Hi I am working on Key Point Analysis Task, which is shared by IBM, here is the link. In the given dataset there are more than one rows of text and anyone can please tell me how can I convert the text columns into tensors and again assign them in the same dataFrame because there are other columns of data there. 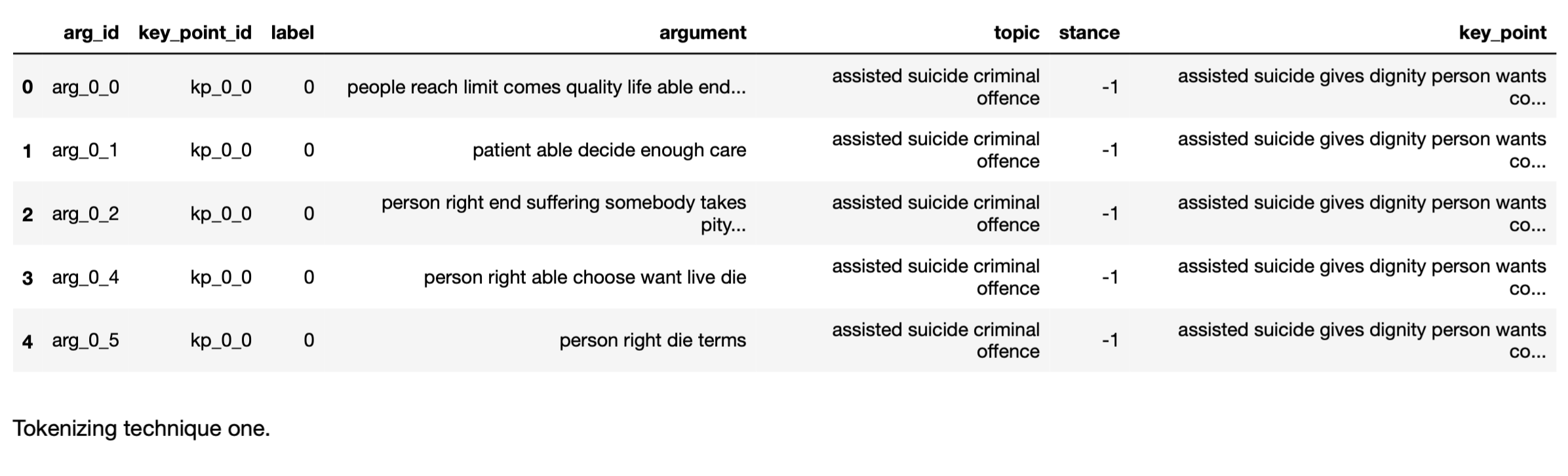
Problem
Here I am facing a problem that I have never seen this kind of data before like have multiple text columns, How can I convert all those columns into tensors and then apply a model. Most of the time data is like : One Text Column and other columns are label, Example: Movie Reviews , Toxic Comment classification.
def clean_text(text):
"""
text: a string
return: modified initial string
"""
text = text.lower() # lowercase text
text = REPLACE_BY_SPACE_RE.sub(' ',
text)
text = BAD_SYMBOLS_RE.sub('',
text)
text = text.replace('x', '')
# text = re.sub(r'\W+', '', text)
text = ' '.join(word for word in text.split() if word not in STOPWORDS)
return text