get the following data:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| -0.092652 | -0.765612 | -0.173122 | -0.756606 | -0.379775 | 02.01.2013 | 0 | 59 | 22154 |
| -0.092652 | 1.557684 | -0.175922 | 1.563224 | -0.394319 | 03.01.2013 | 0 | 25 | 2552 |
| -0.856351 | 1.557684 | -0.175922 | 1.563224 | -0.394319 | 05.01.2013 | 0 | 25 | 2552 |
| -0.092652 | 1.557684 | -0.17613 | 1.563224 | -0.396646 | 06.01.2013 | 0 | 25 | 2554 |
| -0.092652 | 1.557684 | -0.173278 | 1.563224 | -0.380647 | 15.01.2013 | 0 | 25 | 2555 |
I'd like to have the following output:
| date | date_block_num | shop_id | item_id | item_price | %_item_cnt_day_per_shop | %_item_cnt_day_per_item | %_sales_per_shop | %_sales_per_item |
|---|---|---|---|---|---|---|---|---|
| 02.01.2013 | 0 | 59 | 22154 | -0.092652 | -0.765612 | -0.173122 | -0.756606 | -0.379775 |
| 03.01.2013 | 0 | 25 | 2552 | -0.092652 | 1.557684 | -0.175922 | 1.563224 | -0.394319 |
| 05.01.2013 | 0 | 25 | 2552 | -0.856351 | 1.557684 | -0.175922 | 1.563224 | -0.394319 |
| 06.01.2013 | 0 | 25 | 2554 | -0.092652 | 1.557684 | -0.17613 | 1.563224 | -0.396646 |
| 15.01.2013 | 0 | 25 | 2555 | -0.092652 | 1.557684 | -0.173278 | 1.563224 | -0.380647 |
As you can see, columns 5, 6, 7, and 8 from the output corresponds to the first four columns in the original dataset. For example, I don't know where the item_price feature lies in the outputted table.
- How could I preserve the column order and names? After that, I want to do feature engineering over categorical variables and my Transformers make use of the feature column name.
- Am I using correctly the Scikit-Learn API?