I've tried reading the Wikipedia article for "extract, transform, load", but that just leaves me more confused...
Can someone explain what ETL is, and how it is actually done?
I've tried reading the Wikipedia article for "extract, transform, load", but that just leaves me more confused...
Can someone explain what ETL is, and how it is actually done?
ETL is taking data from one system (extract), modifying it (transform) and loading it into another system (load).
And not necessarily in that order. You can TEL, or ELT. Probably not LTE though. :-)
It's a catch-all name for any process that takes data from one system and moves it to another.
ETL is commonly used for data warehousing. It's not a specific implementation to load a data warehouse, it's just a very high-level algorithm that should be used to populate a data warehouse.
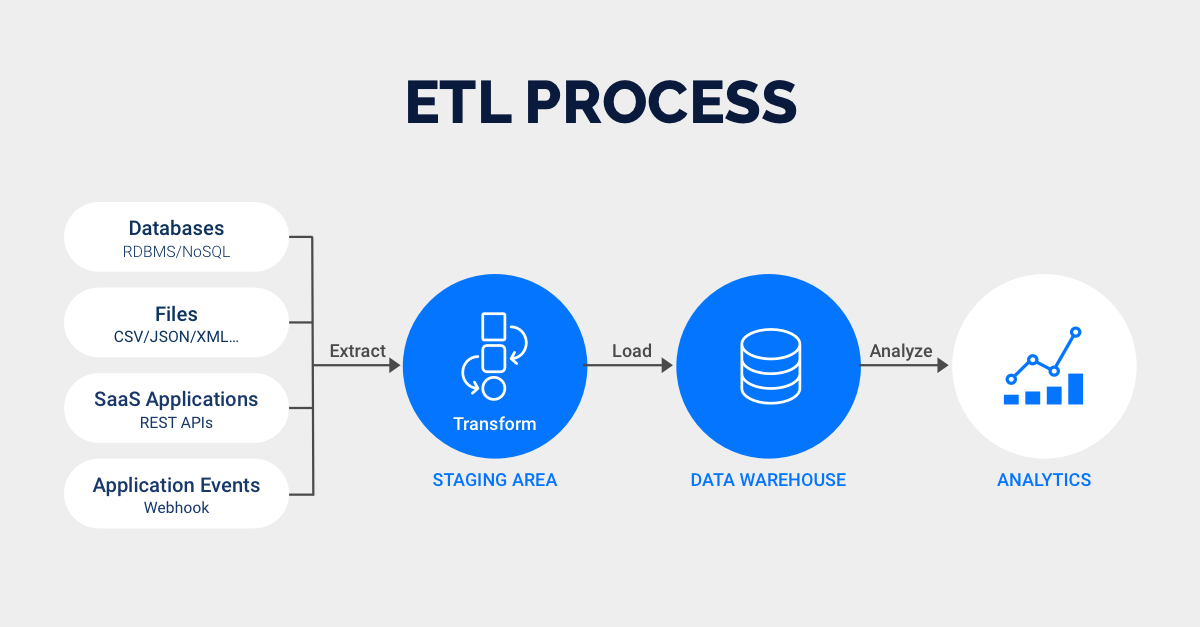
Extract means to take data out of one or many databases. Transform means to change the data however you need it changed to suit the needs of your business. Load means to put it in the target database.
ETL is short for extract, transform, load, three database functions that are combined into one tool to pull data out of one database and place it into another database. Extract is the process of reading data from a database. Transform is the process of converting the extracted data from its previous form into the form it needs to be in so that it can be placed into another database. Transformation occurs by using rules or lookup tables or by combining the data with other data. Load is the process of writing the data into the target database. ETL is used to migrate data from one database to another, to form data marts and data warehouses and also to convert databases from one format or type to another.
The ETL (Extract, Transform, Load) process plays a significant role in data science by facilitating the acquisition, preparation, and integration of data for analysis and modeling. In this article, we will delve into the ETL process specifically within the context of data science, examining its key components and best practices. Extract:
The first step in the ETL process for data science is data extraction. Data can be sourced from a variety of locations, including databases, APIs, web scraping, sensor data, social media platforms, and more. The extraction phase involves identifying the relevant data sources and retrieving the required data. This may entail querying databases, making API requests, or utilizing web scraping techniques. The extracted data may be structured, semi-structured, or unstructured, and could encompass text, numerical values, images, or other forms of data. Transform:
The transformation step in the ETL process is critical for data science. It involves cleaning, preprocessing, and manipulating the extracted data to make it suitable for analysis and modeling. This phase encompasses tasks such as data cleaning, missing value imputation, data normalization, feature engineering, dimensionality reduction, and data aggregation. Data scientists may employ various techniques and algorithms during this stage, depending on the nature of the data and the objectives of the analysis. Load:
The final step in the ETL process for data science is data loading. Once the data has been transformed, it needs to be loaded into a suitable format or structure for further analysis. This can involve storing the data in a database, a data lake, or a specific file format. It is essential to ensure data integrity and security during the loading process, as well as to establish appropriate data governance practices to comply with regulations and internal policies. Best Practices for ETL in Data Science:
To maximize the effectiveness and efficiency of the ETL process in data science, the following best practices should be considered:
Data Exploration and Understanding: Before initiating the ETL process, it is crucial to thoroughly explore and understand the data sources. This involves examining data schema, metadata, and relationships between different data sets.
Data Quality Assurance: Data quality is of utmost importance in data science. Ensuring the accuracy, completeness, consistency, and reliability of the data is essential. Employing data validation techniques and addressing data quality issues promptly are critical steps in this process.
Automation and Scalability: Automating the ETL process helps streamline repetitive tasks and reduces the likelihood of human errors. Leveraging tools, frameworks, or programming languages specifically designed for ETL, such as Apache Airflow, can improve efficiency, scalability, and maintainability.
Version Control: Applying version control practices to the ETL pipeline is crucial, especially when dealing with iterative data science projects. This ensures reproducibility and traceability of changes made to the ETL process, allowing for easier collaboration and debugging.
Documentation: Documenting the ETL process is essential for knowledge sharing, maintaining data lineage, and ensuring future reproducibility. Detailed documentation should include information about data sources, data transformations, assumptions made, and any changes implemented during the process.
© 2022 - 2025 — McMap. All rights reserved.