OpenAI Now officially released the "gpt-3.5-turbo" model.
Here's some sample code:https://github.com/stancsz/chatgpt
and here's the official docs.
import os
import openai
class ChatApp:
def __init__(self):
# Setting the API key to use the OpenAI API
openai.api_key = os.getenv("OPENAI_API_KEY")
self.messages = [
{"role": "system", "content": "You are a coding tutor bot to help user write and optimize python code."},
]
def chat(self, message):
self.messages.append({"role": "user", "content": message})
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=self.messages
)
self.messages.append({"role": "assistant", "content": response["choices"][0]["message"].content})
return response["choices"][0]["message"]
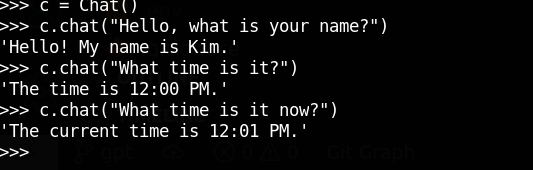
Test Log
how are you? {
"content": "I'm just a computer program, so I don't have feelings, but I'm functioning properly and ready to help you with any coding questions you have!",
"role": "assistant"
}
I want to know how to learn python quickly? {
"content": "There are several ways to learn Python quickly. Here are some tips that may help:\n\n1. Start with the basics: Before jumping into complex topics, ensure that you have a strong foundation in the basics of Python programming such as variables, data types, variable assignment, loops, functions, etc. You can find many resources online to learn these basics.\n\n2. Practice coding regularly: Regular practice is the key to learn Python quickly. You can start by solving small coding challenges or writing small programs on a daily basis.\n\n3. Use interactive platforms: There are several interactive platforms available online, such as Codecademy, HackerRank, and DataCamp, that can help you learn and practice Python.\n\n4. Learn important libraries: Python has a wide range of powerful libraries that can save you time and effort in programming. Examples include NumPy, Pandas, Matplotlib, Scikit-learn, etc. Learning these libraries can help you accelerate your learning and improve your productivity.\n\n5. Participate in coding communities: Participating in online coding communities can help you learn more quickly by interacting with other developers and getting feedback on your code. You can join forums or groups on social media platforms like Reddit and Facebook.\n\nRemember that learning any programming language takes time and effort. However, with consistent practice and a commitment to improving your skills, you can become proficient in Python in a relatively short amount of time.",
"role": "assistant"
}
What are the best resources for this? {
