This is similar to to this question which doesn't have any answers. I've read all about how to use cursors with the twitter, facebook, and disqus api's and also this article about how disqus generally built their cursors, but I still cannot seem to grok the concept of how they work and how to implement a similar solution in my own projects. Can someone explain specifically the different techniques and concepts behind them?
How to implement cursors for pagination in an api
Asked Answered
Lets first understand why offset pagination fails for large data sets with an example. The following quotes are taken from this wonderful engineering article from Slack by Michael Hahn.
Clients provide two parameters limit for number of results and offset and for page offset.
For example, with offset = 40, limit = 20, we can tell the database to return the next 20 items, skipping the first 40.
Drawbacks:
- Using LIMIT OFFSET doesn’t scale well for large datasets. As the offset increases the farther you go within the dataset, the database still has to read up to offset + count rows from disk, before discarding the offset and only returning count rows.
- If items are being written to the dataset at a high frequency, the page window becomes unreliable, potentially skipping or returning
duplicate results.
How Cursors solve this ?
Cursor-based pagination works by returning a pointer to a specific item in the dataset. On subsequent requests, the server returns results after the given pointer.
We will use parameters next_cursor along with limit as the parameters provided by client in this case.
Let’s assume we want to paginate from the most recent user to the oldest user.When client request for the first time , suppose we select the first page through query:
SELECT * FROM users WHERE team_id = %team_id ORDER BY id DESC LIMIT %limitWhere limit is equal to limit plus one, to fetch one more result than the count specified by the client. The extra result isn’t returned in the result set, but we use the ID of the value as the next_cursor.
The response from the server would be:
{ "users": [...], "next_cursor": "1234", # the user id of the extra result }The client would then provide next_cursor as cursor in the second request.
SELECT * FROM users WHERE team_id = %team_id AND id <= %cursor ORDER BY id DESC LIMIT %limitWith this, we’ve addressed the drawbacks of offset based pagination:
- Instead of the window being calculated from scratch on each request based on the total number of items, we’re always fetching the next count rows after a specific reference point. If items are being written to the dataset at a high frequency, the overall position of the cursor in the set might change, but the pagination window adjusts accordingly.
- This will scale well for large datasets. We’re using a WHERE clause to fetch rows with id values less than the last id from the previous page. This lets us leverage the index on the column and the database doesn’t have to read any rows that we’ve already seen.
How to bite it with sorting? –
Cella
Maybe citing the source would have be nice : slack.engineering/evolving-api-pagination-at-slack-1c1f644f8e12 –
Trotman
@Trotman Thanks for pointing that out. Already had mentioned this in #13872773 one, but forgot here. Have edited! –
Kiangsu
@ShubhamSrivastava you copy and pasted the a significant part of the article - in the future please start your answer by citing the original author. –
Allodial
@Allodial As mentioned above it was my fault not to mention the source which i rectified. The answer is to serve the purpose of not going through the whole article, so yeah I tried to separate the piece which can be relevant to the question. Anyways thanks for the suggestion. –
Kiangsu
It doesn't work with sorting options other than by id. Here's explanation why - gist.github.com/MarkMurphy/… –
Essy
How are you supposed to go backwards? How can you test if a next set of results exists? –
Timberland
You change to id >= %cursor and use ASC. If +1 record comes from the query then next/previous exists –
Inferno
copy and paste, I guess he really has no idea –
Harping
@Trotman - I did not understand what the author meant in the slack post. Copying from the post, can you elaborate on this please? - "Requiring the cursor to be a string value promotes the use of an opaque cursor value. The javascript implementation of the Relay spec for instance uses Base64 encoded IDs as cursor values. This discourages the client from implying what value goes in this field and gives the server the ability to encode additional information within the cursor." –
Petulance
Here is an article about pagination: paginating-real-time-data-cursor-based-pagination
Cursors – we need to have at least one column with unique sequential values to implement cursor based pagination. This can be similar to Twitter’s max_id parameter or Facebook’s after parameter.
In general you should pass the current item or page number in the request as a param. Other usual param is the batch size of the page. Then on the server side backend you select and return the proper dataset, with an SQL query for example.
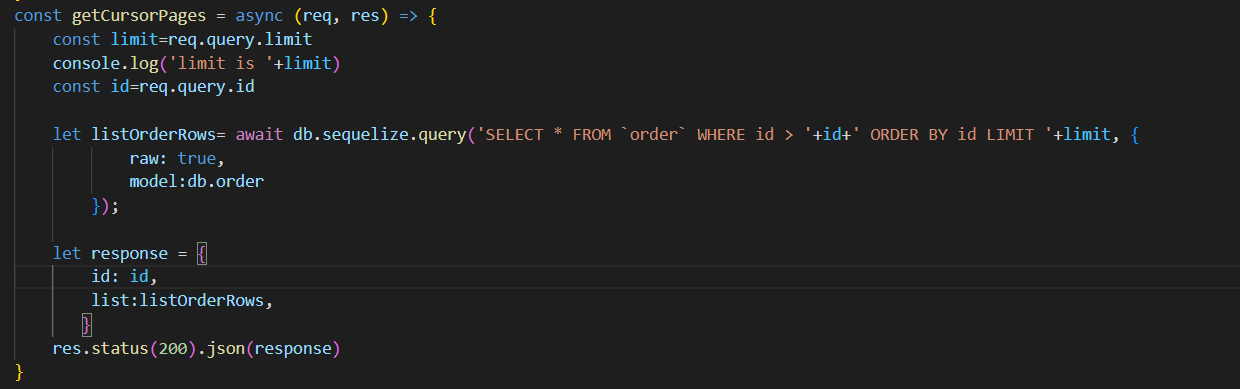
enter image description hereHere's what I am Done with. The cursor is working as a pointer and it points to that index. and limit will pick that many rows from that pointer. Let's say we have given id 10 and limit 5 then it will go to id 10 and pick 5 elements from there.
{kind=link}
Please post your code directly to the answer, no need of adding extra URLs that can become invalid in future. –
Zoology
Some Graph API connections uses cursors by default. You can use 'limit' and 'before'/'after' parameters in your call. If you are still not clear, you can post your code here and I can explain with it.
I still don't understand how cursors are built for pagination. What cursors mean? How do you relate them with pagination results? –
Agnail
© 2022 - 2024 — McMap. All rights reserved.