How do you make an AWS S3 public folder private again?
I was testing out some staging data, so I made the entire folder public within a bucket. I'd like to restrict its access again. So how do I make the folder private again?
How do you make an AWS S3 public folder private again?
I was testing out some staging data, so I made the entire folder public within a bucket. I'd like to restrict its access again. So how do I make the folder private again?
From what I understand, the 'Make public' option in the managment console recursively adds a public grant for every object 'in' the directory. You can see this by right-clicking on one file, then click on 'Properties'. You then need to click on 'Permissions' and there should be a line:
Grantee: Everyone [x] open/download [] view permissions [] edit permission.
If you upload a new file within this directory it won't have this public access set and therefore be private.
You need to remove public read permission one by one, either manually if you only have a few keys or by using a script.
I wrote a small script in Python with the 'boto' module to recursively remove the 'public read' attribute of all keys in a S3 folder:
#!/usr/bin/env python
#remove public read right for all keys within a directory
#usage: remove_public.py bucketName folderName
import sys
import boto3
BUCKET = sys.argv[1]
PATH = sys.argv[2]
s3client = boto3.client("s3")
paginator = s3client.get_paginator('list_objects_v2')
page_iterator = paginator.paginate(Bucket=BUCKET, Prefix=PATH)
for page in page_iterator:
keys = page['Contents']
for k in keys:
response = s3client.put_object_acl(
ACL='private',
Bucket=BUCKET,
Key=k['Key']
)
I tested it in a folder with (only) 2 objects and it worked. If you have lots of keys it may take some time to complete and a parallel approach might be necessary.
The accepted answer works well - seems to set ACLs recursively on a given s3 path too. However, this can also be done more easily by a third-party tool called s3cmd - we use it heavily at my company and it seems to be fairly popular within the AWS community.
For example, suppose you had this kind of s3 bucket and dir structure: s3://mybucket.com/topleveldir/scripts/bootstrap/tmp/. Now suppose you had marked the entire scripts "directory" as public using the Amazon S3 console.
Now to make the entire scripts "directory-tree" recursively (i.e. including subdirectories and their files) private again:
s3cmd setacl --acl-private --recursive s3://mybucket.com/topleveldir/scripts/
It's also easy to make the scripts "directory-tree" recursively public again if you want:
s3cmd setacl --acl-public --recursive s3://mybucket.com/topleveldir/scripts/
You can also choose to set the permission/ACL only on a given s3 "directory" (i.e. non-recursively) by simply omitting --recursive in the above commands.
For s3cmd to work, you first have to provide your AWS access and secret keys to s3cmd via s3cmd --configure (see http://s3tools.org/s3cmd for more details).
s3cmd --access_key $AWS_ACCESS_KEY_ID --secret_key $AWS_SECRET_ACCESS_KEY setacl --acl-private -r s3://$S3_BUCKET_NAME/*.map ? –
Concessionaire From what I understand, the 'Make public' option in the managment console recursively adds a public grant for every object 'in' the directory. You can see this by right-clicking on one file, then click on 'Properties'. You then need to click on 'Permissions' and there should be a line:
Grantee: Everyone [x] open/download [] view permissions [] edit permission.
If you upload a new file within this directory it won't have this public access set and therefore be private.
You need to remove public read permission one by one, either manually if you only have a few keys or by using a script.
I wrote a small script in Python with the 'boto' module to recursively remove the 'public read' attribute of all keys in a S3 folder:
#!/usr/bin/env python
#remove public read right for all keys within a directory
#usage: remove_public.py bucketName folderName
import sys
import boto3
BUCKET = sys.argv[1]
PATH = sys.argv[2]
s3client = boto3.client("s3")
paginator = s3client.get_paginator('list_objects_v2')
page_iterator = paginator.paginate(Bucket=BUCKET, Prefix=PATH)
for page in page_iterator:
keys = page['Contents']
for k in keys:
response = s3client.put_object_acl(
ACL='private',
Bucket=BUCKET,
Key=k['Key']
)
I tested it in a folder with (only) 2 objects and it worked. If you have lots of keys it may take some time to complete and a parallel approach might be necessary.
For AWS CLI, it is fairly straight forward.
