You could try your same push with:
This option is from those paches, and implemented in commit d5d2e93, which includes the comment:
These improvements will have even larger benefits in the super-
large Windows repository.
That should be interesting in your case.
See "Exploring new frontiers for Git push performance" from Derrick Stolee
A git push would typically display something like:
$ git push origin topic
Enumerating objects: 3670, done.
Counting objects: 100% (2369/2369), done.
Delta compression using up to 8 threads
Compressing objects: 100% (546/546), done.
Writing objects: 100% (1378/1378), 468.06 KiB | 7.67 MiB/s, done.
Total 1378 (delta 1109), reused 1096 (delta 832)
remote: Resolving deltas: 100% (1109/1109), completed with 312 local objects.
To https://server.info/fake.git
* [new branch] topic -> topic
"Enumerating" means:
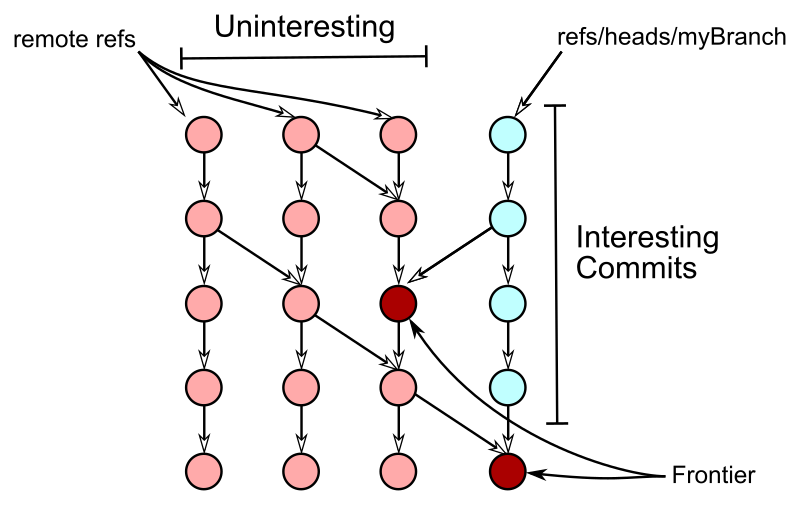
Git constructs a pack-file that contains the commit you are trying to push, as well as all commits, trees, and blobs (collectively, objects) that the server will need to understand that commit.
It finds a set of commits, trees, and blobs such that every reachable object is either in the set or known to be on the server.
The goal is to find the right "frontier"
![https://static.mcmap.net/file/mcmap/ZG-AbGLDKwfkX7XiaFfnbw2tZVMwa1MvXn3QWRft/devops/wp-content/uploads/sites/6/2019/05/sparse-push-commit-walk.png]()
The uninteresting commits that are direct parents of interesting commits form the frontier
Old:
To determine which trees and blobs are interesting, the old algorithm first determined all uninteresting trees and blobs.
Starting at every uninteresting commit in the frontier, recursively walk from its root tree and mark all reachable trees and blobs as uninteresting. This walk skips trees that were already marked as uninteresting to avoid revisiting potentially large portions of the graph.
![https://static.mcmap.net/file/mcmap/ZG-AbGLDKwfkX7XiaFfnbw2tZVMwa1MvXn3QWRft/devops/wp-content/uploads/sites/6/2019/05/sparse-push-old-algorithm.png]()
New
The old algorithm is recursive: it takes a tree and runs the algorithm on all subtrees.
The new algorithm uses the paths to reduce the scope of the tree walk. It is also recursive, but it takes a set of trees.
As we start the algorithm, the set of trees contains the root trees for the uninteresting and the interesting commits.
![https://static.mcmap.net/file/mcmap/ZG-AbGLDKwfkX7XiaFfnbw2tZVMwa1MvXn3QWRft/devops/wp-content/uploads/sites/6/2019/05/sparse-push-new-algorithm.png]()
The new tree walk recursively explores paths containing interesting and uninteresting trees.
Inside the trees at B, we have subtrees with names F and G.
Both sets have interesting and uninteresting paths, so we recurse into each set. This continues into B/F and B/G. The B/F set will not recurse into B/F/M or B/F/N and the B/G set will not recurse into B/G/X but not B/G/Y.

git show --name-status <your branch>, how many file there are? – Ugrianpack.sparsewhich can help the performance of the push. See my answer below. – Sump