I have been trying to find how to get the dependency tree with spaCy but I can't find anything on how to get the tree, only on how to navigate the tree.
How to get the dependency tree with spaCy?
check this: spacy.io/universe/project/self-attentive-parser –
Featherstitch
It turns out, the tree is available through the tokens in a document.
Would you want to find the root of the tree, you can just go though the document:
def find_root(docu):
for token in docu:
if token.head is token:
return token
To then navigate the tree, the tokens have API to get through the children
A document will have 1 root per sentence –
Amphioxus
There's no need to iterate over the tokens to find the root; you can just access the
.root property of a sentence. I'll post my own answer showing this. –
Birchard In case someone wants to easily view the dependency tree produced by spacy, one solution would be to convert it to an nltk.tree.Tree and use the nltk.tree.Tree.pretty_print method. Here is an example:
import spacy
from nltk import Tree
en_nlp = spacy.load('en')
doc = en_nlp("The quick brown fox jumps over the lazy dog.")
def to_nltk_tree(node):
if node.n_lefts + node.n_rights > 0:
return Tree(node.orth_, [to_nltk_tree(child) for child in node.children])
else:
return node.orth_
[to_nltk_tree(sent.root).pretty_print() for sent in doc.sents]
Output:
jumps
________________|____________
| | | | | over
| | | | | |
| | | | | dog
| | | | | ___|____
The quick brown fox . the lazy
Edit: For changing the token representation you can do this:
def tok_format(tok):
return "_".join([tok.orth_, tok.tag_])
def to_nltk_tree(node):
if node.n_lefts + node.n_rights > 0:
return Tree(tok_format(node), [to_nltk_tree(child) for child in node.children])
else:
return tok_format(node)
Which results in:
jumps_VBZ
__________________________|___________________
| | | | | over_IN
| | | | | |
| | | | | dog_NN
| | | | | _______|_______
The_DT quick_JJ brown_JJ fox_NN ._. the_DT lazy_JJ
But in my opinion it is important to have/keep the dependencies as well as postags from Spacy. –
Archer
Nice job! Is there an easy way to add the dependency tag between two nodes? –
Argyrol
@DavidBatista see my edit. If you want to add some other stuff to the tree edit
tok_format(tok). Also you should read the docs. Spacy uses 2 different POS representations tok.pos_ and tok.tag_. spacy.io/docs/#token-postags –
Meander The
tok.dep_ attribute can also be used along with tok.tag_ to state the syntactic dependency relation. –
Heck The tree isn't an object in itself; you just navigate it via the relationships between tokens. That's why the docs talk about navigating the tree, but not 'getting' it.
First, let's parse some text to get a Doc object:
>>> import spacy
>>> nlp = spacy.load('en_core_web_sm')
>>> doc = nlp('First, I wrote some sentences. Then spaCy parsed them. Hooray!')
doc is a Sequence of Token objects:
>>> doc[0]
First
>>> doc[1]
,
>>> doc[2]
I
>>> doc[3]
wrote
But it doesn't have a single root token. We parsed a text made up of three sentences, so there are three distinct trees, each with their own root. If we want to start our parsing from the root of each sentence, it will help to get the sentences as distinct objects, first. Fortunately, doc exposes these to us via the .sents property:
>>> sentences = list(doc.sents)
>>> for sentence in sentences:
... print(sentence)
...
First, I wrote some sentences.
Then spaCy parsed them.
Hooray!
Each of these sentences is a Span with a .root property pointing to its root token. Usually, the root token will be the main verb of the sentence (although this may not be true for unusual sentence structures, such as sentences without a verb):
>>> for sentence in sentences:
... print(sentence.root)
...
wrote
parsed
Hooray
With the root token found, we can navigate down the tree via the .children property of each token. For instance, let's find the subject and object of the verb in the first sentence. The .dep_ property of each child token describes its relationship with its parent; for instance a dep_ of 'nsubj' means that a token is the nominal subject of its parent.
