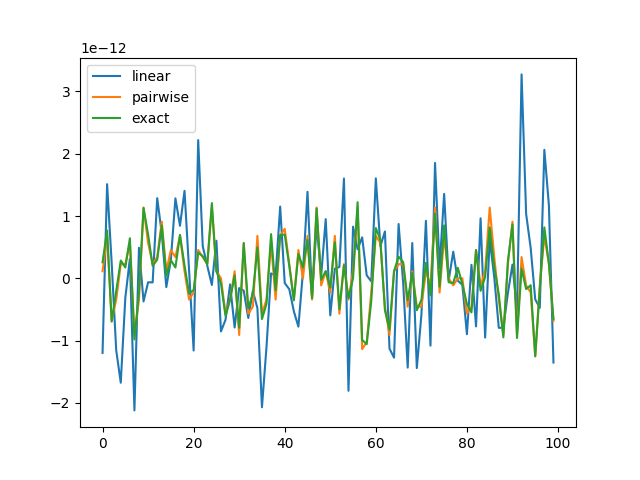
In this example, the column-wise sum of an array pr is computed in two different ways:
(a) take the sum over the first axis using p.sum's axis parameter
(b) slice the array along the the second axis and take the sum of each slice
import matplotlib.pyplot as plt
import numpy as np
m = 100
n = 2000
x = np.random.random_sample((m, n))
X = np.abs(np.fft.rfft(x)).T
frq = np.fft.rfftfreq(n)
total = X.sum(axis=0)
c = frq @ X / total
df = frq[:, None] - c
pr = df * X
a = np.sum(pr, axis=0)
b = [np.sum(pr[:, i]) for i in range(m)]
fig, ax = plt.subplots(1)
ax.plot(a)
ax.plot(b)
plt.show()
Both methods should return the same, but for whatever reason, in this example, they do not. As you can see in the plot below, a and b have totally different values. The difference is, however, so small that np.allclose(a, b) is True.
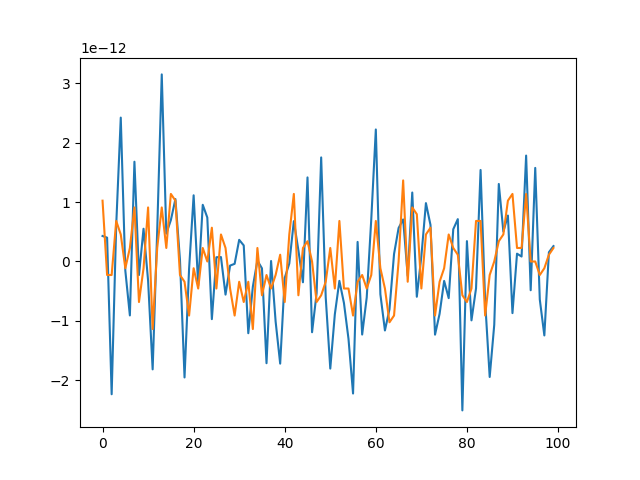
If you replace pr with some small random values, there is no difference between the two summation methods:
pr = np.random.randn(n, m) / 1e12
a = np.sum(pr, axis=0)
b = np.array([np.sum(pr[:, i]) for i in range(m)])
fig, ax = plt.subplots(1)
ax.plot(a)
ax.plot(b)
plt.show()
The second example indicates that the differences in the sums of the first example are not related to the summation methods. Then, is this a problem relate to floating point value summation? If so, why doesn't such an effect occure in the second example?
Why do the colum-wise sums differ in the first example, and which one is correct?