I need to write a large number of documents to Firestore.
What is the fastest way to do this in Node.js?
I need to write a large number of documents to Firestore.
What is the fastest way to do this in Node.js?
TL;DR: The fastest way to perform bulk date creation on Firestore is by performing parallel individual write operations.
Writing 1,000 documents to Firestore takes:
~105.4s when using sequential individual write operations~ 2.8s when using (2) batched write operations~ 1.5s when using parallel individual write operationsThere are three common ways to perform a large number of write operations on Firestore.
We'll investigate each in turn below, using an array of randomized document data.
This is the simplest possible solution:
async function testSequentialIndividualWrites(datas) {
while (datas.length) {
await collection.add(datas.shift());
}
}
We write each document in turn, until we've written every document. And we wait for each write operation to complete before starting on the next one.
Writing 1,000 documents takes about 105 seconds with this approach, so the throughput is roughly 10 document writes per second.
This is the most complex solution.
async function testBatchedWrites(datas) {
let batch = admin.firestore().batch();
let count = 0;
while (datas.length) {
batch.set(collection.doc(Math.random().toString(36).substring(2, 15)), datas.shift());
if (++count >= 500 || !datas.length) {
await batch.commit();
batch = admin.firestore().batch();
count = 0;
}
}
}
You can see that we create a BatchedWrite object by calling batch(), fill that until its maximum capacity of 500 documents, and then write it to Firestore. We give each document a generated name that is relatively likely to be unique (good enough for this test).
Writing 1,000 document takes about 2.8 seconds with this approach, so the throughput is roughly 357 document writes per second.
That's quite a bit faster than with the sequential individual writes. In fact: many developers use this approach because they assume it is fastest, but as the results above already showed this is not true. And the code is by far the most complex, due to the size constraint on batches.
The Firestore documentation says this about the performance for adding lots of data:
For bulk data entry, use a server client library with parallelized individual writes. Batched writes perform better than serialized writes but not better than parallel writes.
We can put that to the test with this code:
async function testParallelIndividualWrites(datas) {
await Promise.all(datas.map((data) => collection.add(data)));
}
This code kicks of the add operations as fast as it can, and then uses Promise.all() to wait until they're all finished. With this approach the operations can run in parallel.
Writing 1,000 document takes about 1.5 seconds with this approach, so the throughput is roughly 667 document writes per second.
The difference isn't nearly as great as between the first two approaches, but it still is over 1.8 times faster than batched writes.
A few notes:
add() does nothing more than generate a unique ID (purely client-side), followed by a set() operation. So the results should be the same. If that's not what you observe, post a new question with the minimal case that reproduces what you have tried. –
Clerkly Math.random().toString(36).substring(2, 15), which I'm pretty sure I copied from the SDK source code. :) –
Clerkly Promise-based approach. –
Entrails Promise.all is rejected if any of the elements are rejected. you may use Promise.allSettled instead. –
Interpreter As noted in a comment to the OP, I've had the opposite experience when writing documents to Firestore inside a Cloud Function.
TL;DR: Parallel individual writes are over 5x slower than parallel batch writes when writing 1200 documents to Firestore.
The only explanation I can think of for this, is some sort of bottleneck or request rate limiting happening between Google cloud functions and Firestore. It's a bit of a mystery.
Here's the code for both methods I benchmarked:
const functions = require('firebase-functions');
const admin = require('firebase-admin');
admin.initializeApp();
const db = admin.firestore();
// Parallel Batch Writes
exports.cloneAppBatch = functions.https.onCall((data, context) => {