>>> root_token = sentences[0].root
>>> for child in root_token.children:
... if child.dep_ == 'nsubj':
... subj = child
... if child.dep_ == 'dobj':
... obj = child
...
>>> subj
I
>>> obj
sentences
We can likewise keep going down the tree by viewing one of these token's children:
>>> list(obj.children)
[some]
Thus with the properties above, you can navigate the entire tree. If you want to visualise some dependency trees for example sentences to help you understand the structure, I recommend playing with displaCy.
You can use the library below to view your dependency tree, found it extremely helpful!
import spacy
from spacy import displacy
nlp = spacy.load('en')
doc = nlp(u'This is a sentence.')
displacy.serve(doc, style='dep')
You can open it with your browser, and it looks like:
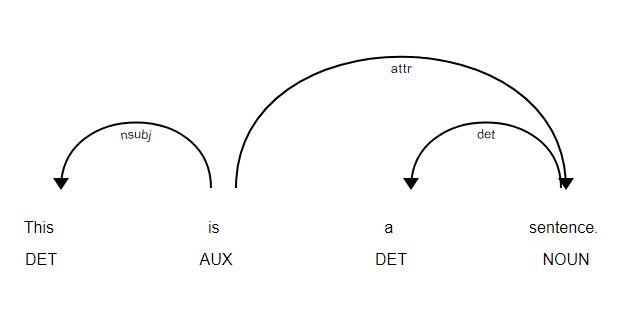
To generate a SVG file:
from pathlib import Path
output_path = Path("yourpath/.svg")
svg = displacy.render(doc, style='dep')
with output_path.open("w", encoding="utf-8") as fh:
fh.write(svg)
JFI.. the serve option also opens the tree as a weblink. For static image (the render option is available
displacy.render(doc, style='dep') –
Agonizing To add to @prashanth's comment, you can also print to an image (that you can open/view, e.g., in Firefox; note that you need to specify the full path (
/home/victoria/..., not ~/...). Code: from pathlib import Path; output_path = Path("/home/victoria/dependency_plot.svg"); svg = displacy.render(doc, style='dep', jupyter=False); output_path.open("w", encoding="utf-8").write(svg) –
Heteroousian Strangely, when I render as svg, the dependency tags are missing, when I render with
serve, they get printed. –
Outflank I don't know if this is a new API call or what, but there's a .print_tree() method on the Document class that makes quick work of this.
https://spacy.io/api/doc#print_tree
It dumps the dependency tree to JSON. It deals with multiple sentence roots and all that :
import spacy
nlp = spacy.load('en')
doc1 = nlp(u'This is the way the world ends. So you say.')
print(doc1.print_tree(light=True))
The name print_tree is a bit of a misnomer, the method itself doesn't print anything, rather it returns a list of dicts, one for each sentence.
Doc.print_tree method is deprecated in v2.1 in favour of Doc.to_json. –
Loess
It turns out, the tree is available through the tokens in a document.
