Why would you save something that you can't retrieve later on? What's the point?
What is the purpose of MySQL's BLACKHOLE Engine?
It is useful in a replicated environment where all SQL statements are run on all nodes, but you only want some nodes to actually store the result. This is a use case given in the documentation: http://dev.mysql.com/doc/refman/5.0/en/blackhole-storage-engine.html
Other uses given in the documentation include:
- Verification of dump file syntax.
- Measurement of the overhead from binary logging, by comparing performance using BLACKHOLE with and without binary logging enabled.
- BLACKHOLE is essentially a “no-op” storage engine, so it could be used for finding performance bottlenecks not related to the storage engine itself.
Suppose you have two computers, each running a MySQL server. One computer hosts the primary database, and the second computer hosts a replicating slave that you use as a backup.
Additionally suppose that your primary server contains some databases or tables that you don't want to back up. Perhaps they're high-churn cache tables and it doesn't matter if you lose their content. So, to save disk space and avoid needless use of CPU, memory and disk IO, you use the replication options to configure the slave to ignore statements that affect the tables you don't want backed up.
But since the replication filters only get applied on the slave server, the binlogs for all statements executed on the master server still need to be transmitted over the network. There's bandwidth being wasted here; the master server is sending binlogs for transactions that the slave is simply going to throw away upon receiving them. Can we do better, and avoid the needless bandwidth usage?
Yes, we can, and that's where the BLACKHOLE engine comes in. On the same computer that the master server is running on, we run a second, dummy mysqld process, this one hosting a BLACKHOLE database. We configure this dummy process to replicate from the master process's binlog, with the same replication options as the real slave, and to produce a binlog of its own. The dummy process's binlog now only contains the statements that the real slave needs, and it hasn't done any actual work beyond filtering out the unwanted statements from the binlog (since it's using the BLACKHOLE engine). Finally, we configure the true slave to replicate from the dummy process's binlog, rather than from the original master process's binlog. We've now eliminated the needless network traffic between the two computers hosting the master and slave servers.
This setup is what's being described and illustrated (much more tersely) by this paragraph and diagram from the BLACKHOLE docs:
Suppose that your application requires slave-side filtering rules, but transferring all binary log data to the slave first results in too much traffic. In such a case, it is possible to set up on the master host a “dummy” slave process whose default storage engine is BLACKHOLE, depicted as follows:
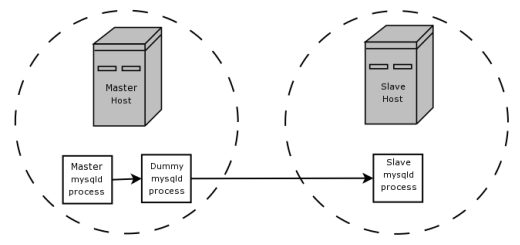
Besides filtering, the docs also cryptically hint that using a BLACKHOLE server with binlogging enabled "can be useful as a repeater ... mechanism". This use case is fleshed out less in the docs, but it's possible to imagine a scenario in which this would make sense. For instance, suppose that you have lots of slave servers, all on computers on a local network with fast local connections to each other, that all need to replicate large amounts of data from a remote slave that can only be connected to over the internet. You don't want to have them all replicate directly from the master box, since then you're getting the same data several times over and using several times more internet bandwidth than you have to. But suppose that you also don't want to have just one of your existing slaves replicate from the master and the others replicate off that slave, perhaps because your slaves are running on much less reliable machines than the master, or are running some other processes that might kill the box by eating all its CPU or memory, and you don't want to risk a software or hardware failure on the intermediate slave taking down your whole slave network. What do you do?
One possible compromise would be to introduce an extra box into your slave network to act as the intermediary, optimised for reliability and performance rather than for storage. Give it a small, reliable SSD drive and run nothing on it apart from a mysqld process replicating from the remote master, and have it produce binlogs that the other slaves can subscribe to. And, of course, set up this intermediate slave to use the BLACKHOLE engine, so that it doesn't need storage space.
Both this and the intermediate filtering slave described in detail in the documentation are edge cases; most MySQL users will never find themselves in situations where they'd benefit from using either of these strategies, let alone benefit enough to justify doing the work to actually set them up. But at least theoretically, the BLACKHOLE engine can be used to create an intermediate node in a network of replicating slaves as a bandwidth-conservation strategy, without needing that node to actually store the data on disk.
useful for running trigger on data that you don't want to keep.
for example, mysql currently does not support iterating through results of a query - so you can implement a solution that dos the same job by using "insert into <blackhole_table> (select col1, col2, col3 from <some_other_table> where )"
then add am on-insert trigger to that blackhole table that does the task that you want to do in a 'for each' action of the selected data.
blackhole does not store the results, so no need to clean up afterward and you end up with a simple solution to for-each..
As it’s currently written, your answer is unclear. Please edit to add additional details that will help others understand how this addresses the question asked. You can find more information on how to write good answers in the help center. –
Urbannai
© 2022 - 2024 — McMap. All rights reserved.