return new Promise((resolve, reject) => {
let fromAppKey = data.appKey;
let toAppKey = db.collection('/app').doc().id;
// Clone/copy data from one app subcollection to another
let startTimeMs = Date.now();
let docs = 0;
// Write the app document (and ensure cold start doesn't affect timings below)
db.collection('/app').doc(toAppKey).set({ desc: 'New App' }).then(() => {
// Log Benchmark
functions.logger.info(`[BATCH] 'Write App Config Doc' took ${Date.now() - startTimeMs}ms`);
// Get all documents in app subcollection
startTimeMs = Date.now();
return db.collection(`/app/${fromAppKey}/data`).get();
}).then(appDataQS => {
// Log Benchmark
functions.logger.info(`[BATCH] 'Read App Data' took ${Date.now() - startTimeMs}ms`);
// Batch up documents and write to new app subcollection
startTimeMs = Date.now();
let commits = [];
let bDocCtr = 0;
let batch = db.batch();
appDataQS.forEach(docSnap => {
let doc = docSnap.data();
let docKey = docSnap.id;
docs++;
let docRef = db.collection(`/app/${toAppKey}/data`).doc(docKey);
batch.set(docRef, doc);
bDocCtr++
if (bDocCtr >= 500) {
commits.push(batch.commit());
batch = db.batch();
bDocCtr = 0;
}
});
if (bDocCtr > 0) commits.push(batch.commit());
Promise.all(commits).then(results => {
// Log Benchmark
functions.logger.info(`[BATCH] 'Write App Data - ${docs} docs / ${commits.length} batches' took ${Date.now() - startTimeMs}ms`);
resolve(results);
});
}).catch(err => {
reject(err);
});
});
});
// Parallel Individual Writes
exports.cloneAppNoBatch = functions.https.onCall((data, context) => {
return new Promise((resolve, reject) => {
let fromAppKey = data.appKey;
let toAppKey = db.collection('/app').doc().id;
// Clone/copy data from one app subcollection to another
let startTimeMs = Date.now();
let docs = 0;
// Write the app document (and ensure cold start doesn't affect timings below)
db.collection('/app').doc(toAppKey).set({ desc: 'New App' }).then(() => {
// Log Benchmark
functions.logger.info(`[INDIVIDUAL] 'Write App Config Doc' took ${Date.now() - startTimeMs}ms`);
// Get all documents in app subcollection
startTimeMs = Date.now();
return db.collection(`/app/${fromAppKey}/data`).get();
}).then(appDataQS => {
// Log Benchmark
functions.logger.info(`[INDIVIDUAL] 'Read App Data' took ${Date.now() - startTimeMs}ms`);
// Gather up documents and write to new app subcollection
startTimeMs = Date.now();
let commits = [];
appDataQS.forEach(docSnap => {
let doc = docSnap.data();
let docKey = docSnap.id;
docs++;
// Parallel individual writes
commits.push(db.collection(`/app/${toAppKey}/data`).doc(docKey).set(doc));
});
Promise.all(commits).then(results => {
// Log Benchmark
functions.logger.info(`[INDIVIDUAL] 'Write App Data - ${docs} docs' took ${Date.now() - startTimeMs}ms`);
resolve(results);
});
}).catch(err => {
reject(err);
});
});
});
The specific results were (average of 3 runs each):
Batch Writes:
Read 1200 docs - 2.4 secs / Write 1200 docs - 1.8 secs
Individual Writes:
Read 1200 docs - 2.4 secs / Write 1200 docs - 10.5 secs
Note: These results are a lot better than what I was getting the other day - maybe Google was having a bad day - but the relative performance between batch and individual writes remains the same. Would be good to see if anyone else has had a similar experience.
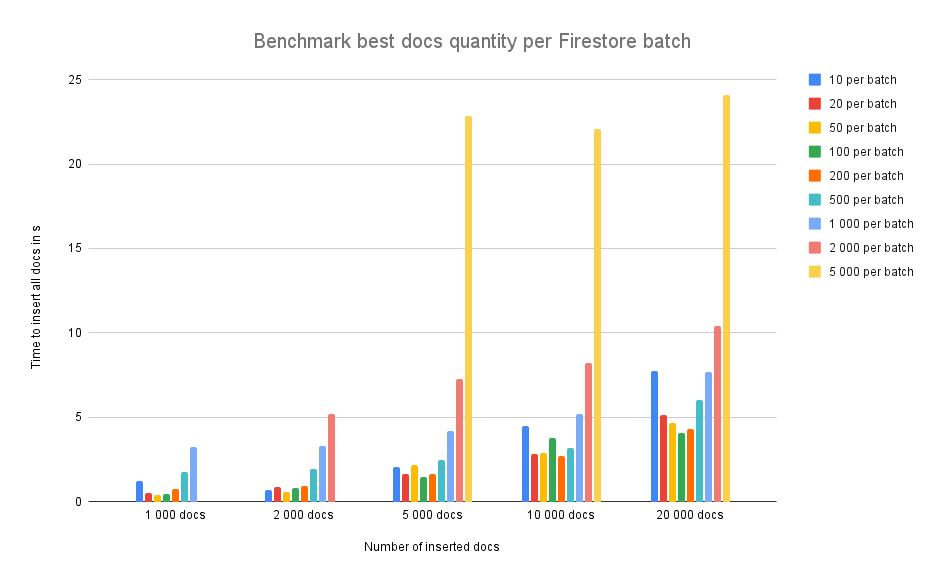
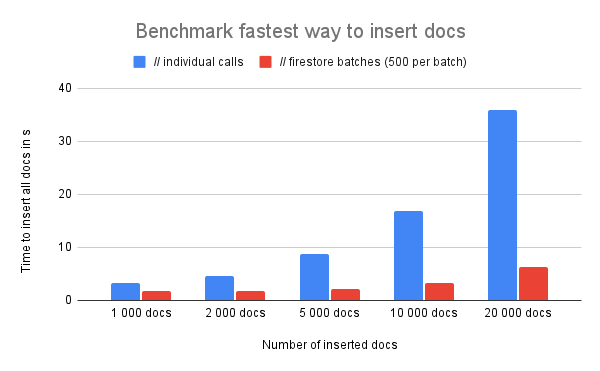
I was working on benchmarking Firestore (with Node) when inserting data. Here are my findings:
In details:
I came across this little library that implements the parallelized batch operations @DG mentioned: https://github.com/stpch/firestore-multibatch. It provides a simple interface, so you can keep adding to the batch without worrying about the 500 op limit.
Use Firestore's batch functionality to write multiple documents in a single request:
Initialize Firestore:
const { Firestore } = require('@google-cloud/firestore');
const firestore = new Firestore();
Create a batch and add write operations:
const batch = firestore.batch();
const data = [...]; // Your array of documents
data.forEach((doc, index) => {
const docRef = firestore.collection('your-collection').doc(`doc-${index}`);
batch.set(docRef, doc);
});
Commit the batch:
await batch.commit();
© 2022 - 2025 — McMap. All rights reserved.
{kind=link}
{kind=link}
{kind=link}