Original answer from February 2015:
I'm using Visual Studio 2013.
My results in single threaded usage are looking similar to waldez results:
1 million of lock/unlock calls:
CRITICAL_SECTION: 19 ms
std::mutex: 48 ms
std::recursive_mutex: 48 ms
The reason why Microsoft changed implementation is C++11 compatibility.
C++11 has 4 kind of mutexes in std namespace:
Microsoft std::mutex and all other mutexes are the wrappers around critical section:
struct _Mtx_internal_imp_t
{ /* Win32 mutex */
int type; // here MS keeps particular mutex type
Concurrency::critical_section cs;
long thread_id;
int count;
};
As for me, std::recursive_mutex should completely match critical section. So Microsoft should optimize its implementation to take less CPU and memory.
Update from February 2023:
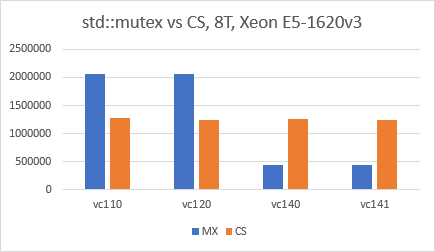
Fresh investigation shows the difference in std::mutex implementation in latest versions of MSVC compared to MSVC 2013.
I tried the following compilers/STL and they showed the same behavior:
- MSVC 2019 (SDK 14.29.30133)
- MSVC 2022 (SDK 14.33.31629)
Both of them are using SRW locks for std::mutex implementation by default.
However CRT still can choosing CRITICAL_SECTION-based implementation in runtime.
Here is the modern underlaying structure definition:
struct _Mtx_internal_imp_t { // ConcRT mutex
int type;
std::aligned_storage_t<Concurrency::details::stl_critical_section_max_size,
Concurrency::details::stl_critical_section_max_alignment>
cs;
long thread_id;
int count;
Concurrency::details::stl_critical_section_interface* _get_cs() { // get pointer to implementation
return reinterpret_cast<Concurrency::details::stl_critical_section_interface*>(&cs);
}
};
And this is how it is initialized:
void _Mtx_init_in_situ(_Mtx_t mtx, int type) { // initialize mutex in situ
Concurrency::details::create_stl_critical_section(mtx->_get_cs());
mtx->thread_id = -1;
mtx->type = type;
mtx->count = 0;
}
inline void create_stl_critical_section(stl_critical_section_interface* p) {
#ifdef _CRT_WINDOWS
new (p) stl_critical_section_win7;
#else
switch (__stl_sync_api_impl_mode) {
case __stl_sync_api_modes_enum::normal:
case __stl_sync_api_modes_enum::win7:
if (are_win7_sync_apis_available()) {
new (p) stl_critical_section_win7;
return;
}
// fall through
case __stl_sync_api_modes_enum::vista:
new (p) stl_critical_section_vista;
return;
default:
abort();
}
#endif // _CRT_WINDOWS
}
are_win7_sync_apis_available is checking existence of API function TryAcquireSRWLockExclusive in runtime.
As you can see, create_stl_critical_section will choose stl_critical_section_vista if it is run on Windows Vista for example.
We can also force CRT to choose CRITICAL_SECTION-based implementation by calling undocumented function __set_stl_sync_api_mode:
#include <mutex>
enum class __stl_sync_api_modes_enum { normal, win7, vista, concrt };
extern "C" _CRTIMP2 void __cdecl __set_stl_sync_api_mode(__stl_sync_api_modes_enum mode);
int main()
{
__set_stl_sync_api_mode(__stl_sync_api_modes_enum::vista);
std::mutex protect; // now it is forced to use CRITICAL_SECTION inside
}
This works for both dynamic CRT linking (DLL) and for static CRT. But debugging of static CRT is much easier (in debug mode).
std::mutexis not an STL class. Neither is any other synchronization object. – Influxstd::mutex,memcpyorstd::ofstream, for example, are not typically considered part of the STL – Bellerophon