I've created a ubuntu single node hadoop cluster in EC2.
Testing a simple file upload to hdfs works from the EC2 machine, but doesn't work from a machine outside of EC2.
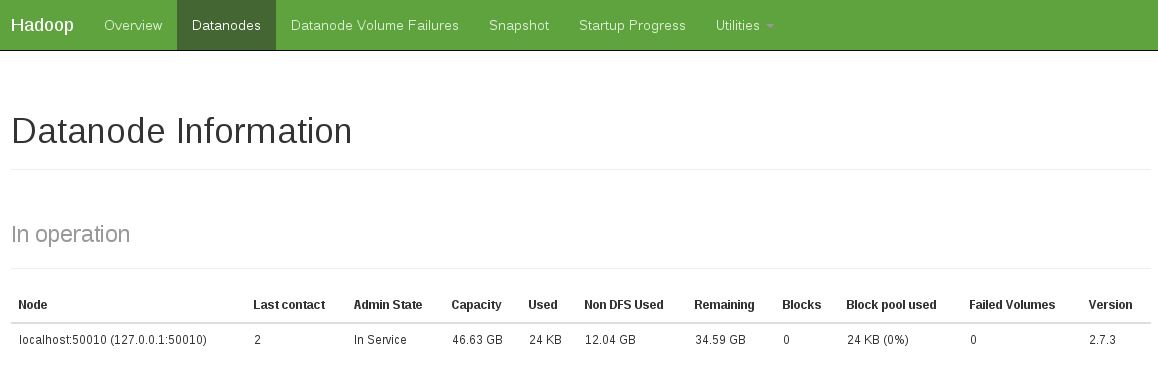
I can browse the the filesystem through the web interface from the remote machine, and it shows one datanode which is reported as in service. Have opened all tcp ports in the security from 0 to 60000(!) so I don't think it's that.
I get the error
java.io.IOException: File /user/ubuntu/pies could only be replicated to 0 nodes, instead of 1
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:1448)
at org.apache.hadoop.hdfs.server.namenode.NameNode.addBlock(NameNode.java:690)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.apache.hadoop.ipc.WritableRpcEngine$Server.call(WritableRpcEngine.java:342)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1350)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1346)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:396)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:742)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:1344)
at org.apache.hadoop.ipc.Client.call(Client.java:905)
at org.apache.hadoop.ipc.WritableRpcEngine$Invoker.invoke(WritableRpcEngine.java:198)
at $Proxy0.addBlock(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:82)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:59)
at $Proxy0.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.locateFollowingBlock(DFSOutputStream.java:928)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:811)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:427)
namenode log just gives the same error. Others don't seem to have anything interesting
Any ideas?
Cheers
conf/core-site.xml,conf/mapred-site.xmlandconf/hdfs-site.xml. It works fine on my VM. Disclaimer: I am an absolute beginner. I think these changes leads to a default values for a single instance and that made it work. HTH. – Electrothermal