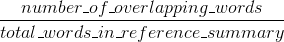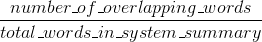In general:
Bleu measures precision: how much the words (and/or n-grams) in the machine generated summaries appeared in the human reference summaries.
Rouge measures recall: how much the words (and/or n-grams) in the human reference summaries appeared in the machine generated summaries.
Naturally - these results are complementing, as is often the case in precision vs recall. If you have many words from the system results appearing in the human references you will have high Bleu, and if you have many words from the human references appearing in the system results you will have high Rouge.
In your case it would appear that sys1 has a higher Rouge than sys2 since the results in sys1 consistently had more words from the human references appear in them than the results from sys2. However, since your Bleu score showed that sys1 has lower recall than sys2, this would suggest that not so many words from your sys1 results appeared in the human references, in respect to sys2.
This could happen for example if your sys1 is outputting results which contain words from the references (upping the Rouge), but also many words which the references didn't include (lowering the Bleu). sys2, as it seems, is giving results for which most words outputted do appear in the human references (upping the Blue), but also missing many words from its results which do appear in the human references.
BTW, there's something called brevity penalty, which is quite important and has already been added to standard Bleu implementations. It penalizes system results which are shorter than the general length of a reference (read more about it here). This complements the n-gram metric behavior which in effect penalizes longer than reference results, since the denominator grows the longer the system result is.
You could also implement something similar for Rouge, but this time penalizing system results which are longer than the general reference length, which would otherwise enable them to obtain artificially higher Rouge scores (since the longer the result, the higher the chance you would hit some word appearing in the references). In Rouge we divide by the length of the human references, so we would need an additional penalty for longer system results which could artificially raise their Rouge score.
Finally, you could use the F1 measure to make the metrics work together:
F1 = 2 * (Bleu * Rouge) / (Bleu + Rouge)