Let me try to answer this "in the narrow" (others have already described why the description "as-is" is somewhat lacking/incomplete/misleading):
In what context would any compiler generate different code for those two?
A "not-very-optimizing" compiler might generate different code in just about any context, because, while parsing, there's a difference: x[y] is one expression (index into an array), while *(x+y) are two expressions (add an integer to a pointer, then dereference it). Sure, it's not very hard to recognize this (even while parsing) and treat it the same, but, if you're writing a simple/fast compiler, then you avoid putting "too much smarts into it". As an example:
char vector[] = ...;
char f(int i) {
return vector[i];
}
char g(int i) {
return *(vector + i);
}
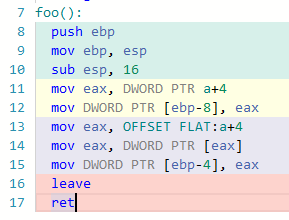
Compiler, while parsing f(), sees the "indexing" and may generate something like (for some 68000-like CPU):
MOVE D0, [A0 + D1] ; A0/vector, D1/i, D0/result of function
OTOH, for g(), compiler sees two things: first a dereference (of "something yet to come") and then the adding of integer to pointer/array, so being not-very-optimizing, it could end up with:
MOVE A1, A0 ; A1/t = A0/vector
ADD A1, D1 ; t += i/D1
MOVE D0, [A1] ; D0/result = *t
Obviously, this is very implementation dependent, some compiler might also dislike using complex instructions as used for f() (using complex instructions makes it harder to debug the compiler), the CPU might not have such complex instructions, etc.
Is there a difference between "move" from base, and "add" to base?
The description in the book is arguably not well-worded. But, I think the author wanted to describe the distinction shown above - indexing ("move" from base) is one expression, while "add and then dereference" are two expressions.
This is about compiler implementation, not language definition, the distinction which should have also been explicitly indicated in the book.

a[5]) because it can compute the offset at compile time, but I don't see howa[i]and*(a + i)would be handled differently without knowing the value ofiat translation time. – Thorman*(a + 5). Comparinga[5]with*(a + i)is apples and oranges. – Spontaneousa[i+5]with(a+5)[i], for a couple of reasons: (1) The compiler can recognize (a+5) as a constant, while ti would be slightly harder to split out the expressioni+5into a constant and non-constant portion. Looking for an indexing expression of the form (const+x) or (x+const) shouldn't be too hard, but would require a bit of extra work. Additionally, ifiis unsigned, thena[i+5]must behave predictably with values from UINT_MAX-4 to UINT_MAX, but(a+5)[i]need not do so. – Tennera[i]and*(a + i)would be handled differently from each other without knowing the value ofiat translation time" - better? I wasn't comparinga[5]to*(a + i). – Thormanint[] a={1,2,3};orint* a=new int[]{1,2,3};?" or something like that. – Condensed