If the object is: s3://<bucket-name>/file.txt
For single object:
aws s3api put-object-acl --acl private --bucket <bucket-name> --key file.txt
For all objects in the bucket (bash one-liner):
aws s3 ls --recursive s3://<bucket-name> | cut -d' ' -f5- | awk '{print $NF}' | while read line; do
echo "$line"
aws s3api put-object-acl --acl private --bucket <bucket-name> --key "$line"
done
From the AWS S3 bucket listing (The AWS S3 UI), you can modify individual file's permissions after making either one file public manually or by making the whole folder content public (To clarify, I'm referring to a folder inside a bucket). To revert the public attribute back to private, you click on the file, then go to permissions and click in the radial button under "EVERYONE" heading. You get a second floating window where you can uncheck the *read object" attribute. Don't forget to save the change. If you try to access the link, you should get the typical "Access Denied" message. I have attached two screenshots. The first one shows the folder listing. Clicking the file and following the aforementioned procedure should show you the second screenshot, which shows the 4 steps. Notice that to modify multiple files, one would need to use the scripts as proposed in previous posts. -Kf
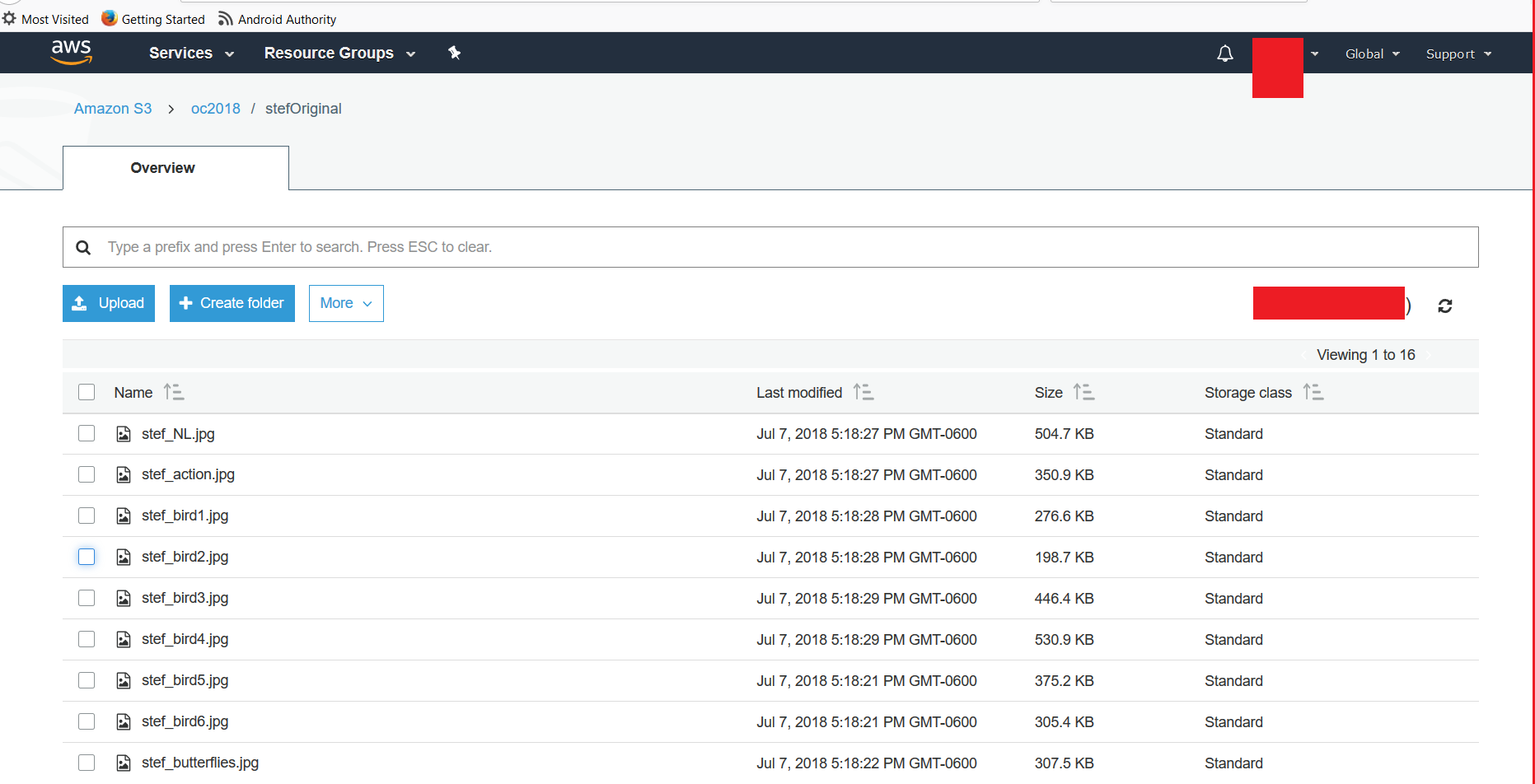
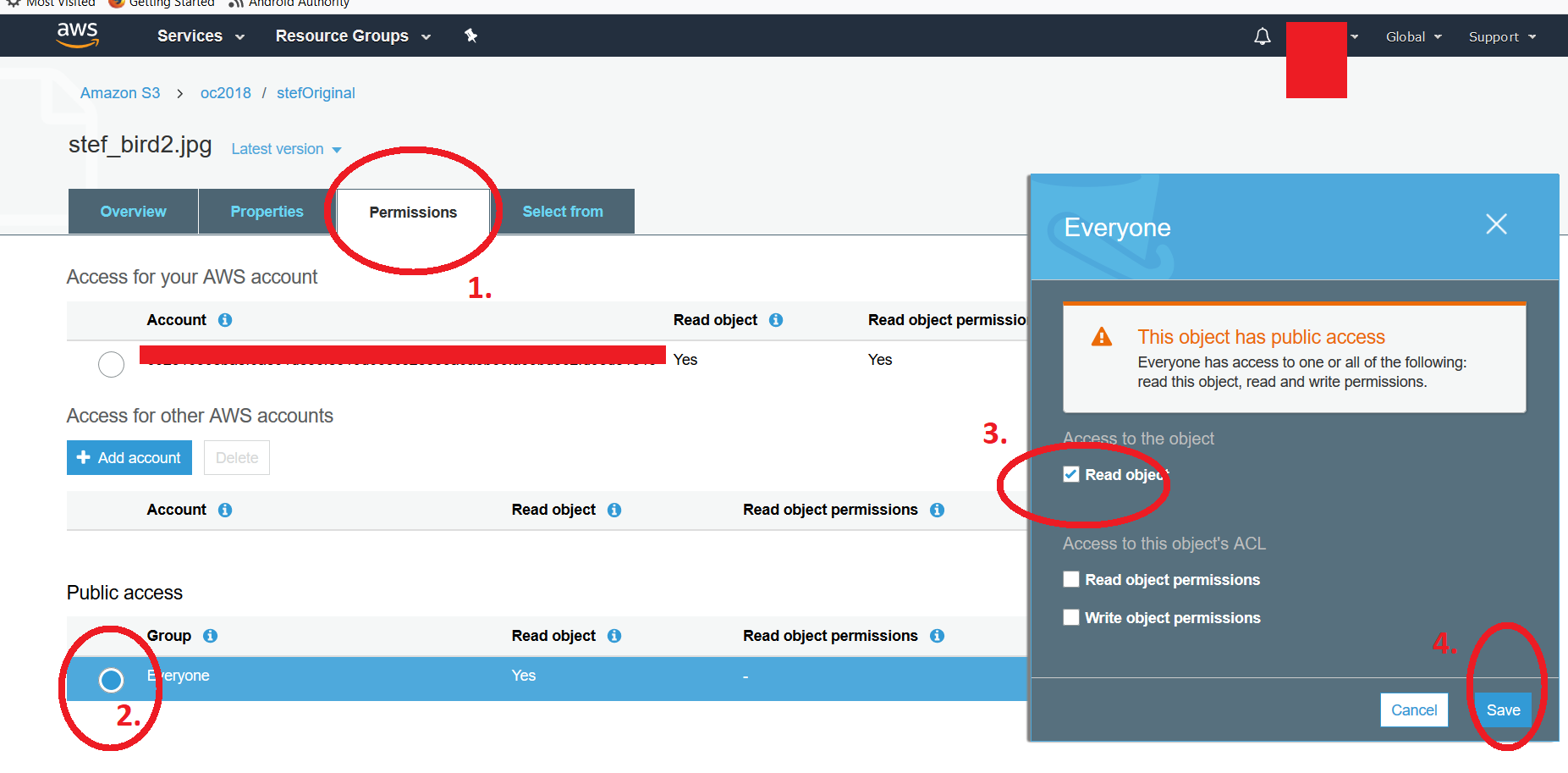
I actually used Amazon's UI following this guide http://aws.amazon.com/articles/5050/

While @Varun Chandak's answer works great, it's worth mentioning that, due to the awk part, the script only accounts for the last part of the ls results. If the filename has spaces in it, awk will get only the last segment of the filename split by spaces, not the entire filename.
Example: A file with a path like folder1/subfolder1/this is my file.txt would result in an entry called just file.txt.
