Although there are several answers already, and an accepted answer, there are still a couple points missing from this topic. First, the consensus seems to be that solving this problem using streams is merely an exercise, and that the conventional for-loop approach is preferable. Second, the answers given thus far have overlooked an approach using array or vector-style techniques that I think improves the streams solution considerably.
First, here's a conventional solution, for purposes of discussion and analysis:
static List<List<String>> splitConventional(List<String> input) {
List<List<String>> result = new ArrayList<>();
int prev = 0;
for (int cur = 0; cur < input.size(); cur++) {
if (input.get(cur) == null) {
result.add(input.subList(prev, cur));
prev = cur + 1;
}
}
result.add(input.subList(prev, input.size()));
return result;
}
This is mostly straightforward but there's a bit of subtlety. One point is that a pending sublist from prev to cur is always open. When we encounter null we close it, add it to the result list, and advance prev. After the loop we close the sublist unconditionally.
Another observation is that this is a loop over indexes, not over the values themselves, thus we use an arithmetic for-loop instead of the enhanced "for-each" loop. But it suggests that we can stream using the indexes to generate subranges instead of streaming over values and putting the logic into the collector (as was done by Joop Eggen's proposed solution).
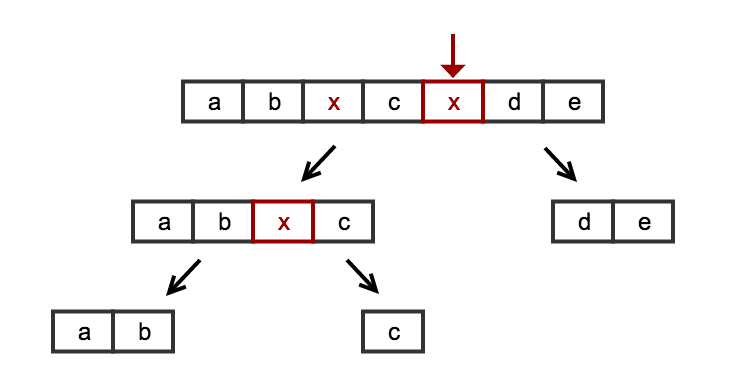
Once we've realized that, we can see that each position of null in the input is the delimiter for a sublist: it's the right end of the sublist to the left, and it (plus one) is the left end of the sublist to the right. If we can handle the edge cases, it leads to an approach where we find the indexes at which null elements occur, map them to sublists, and collect the sublists.
The resulting code is as follows:
static List<List<String>> splitStream(List<String> input) {
int[] indexes = Stream.of(IntStream.of(-1),
IntStream.range(0, input.size())
.filter(i -> input.get(i) == null),
IntStream.of(input.size()))
.flatMapToInt(s -> s)
.toArray();
return IntStream.range(0, indexes.length-1)
.mapToObj(i -> input.subList(indexes[i]+1, indexes[i+1]))
.collect(toList());
}
Getting the indexes at which null occurs is pretty easy. The stumbling block is adding -1 at the left and size at the right end. I've opted to use Stream.of to do the appending and then flatMapToInt to flatten them out. (I tried several other approaches but this one seemed like the cleanest.)
It's a bit more convenient to use arrays for the indexes here. First, the notation for accessing an array is nicer than for a List: indexes[i] vs. indexes.get(i). Second, using an array avoids boxing.
At this point, each index value in the array (except for the last) is one less than the beginning position of a sublist. The index to its immediate right is the end of the sublist. We simply stream over the array and map each pair of indexes into a sublist and collect the output.
Discussion
The streams approach is slightly shorter than the for-loop version, but it's denser. The for-loop version is familiar, because we do this stuff in Java all the time, but if you're not already aware of what this loop is supposed to be doing, it's not obvious. You might have to simulate a few loop executions before you figure out what prev is doing and why the open sublist has to be closed after the end of the loop. (I initially forgot to have it, but I caught this in testing.)
The streams approach is, I think, easier to conceptualize what's going on: get a list (or an array) that indicates the boundaries between sublists. That's an easy streams two-liner. The difficulty, as I mentioned above, is finding a way to tack the edge values onto the ends. If there were a better syntax for doing this, e.g.,
// Java plus pidgin Scala
int[] indexes =
[-1] ++ IntStream.range(0, input.size())
.filter(i -> input.get(i) == null) ++ [input.size()];
it would make things a lot less cluttered. (What we really need is array or list comprehension.) Once you have the indexes, it's a simple matter to map them into actual sublists and collect them into the result list.
And of course this is safe when run in parallel.
