I noticed that the Consumer configuration has two IDs. One is group.id (mandatory) and second one is consumer.id (not Mandatory).
What is the difference between these 2 IDs?
I noticed that the Consumer configuration has two IDs. One is group.id (mandatory) and second one is consumer.id (not Mandatory).
What is the difference between these 2 IDs?
Consumers groups is a Kafka abstraction that enables supporting both point-to-point and publish/subscribe messaging. A consumer can join a consumer group (let us say group_1) by setting its group.id to group_1. Consumer groups is also a way of supporting parallel consumption of the data i.e. different consumers of the same consumer group consume data in parallel from different partitions.
In addition to group.id, each consumer also identifies itself to the Kafka broker using consumer.id. This is used by Kafka to identify the currently ACTIVE consumers of a particular consumer group.
Read this documentation for more details.
consumer.id, description states "Generated automatically if not set." I assume this probably means if manually set, consumer.id should be unique for each consumer? Curious to wonder what happens if you reuse the consumer ID across consumers (like how one shares the consumer group ID) - problems arise or it will work fine but just messy for tracking/debugging active consumers in the group? –
Allain consumer.id in the documentation. Has it been replaced by client_id? but then it is same for every consumer by default. –
Progestin The figure below describes the difference between group.id and consumer.id really well.
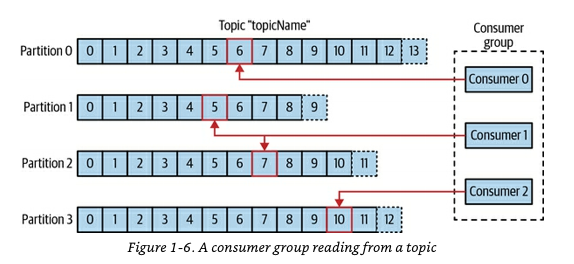
In this example, we have one topic with four partitions, one consumer group and three consumers inside the consumer group. Consumer 0 and consumer 2 read from one partition each, whereas consumer 1 reads from two partitions.
The group.id is equal to Consumer group. Your group.id always represents a unique name/ID of your consumer group across your Kafka cluster. A consumer group can have one or multiple consumers, but only as many consumers as partitions are available in the topic.
Here we have four partitions and three consumers joined the consumer group: Consumer 0, Consumer 1 and Consumer 2. Each ID (or name) of a consumer represents the consumer.id. We can have a maximum of four consumers (i.e. consumer.ids) because the topic has four partitions.
Each consumer has a unique consumer.id across its consumer group. If you don't define a consumer.id, the Kafka client (Java, Python, Node.js, etc) usually chooses a random ID.
Another good example to understand the relationship between group.id and consumer.id is the following figure:

Topic T1 has four partitions, and two consumer groups exist, group 1 and group 2. Group 1 holds four consumers (maxed out), while group 2 holds two consumers (space for 2 more consumers). Both consumers in group 2 read from two partitions each. In group 1, each consumer just reads from one partition.
This is a good example showcasing why we cannot have two or more consumer groups (group.ids) with the same name. If Kafka allows groups to have the same name, the offset tracking for a partition would get out of whack because a consumer in group 1 would overwrite the offset of a consumer in group 2 (and vice versa).
group.id
specifies the name of the consumer group a Kafka consumer belongs to.
When the Kafka consumer is constructed and group.id does not exist yet (i.e. there are no existing consumers that are part of the group), the consumer group will be created automatically.
A unique string that identifies the consumer group this consumer belongs to. This property is required if the consumer uses either the group management functionality by using subscribe(topic) or the Kafka-based offset management strategy.
Type: string
Default: null
Valid Values:
Importance: high
Consumer id
Each consumer has a unique consumer.id across its consumer group. If you don't define a consumer.id, the Kafka client (Java, Python, Node.js, etc) usually chooses a random ID.
© 2022 - 2025 — McMap. All rights reserved.