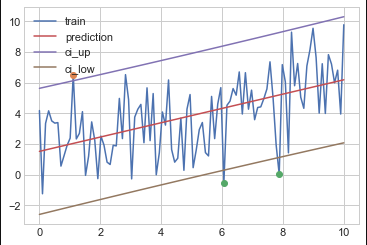
Using the same example as from this previous question (code pasted below), we can get the 95% CI with the summary_table function from statsmodels outliers_influence. But now, how would it be possible to only subset the data points (x and y) that are outside the confidence interval?
import numpy as np
import statsmodels.api as sm
from statsmodels.stats.outliers_influence import summary_table
#measurements genre
n = 100
x = np.linspace(0, 10, n)
e = np.random.normal(size=n)
y = 1 + 0.5*x + 2*e
X = sm.add_constant(x)
re = sm.OLS(y, X).fit()
st, data, ss2 = summary_table(re, alpha=0.05)
predict_ci_low, predict_ci_upp = data[:, 6:8].T