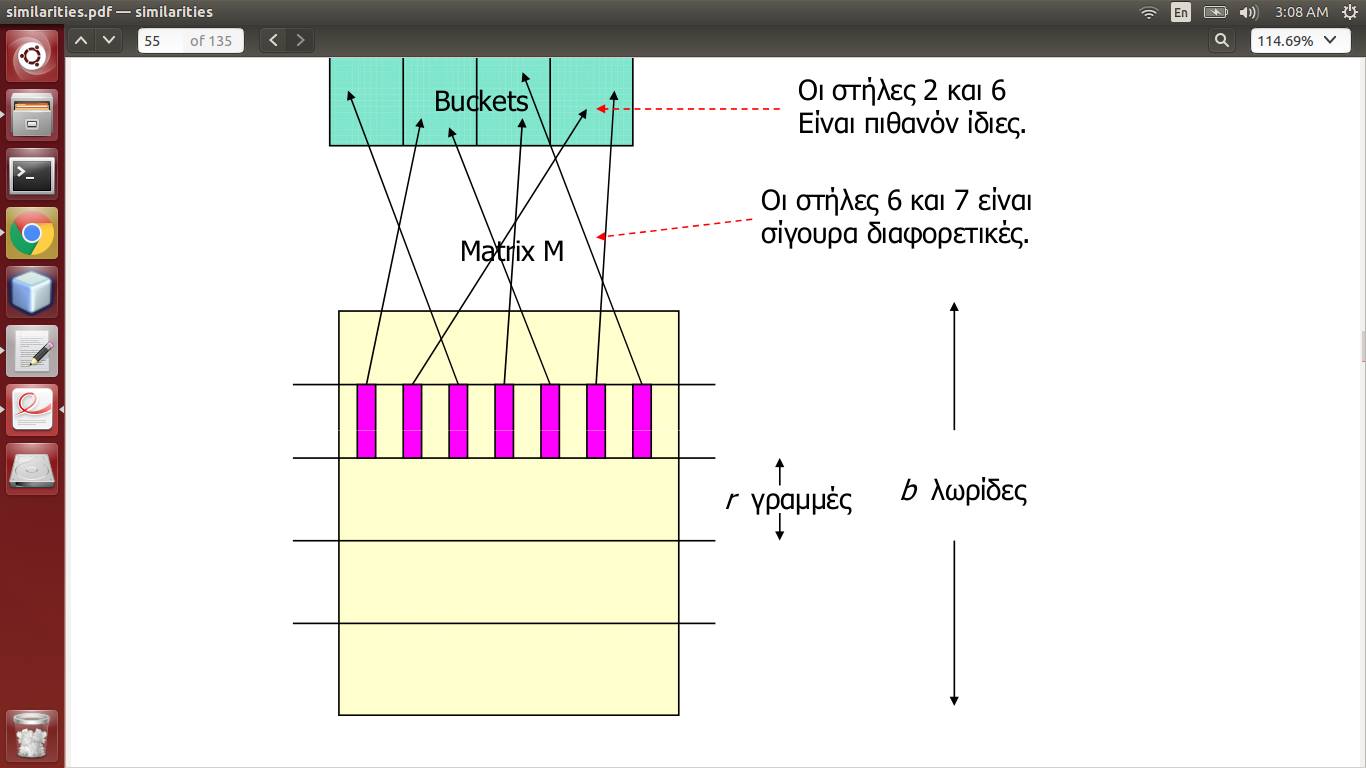
Matrix M is the signatures matrix, which is produced via Minhashing of the actual data, has documents as columns and words as rows. So a column represents a document.
Now it says that every stripe (b in number, r in length) has its columns hashed, so that a column falls in a bucket. If two columns fall in the same bucket, for >= 1 stripes, then they are potentially similar.
So that means that I should create b hashtables and find b independent hash functions? Or just one is enough and every stripe sends its columns to the same collections of buckets (but wouldn't this cancel the stripes)?
Would a dictionary be enough for a hashtable in this case*?