I don't want to step on the excellent answers provided above, but no one really talks about why "r" has the value it has. The low-level answer provided by the Colin Percival's Scrypt paper is that it relates to the "memory latency-bandwidth product". But what does that actually mean?
If you're doing Scrypt right, you should have a large memory block which is mostly sitting in main memory. Main memory takes time to pull from. When an iteration of the block-jumping loop first selects an element from the large block to mix into the working buffer, it has to wait on the order of 100 ns for the first chunk of data to arrive. Then it has to request another, and wait for it to arrive.
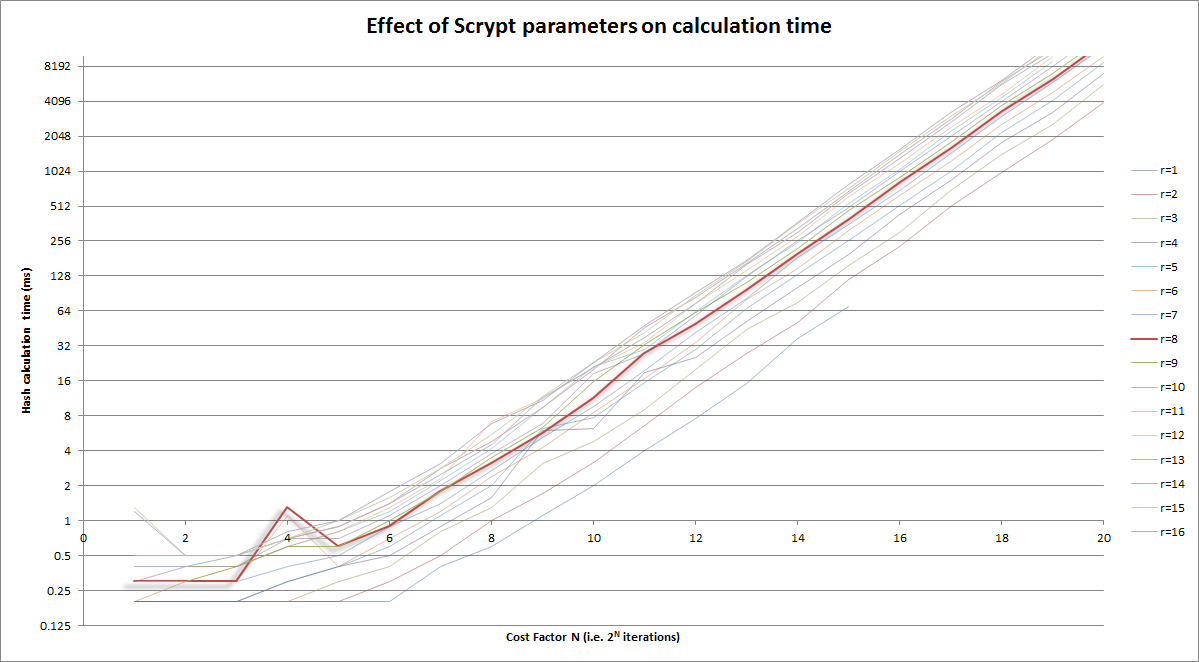
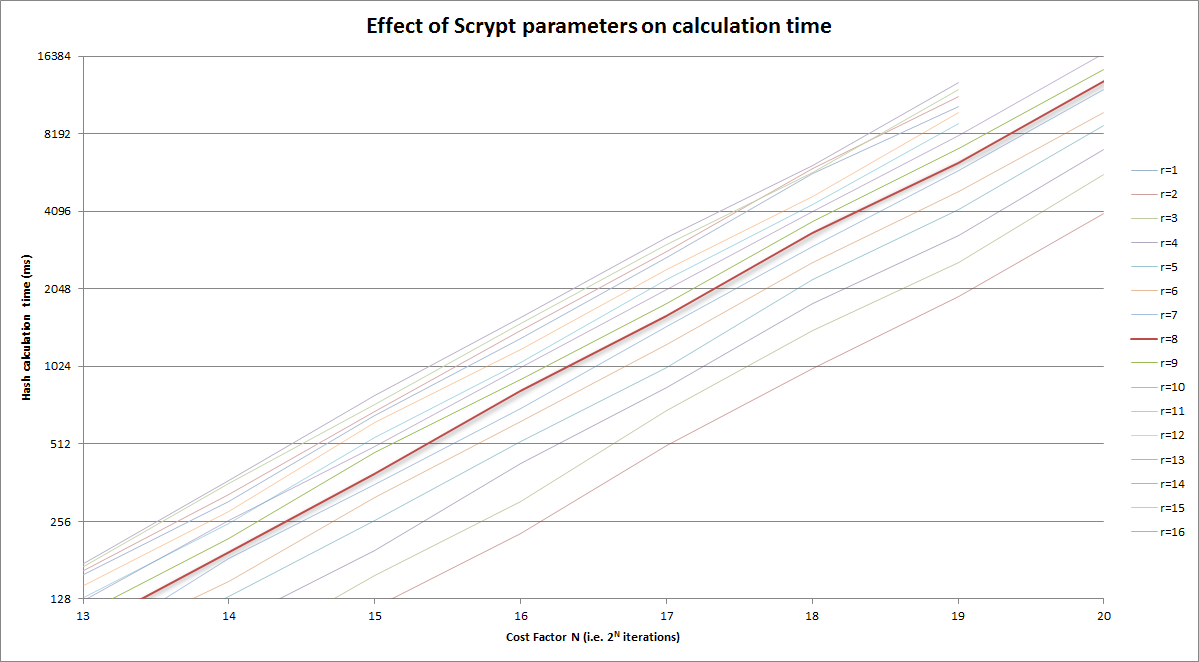
For r = 1, you'd be doing 4nr Salsa20/8 iterations and 2n latency-imbued reads from main memory.
