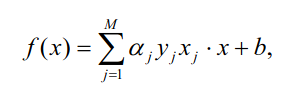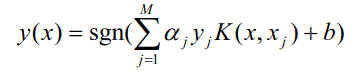I was stuck with a similar problem but for a different reason.
My objective was to compute the inference not using the built-in SVC.predict.
Assuming that:
import numpy as np
from sklearn.svm import SVC
X = np.array([[3, 4], [1, 4], [2, 3], [6, -1], [7, -1], [5, -3]])
y = np.array([-1, -1, -1, 1, 1, 1])
clf = SVC(C=1e5, kernel='linear')
clf.fit(X, y)
I would like to compute predictions for trained models only using algebra.
Now the formula for linear inference is easy:
![enter image description here]()
where ![\alpha_jy_jx_j]() collectively are called weights. What makes matters super easy is that
collectively are called weights. What makes matters super easy is that clf.coef_ gets you the weights.
So:
w = clf.coef_
b = clf.intercept_
assert np.sign(w.dot(X[0]) + b)[0] == clf.predict(X[0].reshape((1, 2)))
Side note: the sum of multiplications is exactly what dot does on two vectors, and reshape for input vector is needed to conform with the expected predict input shape.
But of course, for other kernels, it is more complicated than that, from this formula ![enter image description here]() and previous answers we cannot pre-compute the weights since
and previous answers we cannot pre-compute the weights since ![\alpha_jy_jK(x,x_j)]() are all tied in together.
are all tied in together.
Now, this is where I've got stuck until I've got some help from a friend.
Who discovered this documentation page. It says that ![\alpha_jy_j]() is
is clf.dual_coef_ in scikit learn terms.
Once you know that this equation becomes easy as well.
We now know the value of ![\alpha_jy_j]() . One thing left to do is to calculate the kernel function, which depends on type of the kernel, for polynomial kernel of 3rd degree (this is the default degree for poly SVM in scikit)
. One thing left to do is to calculate the kernel function, which depends on type of the kernel, for polynomial kernel of 3rd degree (this is the default degree for poly SVM in scikit) ![K(x,x_j)]() roughly translates to
roughly translates to np.power(clf.support_vectors_.dot(X), clf.degree). **
Now let's combine everything we've learned into this code snippet:
import numpy as np
from sklearn.svm import SVC
X = np.array([[3, 4], [1, 4], [2, 3], [6, -1], [7, -1], [5, -3]])
y = np.array([-1, -1, -1, 1, 1, 1])
clf = SVC(kernel='poly', gamma=1)
clf.fit(X, y)
print('b = ', clf.intercept_)
print('Indices of support vectors = ', clf.support_)
print('Support vectors = ', clf.support_vectors_)
print('Number of support vectors for each class = ', clf.n_support_)
print('Coefficients of the support vector in the decision function = ', np.abs(clf.dual_coef_))
negative_prediction = clf.dual_coef_.dot(np.power(clf.gamma * clf.support_vectors_.dot(X[0]), clf.degree)) + clf.intercept_
positive_prediction = clf.dual_coef_.dot(np.power(clf.gamma * clf.support_vectors_.dot(X[4]), clf.degree)) + clf.intercept_
print('Compare both results')
print(negative_prediction, clf.decision_function(X[0].reshape((1, 2))))
print(positive_prediction, clf.decision_function(X[4].reshape((1, 2))))
assert np.sign(negative_prediction) == clf.predict(X[0].reshape((1, 2)))
assert np.sign(positive_prediction) == clf.predict(X[4].reshape((1, 2)))
If you run it you'll see that the assertions are passing, WOO HOO! We now can predict the results not using the predict, and I hope it may help with the question asked. Since now you can adjust dual coefficients the same way you wanted to adjust weights.
** But please pay attention that if you do not use gamma, also remove it from the "manual calculations", since it will just break otherwise. Also, it is an example of inference for polynomial kernel, for other kernels inference function should be adjusted accordingly. See documentation
- Source for formulas snapshots and much more info about SVM.
- Relevant scikit learn documentation
- The code snippet based on something I've seen on stackoverflow, but I've lost the source link. So I would like to thank and credit the original author(once I find him).