Would you want to find the root of the tree, you can just go though the document:
def find_root(docu):
for token in docu:
if token.head is token:
return token
To then navigate the tree, the tokens have API to get through the children
A document will have 1 root per sentence –
Amphioxus
There's no need to iterate over the tokens to find the root; you can just access the
.root property of a sentence. I'll post my own answer showing this. –
Birchard I also needed to do it so below full code:
import sys
def showTree(sent):
def __showTree(token):
sys.stdout.write("{")
[__showTree(t) for t in token.lefts]
sys.stdout.write("%s->%s(%s)" % (token,token.dep_,token.tag_))
[__showTree(t) for t in token.rights]
sys.stdout.write("}")
return __showTree(sent.root)
And if you want spacing for the terminal:
def showTree(sent):
def __showTree(token, level):
tab = "\t" * level
sys.stdout.write("\n%s{" % (tab))
[__showTree(t, level+1) for t in token.lefts]
sys.stdout.write("\n%s\t%s [%s] (%s)" % (tab,token,token.dep_,token.tag_))
[__showTree(t, level+1) for t in token.rights]
sys.stdout.write("\n%s}" % (tab))
return __showTree(sent.root, 1)
I just added module for printing as well as matching tree(or finding nodes) on regex like pattern. If you are interested here is the link: github.com/krzysiekfonal/grammaregex It's not installable ready yet but this week should be fulfilled and available via pip. –
Archer
While the spaCy library has probably changed a bit over the past 5 years, @Mark Amery's approach works very well. It's what I've been doing to break down sentences within pages and pages of copy in order to get the nominally described features, and the NP or VP's that are associated with them. Another approach we've taken (which may have come to SpaCy in the past 5 years since)... if you look at the root VB in the phrase against your future, and, noting the type of dep, this root's ancestors and the children of the ancestor, you'll basically find the heads that point to the subject, object and root. You can break them into clauses that are modifiers based on appositional or conjuncts etc which will tell you if these clauses are supplemental or core to the descriptions of the feature. With that you can rewrite the sentences, which I mainly do to strip out superfluous stuff and create fragments that consist of the hard details. Dunno if helpful to others, but this is the tact I follow after weeks of diagramming nsubj, dobj, conjuncts, and pobjs on paper compared to SpaCy's tensor based modeling. IMO, it's worth noting that the tagging done by SpaCy always appears to be 100% correct - every time, even when the fragments are 20 words apart in horribly written run-ons that are horribly written. I've never have to second guess it's output - which is obviously invaluable.
This code can be used to read a spacy dependency parse tree;
import numpy as np
import spacy
rootNodeName = "ROOT"
class ParseNode:
def __init__(self, token, w):
self.word = token.text
self.w = w #or token.i
self.governor = None
self.dependentList = []
self.parseLabel = None
def generateSentenceParseNodeList(tokenizedSentence):
sentenceParseNodeList = []
for w, token in enumerate(tokenizedSentence):
print("add parseNode: w = ", w, ": text = ", token.text)
parseNode = ParseNode(token, w)
sentenceParseNodeList.append(parseNode)
return sentenceParseNodeList
def generateDependencyParseTree(tokenizedSentence, sentenceParseNodeList):
parseTreeHeadNode = None
for w, tokenDependent in enumerate(tokenizedSentence):
parseNodeDependent = sentenceParseNodeList[tokenDependent.i]
print("add dependency relation: tokenDependent w = ", w, ": text = ", tokenDependent.text, ", i = ", tokenDependent.i, ", tag_ = ", tokenDependent.tag_, ", head.text = ", tokenDependent.head.text, ", dep_ = ", tokenDependent.dep_)
if(tokenDependent.dep_ == rootNodeName):
parseTreeHeadNode = parseNodeDependent
else:
tokenGovernor = tokenDependent.head
parseNodeGovernor = sentenceParseNodeList[tokenGovernor.i]
parseNodeDependent.governor = parseNodeGovernor
parseNodeGovernor.dependentList.append(parseNodeDependent)
parseNodeDependent.parseLabel = tokenDependent.dep_
return parseTreeHeadNode
nlp = spacy.load('en_core_web_md')
text = "This is an example sentence."
tokenizedSentence = nlp(text)
sentenceParseNodeList = generateSentenceParseNodeList(tokenizedSentence)
parseTreeHeadNode = generateDependencyParseTree(tokenizedSentence, sentenceParseNodeList)
I do not have enough knowledge about the parsing yet. However, outcome of my literature study has resulted in knowing that spaCy has a shift-reduce dependency parsing algorithm. This parses the question/sentence, resulting in a parsing tree. To visualize this, you can use the DisplaCy, combination of CSS and Javascript, works with Python and Cython. Furthermore, you can parse using the SpaCy library, and import the Natural Language Toolkit (NLTK). Hope this helps
© 2022 - 2024 — McMap. All rights reserved.