It seems like CRITICAL_SECTION performance became worse on Windows 8 and higher. (see graphs below)
The test is pretty simple: some concurrent threads do 3 million locks each to access a variable exclusively. You can find the C++ program at the bottom of the question. I run the test on Windows Vista, Windows 7, Windows 8, Windows 10 (x64, VMWare, Intel Core i7-2600 3.40GHz).
The results are on the image below. The X-axis is the number of concurrent threads. The Y-axis is the elapsed time in seconds (lower is better).
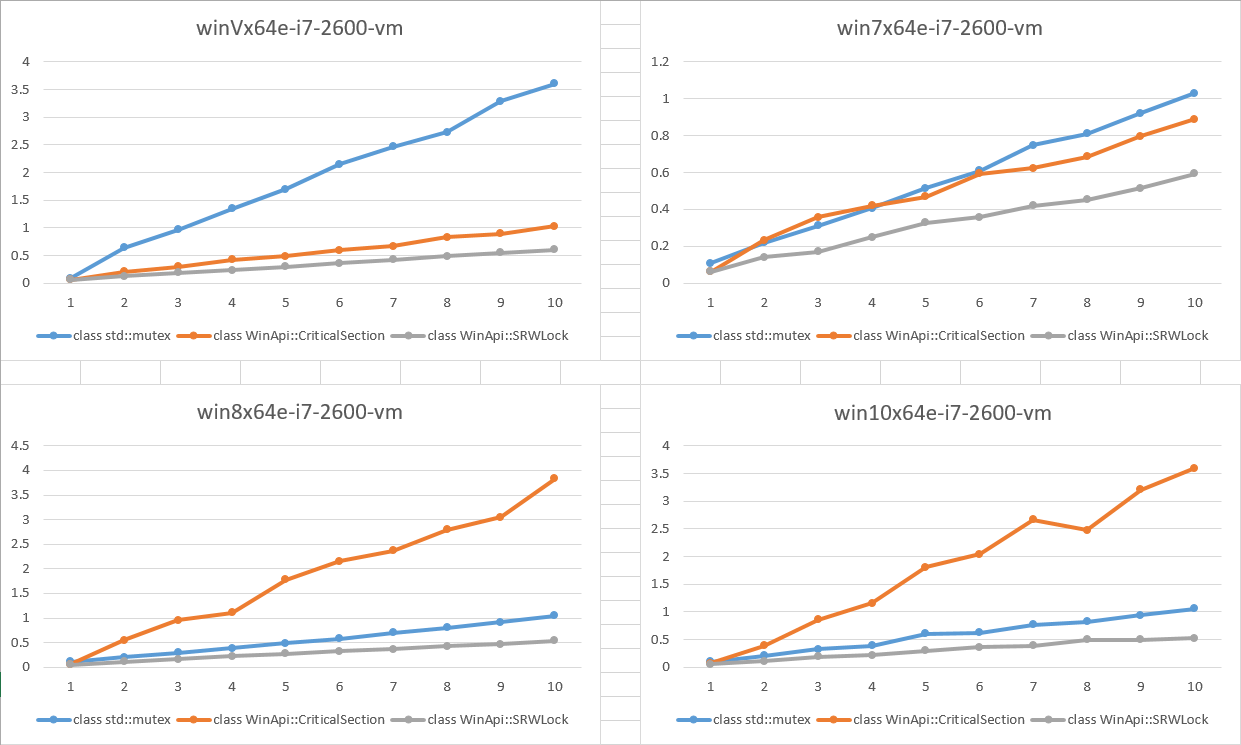
What we can see:
SRWLockperformance is approximately the same for all platformsCriticalSectionperformance became worse relatively SRWL on Windows 8 and higher
The question is: Can anybody please explain why did CRITICAL_SECTION performance become worse on Win8 and higher?