In order to prevent that while still using his script, you'd have to replace $NF in awk {print $NF} by a sequence of variable placeholders that accounts for the number of segments that the 'split by space' operation would result in. Since filenames might have a quite large number of spaces in their names, I've gone with an exaggeration, but to be honest, I think a completely new approach would probably be better to deal with these cases. Here's the updated code:
#!/bin/sh
aws s3 ls --recursive s3://my-bucket-name | awk '{print $4,$5,$6,$7,$8,$9,$10,$11,$12,$13,$14,$15,$16,$17,$18,$19,$20,$21,$22,$23,$24,$25}' | while read line; do
echo "$line"
aws s3api put-object-acl --acl private --bucket my-bucket-name --key "$line"
done
I should also mention that using cut didn't have any results for me, so I removed it. Credits still go to @Varun Chandak, since he built the script.
As of now, according to the boto docs you can do it this way
#!/usr/bin/env python
#remove public read right for all keys within a directory
#usage: remove_public.py bucketName folderName
import sys
import boto
bucketname = sys.argv[1]
dirname = sys.argv[2]
s3 = boto.connect_s3()
bucket = s3.get_bucket(bucketname)
keys = bucket.list(dirname)
for k in keys:
# options are 'private', 'public-read'
# 'public-read-write', 'authenticated-read'
k.set_acl('private')
Also, you may consider to remove any bucket policies under permissions tab of s3 bucket.
I did this today. My situation was I had certain top level directories whose files needed to be made private. I did have some folders that needed to be left public.
I decided to use the s3cmd like many other people have already shown. But given the massive number of files, I wanted to run parallel s3cmd jobs for each directory. And since it was going to take a day or so, I wanted to run them as background processes on an EC2 machine.
I set up an Ubuntu machine using the t2.xlarge type. I chose the xlarge after s3cmd failed with out of memory messages on a micro instance. xlarge is probably overkill but this server will only be up for a day.
After logging into the server, I installed and configured s3cmd:
sudo apt-get install python-setuptools
wget https://sourceforge.net/projects/s3tools/files/s3cmd/2.0.2/s3cmd-2.0.2.tar.gz/download
mv download s3cmd.tar.gz
tar xvfz s3cmd.tar.gz
cd s3cmd-2.0.2/
python setup.py install
sudo python setup.py install
cd ~
s3cmd --configure
I originally tried using screen but had some problems, mainly processes were dropping from screen -r despite running the proper screen command like screen -S directory_1 -d -m s3cmd setacl --acl-private --recursive --verbose s3://my_bucket/directory_1. So I did some searching and found the nohup command. Here's what I ended up with:
nohup s3cmd setacl --acl-private --recursive --verbose s3://my_bucket/directory_1 > directory_1.out &
nohup s3cmd setacl --acl-private --recursive --verbose s3://my_bucket/directory_2 > directory_2.out &
nohup s3cmd setacl --acl-private --recursive --verbose s3://my_bucket/directory_3 > directory_3.out &
With a multi-cursor error this becomes pretty easy (I used aws s3 ls s3//my_bucket to list the directories).
Doing that you can logout as you want, and log back in and tail any of your logs. You can tail multiple files like:
tail -f directory_1.out -f directory_2.out -f directory_3.out
So set up s3cmd then use nohup as I demonstrated and you're good to go. Have fun!