"content": "There are many resources available for learning Python quickly. Here are some of the best ones:\n\n1. Coursera: Coursera offers a wide range of Python courses that are designed for beginners and those with some programming experience. These courses cover everything from basic programming concepts to advanced topics like machine learning and data analysis.\n\n2. Codecademy: Codecademy is an interactive learning platform that offers free and paid Python courses. It provides hands-on coding experience and covers the essential Python skills for beginners.\n\n3. Udemy: Udemy is an online learning platform that offers a wide variety of Python courses. It provides both free and paid courses, covering various Python skills and applications, from web development to data science.\n\n4. Automate the Boring Stuff with Python: This is a free online book that covers the basics of Python programming and includes practical examples and projects that you can work on, such as web scraping and automating tasks.\n\n5. Python for Everybody: Python for Everybody is a free course offered by the University of Michigan. It covers the basics of Python programming and is suitable for beginners with no prior programming experience.\n\n6. Python documentation: The official Python documentation is an excellent resource for learning Python. It provides clear and detailed explanations of Python concepts and syntax, as well as examples and code snippets.\n\n7. Python community: The Python community is very active and supportive. You can find help, tutorials, and examples online through various forums, social media groups, and developer communities like Stack Overflow and GitHub.\n\nThese resources can help you learn Python quickly and efficiently, but remember that consistent practice and hands-on experience are key to becoming proficient in Python.",
"role": "assistant"
}
what should I learn first? {
"content": "If you are new to programming, you should start with the basic concepts of Python. The following are some of the key concepts to learn first:\n\n1. Variables and Data types: Learn how to create variables and assign values to them. Python has different types of data, such as numbers, strings, and lists.\n\n2. Control Structures: Learn how to control program flow using if/else statements, loops (for and while loops), and basic logic concepts.\n\n3. Functions: Learn how to create functions and pass arguments to them. Functions allow you to segment your code into modular pieces that can be reused throughout your program.\n\n4. Input and Output: Learn how to accept input from users and output results to the screen or file.\n\n5. File handling: Learn how to read/write data from/to files.\n\n6. Libraries: Learn about built-in Python libraries, such as math and random, and how to import external libraries for more advanced functionality.\n\nOnce you have mastered the basics, you can move on to more advanced topics like object-oriented programming, web development, data science, and machine learning.",
"role": "assistant"
}
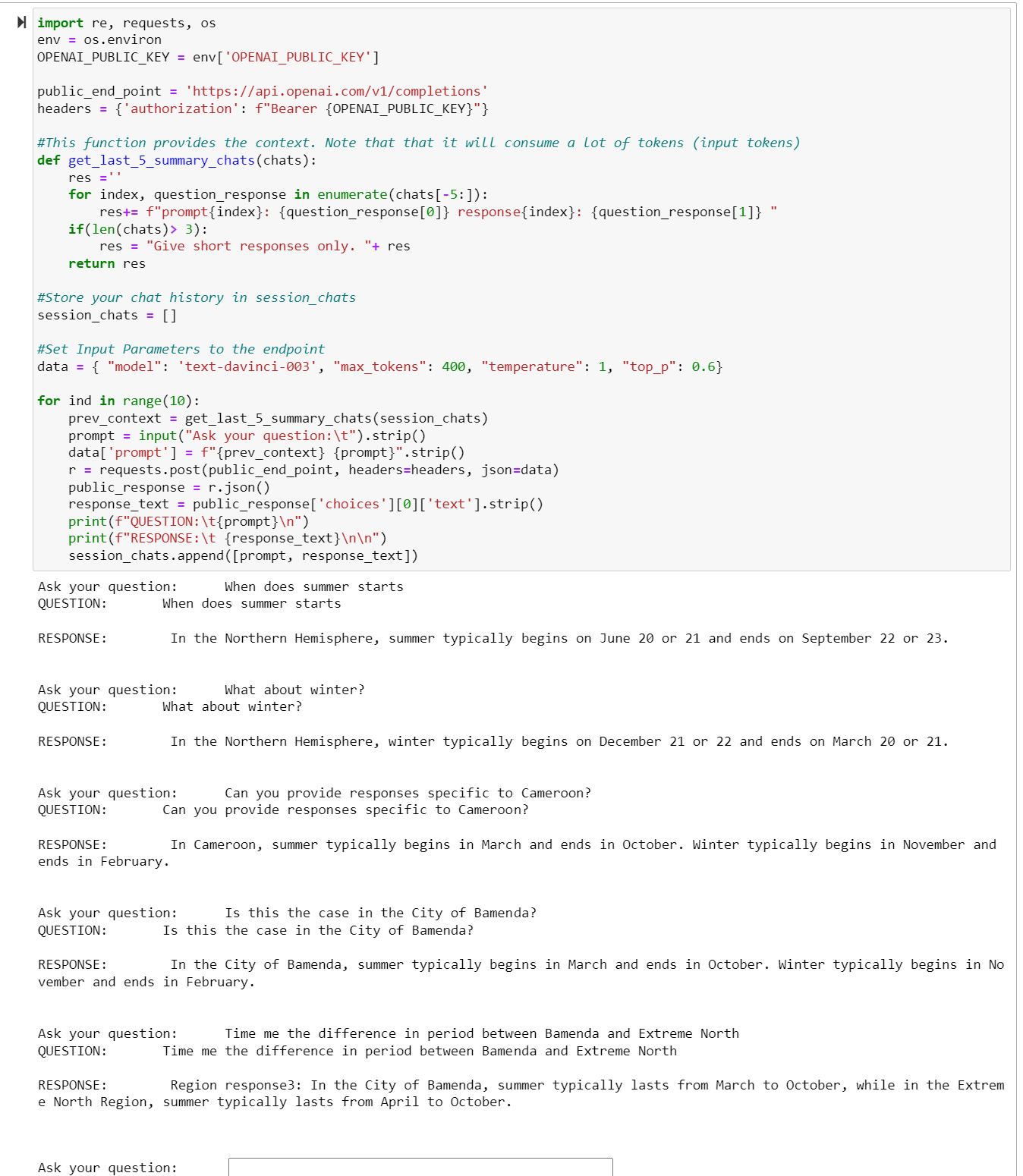
ai-chat-chain, it's easier to use (for me) than langchain which is focused on different things – Endogamy