This isn't good, because it means that an attacker could get an advantage over you by building a system with reduced latency to main memory.
But if you increase r and proportionally decrease N, you are able to achieve the same memory requirements and do the same number of computations as before--except that you've traded some random accesses for sequential accesses. Extending sequential access allows either the CPU or the library to prefetch the next required blocks of data efficiently. While the initial latency is still there, the reduced or eliminated latency for the later blocks averages the initial latency out to a minimal level. Thus, an attacker would gain little from improving their memory technology over yours.
However, there is a point of diminishing returns with increasing r, and that is related to the "memory latency-bandwidth product" referred to before. What this product indicates is how many bytes of data can be in transit from main memory to the processor at any given time. It's the same idea as a highway--if it takes 10 minutes to travel from point A to point B (latency), and the road delivers 10 cars/minute to point B from point A (bandwidth), the roadway between points A and B contains 100 cars. So, the optimal r relates to how many 64-byte chunks of data you can request at once, in order to cover up the latency of that initial request.
This improves the speed of the algorithm, allowing you to either increase N for more memory and computations or to increase p for more computations, as desired.
There are some other issues with increasing "r" too much, which I haven't seen discussed much:
- Increasing r while decreasing N reduces the number of pseudorandom jumps around memory. Sequential accesses are easier to optimize, and could give an attacker a window. As Colin Percival noted to me on Twitter, larger r could allow an attacker to use a lower cost, slower storage technology, reducing their costs considerably (https://twitter.com/cperciva/status/661373931870228480).
- The size of the working buffer is 1024r bits, so the number of possible end products, which will eventually be fed into PBKDF2 to produce the Scrypt output key, is 2^1024r. The number of permutations (possible sequences) of jumps around the large memory block is 2^NlogN. Which means that there are 2^NlogN possible products of the memory-jumping loop. If 1024r > NlogN, that would seem to indicate that the working buffer is being under-mixed. While I don't know this for sure, and would love to see a proof or disproof, it may be possible for correlations to be found between the working buffer's result and the sequence of jumps, which could allow an attacker an opportunity to reduce their memory requirements without as-greatly increased computational cost. Again, this is an observation based on the numbers--it may be that everything is so well-mixed in every round that this isn't a problem. r = 8 is well below this potential threshold for the standard N = 2^14 -- for N = 2^14, this threshold would be r = 224.
To sum up all the recommendations:
- Choose r to be just large enough to average out the effects of
memory latency on your device and no more. Keep in mind that the
value Colin Percival recommended, r = 8, appears to remain fairly
optimal broadly for memory technology, and this apparently hasn't
changed much in 8 years; 16 may be ever so slightly better.
- Decide on how big a chunk of memory you want to use per thread,
keeping in mind this affects computation time as well, and set N
accordingly.
- Increase p arbitrarily high to what your usage can tolerate (note:
on my system and using my own implementation, p = 250 (4
threads) with N = 16384 and r = 8 takes ~5 seconds), and enable
threading if you can deal with the added memory cost.
- When tuning, prefer large N and memory block size to increased p and
computation time. Scrypt's primary benefit comes from its large
memory block size.
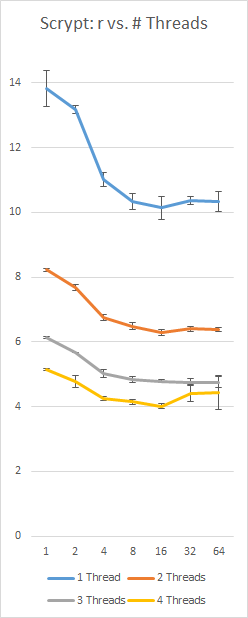
A benchmark of my own implementation of Scrypt on a Surface Pro 3 with an i5-4300 (2 cores, 4 threads), using a constant 128Nr = 16 MB and p = 230; left-axis is seconds, bottom axis is r value, error bars are +/- 1 standard deviation:
![Scrypt r values vs. p with constant large block size]()