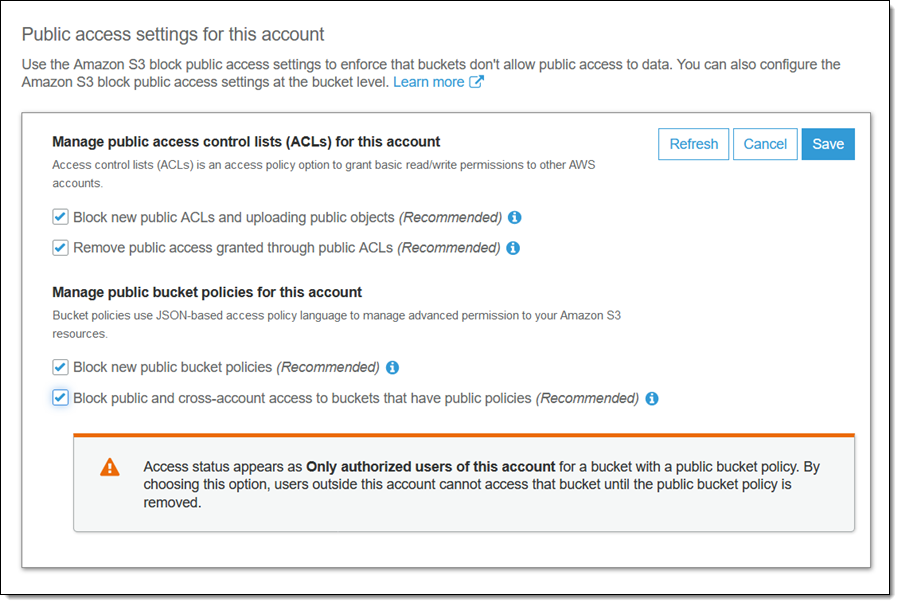
It looks like that this is now addressed by Amazon:
Selecting the following checkbox makes the bucket and its contents private again:
Block public and cross-account access if bucket has public policies
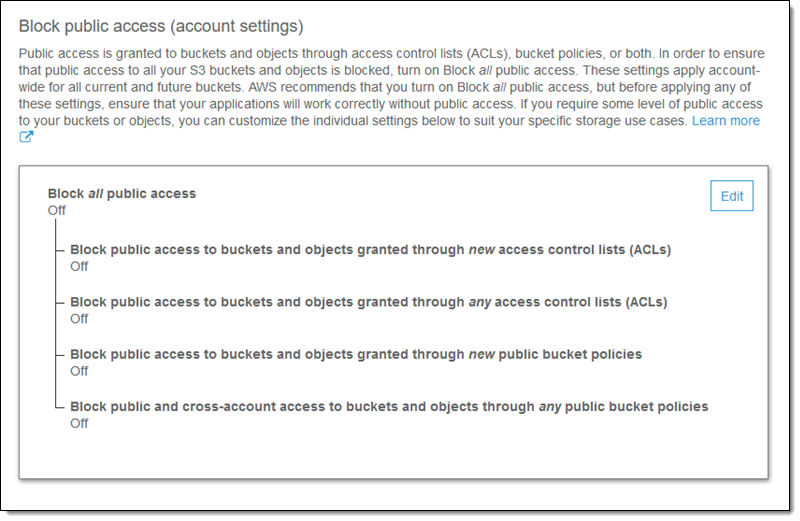
UPDATE: The above link was updated August 2019. The options in the image above no longer exist. The new options are in the image below.
If you have S3 Browser, you will be having an option to make it public or private.
If you want a delightfully simple one-liner, you can use the AWS Powershell Tools. The reference for the AWS Powershell Tools can be found here. We'll be using the Get-S3Object and Set-S3ACL commandlets.
$TargetS3Bucket = "myPrivateBucket"
$TargetDirectory = "accidentallyPublicDir"
$TargetRegion = "us-west-2"
Set-DefaultAWSRegion $TargetRegion
Get-S3Object -BucketName $TargetS3Bucket -KeyPrefix $TargetDirectory | Set-S3ACL -CannedACLName private
There are two ways to manage this:
Make Public option where you can execute the script from ascobol (I just rewrite it with boto3)#!/usr/bin/env python
#remove public read right for all keys within a directory
#usage: remove_public.py bucketName folderName
import sys
import boto3
BUCKET = sys.argv[1]
PATH = sys.argv[2]
s3client = boto3.client("s3")
paginator = s3client.get_paginator('list_objects_v2')
page_iterator = paginator.paginate(Bucket=BUCKET, Prefix=PATH)
for page in page_iterator:
keys = page['Contents']
for k in keys:
response = s3client.put_object_acl(
ACL='private',
Bucket=BUCKET,
Key=k['Key']
)
cheers
Use @ascobol's script, above. Tested with ~2300 items in 1250 subfolders and appears to have worked (lifesaver, thanks!).
I'll provide some additional steps for less experienced folks, but if anyone with more reputation would like to delete this answer and comment on his post stating that it works with 2000+ folders, that'd be fine with me.
python3 --versionpip install boto3remove_public.py, and paste in the contents of @ascobol's scriptpython3 remove_public.py bucketName folderNameScript contents from ascobol's answer, above
#!/usr/bin/env python
#remove public read right for all keys within a directory
#usage: remove_public.py bucketName folderName
import sys
import boto3
BUCKET = sys.argv[1]
PATH = sys.argv[2]
s3client = boto3.client("s3")
paginator = s3client.get_paginator('list_objects_v2')
page_iterator = paginator.paginate(Bucket=BUCKET, Prefix=PATH)
for page in page_iterator:
keys = page['Contents']
for k in keys:
response = s3client.put_object_acl(
ACL='private',
Bucket=BUCKET,
Key=k['Key']
)
© 2022 - 2024 — McMap. All rights reserved.