Some notes:
- The results on real machines are pretty the same - CS is much worse than both std::mutex, std::recursive_mutex and SRWL on Win8 and higher. However I have no chance to run the test on different OSes with the same CPU.
std::muteximplementation for Windows Vista is based onCRITICAL_SECTION, but for Win7 and higherstd::mutexis based on SWRL. It is correct for both MSVS17 and 15 (To make sure search forprimitives.hfile at MSVC++ installation and look forstl_critical_section_vistaandstl_critical_section_win7classes) This explains the difference between std::mutex performance on Win Vista and others.- As it is said in comments, the
std::mutexis a wrapper, so the possible explanation for some overhead relatively SRWL may be overhead introduced by the wrapper code.
#include <chrono>
#include <iostream>
#include <mutex>
#include <string>
#include <thread>
#include <vector>
#include <Windows.h>
const size_t T = 10;
const size_t N = 3000000;
volatile uint64_t var = 0;
const std::string sep = ";";
namespace WinApi
{
class CriticalSection
{
CRITICAL_SECTION cs;
public:
CriticalSection() { InitializeCriticalSection(&cs); }
~CriticalSection() { DeleteCriticalSection(&cs); }
void lock() { EnterCriticalSection(&cs); }
void unlock() { LeaveCriticalSection(&cs); }
};
class SRWLock
{
SRWLOCK srw;
public:
SRWLock() { InitializeSRWLock(&srw); }
void lock() { AcquireSRWLockExclusive(&srw); }
void unlock() { ReleaseSRWLockExclusive(&srw); }
};
}
template <class M>
void doLock(void *param)
{
M &m = *static_cast<M*>(param);
for (size_t n = 0; n < N; ++n)
{
m.lock();
var += std::rand();
m.unlock();
}
}
template <class M>
void runTest(size_t threadCount)
{
M m;
std::vector<std::thread> thrs(threadCount);
const auto start = std::chrono::system_clock::now();
for (auto &t : thrs) t = std::thread(doLock<M>, &m);
for (auto &t : thrs) t.join();
const auto end = std::chrono::system_clock::now();
const std::chrono::duration<double> diff = end - start;
std::cout << diff.count() << sep;
}
template <class ...Args>
void runTests(size_t threadMax)
{
{
int dummy[] = { (std::cout << typeid(Args).name() << sep, 0)... };
(void)dummy;
}
std::cout << std::endl;
for (size_t n = 1; n <= threadMax; ++n)
{
{
int dummy[] = { (runTest<Args>(n), 0)... };
(void)dummy;
}
std::cout << std::endl;
}
}
int main()
{
std::srand(time(NULL));
runTests<std::mutex, WinApi::CriticalSection, WinApi::SRWLock>(T);
return 0;
}
The test project was built as Windows Console Application on Microsoft Visual Studio 17 (15.8.2) with the folowing settings:
- Use of MFC: Use MFC in a Static Library
- Windows SDK Version: 10.0.17134.0
- Platform Toolset: Visual Studio 2017 (v141)
- Optimization: O2, Oi, Oy-, GL
std::randmakes me worried about thread safety. – Firststruct NoLock{void lock() {} void unlock() {}};-- see how much of the cost is fromrand()and how much from locking. – FirstSwitchToThread()orCreateFileW+CloseHandle- some more time/job inside critical region and compare difference in this case. SRW anyway will be faster, but not so. the mutex is shell over SRW, as result always will be bit slow compare it, but may be on vista another implementation, this can explain – Hostetterstd::this_thread::yield()call under the locked mutex. On Win10 the results forstd::mutexandSRWLare pretty the same, butCSis still worse thanstd::mutex10-25% depending on number of threads. – Morleystd::this_thread::yield()is also too small job. try for exampleif (HANDLE hEvent = CreateEvent(0,0,0,0)) { CloseHandle(hEvent); }– Hostetterstd::mutexis as wrapper on SRWL, it may perform worse due to its ability to fall-back to implementation that does not use SRWL. Calls to implementation is done using pointers-to-function, and runtime library is complied with security options enabled, so Control Flow Guard chimes in. – Cropper