UPDATE 2016-02-06
Here's a nicer way to create the array of sublist indexes. It's based on the same principles, but it adjusts the index range and adds some conditions to the filter to avoid having to concatenate and flatmap the indexes.
static List<List<String>> splitStream(List<String> input) {
int sz = input.size();
int[] indexes =
IntStream.rangeClosed(-1, sz)
.filter(i -> i == -1 || i == sz || input.get(i) == null)
.toArray();
return IntStream.range(0, indexes.length-1)
.mapToObj(i -> input.subList(indexes[i]+1, indexes[i+1]))
.collect(toList());
}
UPDATE 2016-11-23
I co-presented a talk with Brian Goetz at Devoxx Antwerp 2016, "Thinking In Parallel" (video) that featured this problem and my solutions. The problem presented there is a slight variation that splits on "#" instead of null, but it's otherwise the same. In the talk, I mentioned that I had a bunch of unit tests for this problem. I've appended them below, as a standalone program, along with my loop and streams implementations. An interesting exercise for readers is to run solutions proposed in other answers against the test cases I've provided here, and to see which ones fail and why. (The other solutions will have to be adapted to split based on a predicate instead of splitting on null.)
import java.util.*;
import java.util.function.*;
import java.util.stream.*;
import static java.util.Arrays.asList;
public class ListSplitting {
static final Map<List<String>, List<List<String>>> TESTCASES = new LinkedHashMap<>();
static {
TESTCASES.put(asList(),
asList(asList()));
TESTCASES.put(asList("a", "b", "c"),
asList(asList("a", "b", "c")));
TESTCASES.put(asList("a", "b", "#", "c", "#", "d", "e"),
asList(asList("a", "b"), asList("c"), asList("d", "e")));
TESTCASES.put(asList("#"),
asList(asList(), asList()));
TESTCASES.put(asList("#", "a", "b"),
asList(asList(), asList("a", "b")));
TESTCASES.put(asList("a", "b", "#"),
asList(asList("a", "b"), asList()));
TESTCASES.put(asList("#"),
asList(asList(), asList()));
TESTCASES.put(asList("a", "#", "b"),
asList(asList("a"), asList("b")));
TESTCASES.put(asList("a", "#", "#", "b"),
asList(asList("a"), asList(), asList("b")));
TESTCASES.put(asList("a", "#", "#", "#", "b"),
asList(asList("a"), asList(), asList(), asList("b")));
}
static final Predicate<String> TESTPRED = "#"::equals;
static void testAll(BiFunction<List<String>, Predicate<String>, List<List<String>>> f) {
TESTCASES.forEach((input, expected) -> {
List<List<String>> actual = f.apply(input, TESTPRED);
System.out.println(input + " => " + expected);
if (!expected.equals(actual)) {
System.out.println(" ERROR: actual was " + actual);
}
});
}
static <T> List<List<T>> splitStream(List<T> input, Predicate<? super T> pred) {
int[] edges = IntStream.range(-1, input.size()+1)
.filter(i -> i == -1 || i == input.size() ||
pred.test(input.get(i)))
.toArray();
return IntStream.range(0, edges.length-1)
.mapToObj(k -> input.subList(edges[k]+1, edges[k+1]))
.collect(Collectors.toList());
}
static <T> List<List<T>> splitLoop(List<T> input, Predicate<? super T> pred) {
List<List<T>> result = new ArrayList<>();
int start = 0;
for (int cur = 0; cur < input.size(); cur++) {
if (pred.test(input.get(cur))) {
result.add(input.subList(start, cur));
start = cur + 1;
}
}
result.add(input.subList(start, input.size()));
return result;
}
public static void main(String[] args) {
System.out.println("===== Loop =====");
testAll(ListSplitting::splitLoop);
System.out.println("===== Stream =====");
testAll(ListSplitting::splitStream);
}
}
[list(v) for k, v in groupby(lst, key=lambda x: x is not None) if k]. There isCollectors.groupingBy, but to be honest I don't understand how it works... – CowardlyCollectors.groupingBymaps the list by a property: for example grouping["a", "b", "aa", "aaa"]byString::lengthwould produce{1:["a", "b"], 2:["aa"], 3:["aaa"]}... I don't know if it could be used in my case – Electronegativestream().forEachinstead of Java 7forEach. – FrolickList<List<String>>and populate it in alist.stream().forEach()but it suppose that you get the elements in a sequence and it cannot be called in parallel. In brief, you lose every pros ofStreamswithout having the clarity of Java 7. – FrolickCollectors.groupingByworks quite differently than Python'sitertools.groupbyand is more likeCollectors.partitioningBy, just with more than two groups, i.e. it would put all the non-null strings in one bucket. – Cowardly