In layman's terms, what's a RDF triple?
What's a RDF triple?
Asked Answered
I had the same question the other day, so I created a Wikipedia article collecting info from several other articles where they were briefly described: en.wikipedia.org/wiki/Semantic_triple (beware: I'm a layman in this area myself) –
Encincture
See also: did you arrive at this post after searching for why someone would want to use RDF? For good or ill, that is outside the scope of StackOverflow. Content on this post that touches on that aspect have been down-voted or even deleted. Here is an article that may be more of what you were looking for What happened to the Semantic Web –
Artema
I think the question needs to be split into two parts - what is a triple and what makes an "RDF triple" so special?
Firstly, a triple is, as most of the other commenters here have already pointed out, a statement in "subject/predicate/object" form - i.e. a statement linking one object (subject) to another object(object) or a literal, via a predicate. We are all familiar with triples: a triple is the smallest irreducible representation for binary relationship. In plain English: a spreadsheet is a collection of triples, for example, if a column in your spreadsheet has the heading "Paul" and a row has the heading "has Sister" and the value in the cell is "Lisa". Here you have a triple: Paul (subject) has Sister(predicate) Lisa (literal/object).
What makes RDF triples special is that EVERY PART of the triple has a URI associated with it, so the everyday statement "Mike Smith knows John Doe" might be represented in RDF as:
uri://people#MikeSmith12 http://xmlns.com/foaf/0.1/knows uri://people#JohnDoe45
The analogy to the spreadsheet is that by giving every part of the URI a unique address, you give the cell in the spreadsheet its whole address space....so you could in principle stick every cell (if expressed in RDF triples) of the spreadsheet into a different document on a different server and reconstitute the spreadsheet through a single query.
Edit: This section of the official documentation addresses the original question.
@Nico Adams Is N-Triple is an RDF triple? If yes, I saw some n-triples in which object is a string literal. In some cases it is a URI. Ex: <dbpedia.org/resource/Otto_Rank> <dbpedia.org/property/birthPlace> "Vienna, Austria"@en . –
Muskrat
An RDF Triple is a statement which relates one object to another. For Example:
"gcc" "Compiles" "c" .
"gcc" "compiles" "Java" .
"gcc" "compiles" "fortran" .
"gcc" "has a website at" <http://gcc.gnu.org/> .
"gcc" "has a mailing list at" <mailto:[email protected]> .
"c" "is a" "programming language" .
"c" "is documented in" <http://www.amazon.com/Programming-Language-Prentice-Hall-Software/dp/0131103628/ref=pd_bbs_sr_1?ie=UTF8&s=books&qid=1226085111&sr=8-1> .
Sadly, no, not fixed. I encourage you to re-read the RDF Primer. Literals are only allowed in the Object position -- neither Subject nor Predicate may be a literal. Subjects and Predicates MUST, and Objects MAY, be IRIs. –
Teflon
An RDF file should parse down to a list of triples.
A triple consists of a subject, a predicate, and an object. But what do these actually mean?
The subject is, well, the subject. It identifies what object the triple is describing.
The predicate defines the piece of data in the object we are giving a value to.
The object is the actual value.
From: http://www.robertprice.co.uk/robblog/archive/2004/10/What_Is_An_RDF_Triple_.shtml
Regarding the answer by Adam N. I believe the O.P. asked a previous question regarding data for a social network, so although the answer is excellent, I will just clarify in relation to the "original original" question. (As I feel responsible).
John | Is a Friend of | James
James | Is a friend of | Jill
Jill | Likes | Snowboarding
Snowboarding | Is a | Sport
Using triples like this you can have a really flexible data structure.
Look at the Friend of a friend (FOAF) perhaps for a better example.
RDF is a Language, i.e., a system of signs, syntax, and semantics for encoding and decoding information (data in some context).
In RDF, a unit of observation (Data) is represented by a sentence that consists of three parts: subject, predicate, object. Basically, this is the fundamental structure of natural language speech.
The sign used to denote entities (things) participating in entity relationships represented by RDF is an IRI (which includes HTTP URIs). Each subject and predicate (and optionally, object) component of an RDF sentence is denoted by an IRI.
The syntax (grammar) is abstract (meaning it can be represented using a variety of notations) in the form of subject, predicate, and object arrangement order.
The semantics (the part overlooked most often) is all about the meaning of the subject, predicate, and object roles in an RDF statement.
When you use HTTP URIs to denote RDF statement subject, predicates, and (optionally) objects, you end up with structured data (collections of entity relationship types) that form a web -- just as you have today on the World Wide Web.
When the semantics of a predicate (in particular) in an RDF statement are both machine and human comprehensible you have a web of entity relationship types that provide powerful encoding of information that is a foundation for knowledge (inference and reasoning).
Here are examples of simple RDF statements:
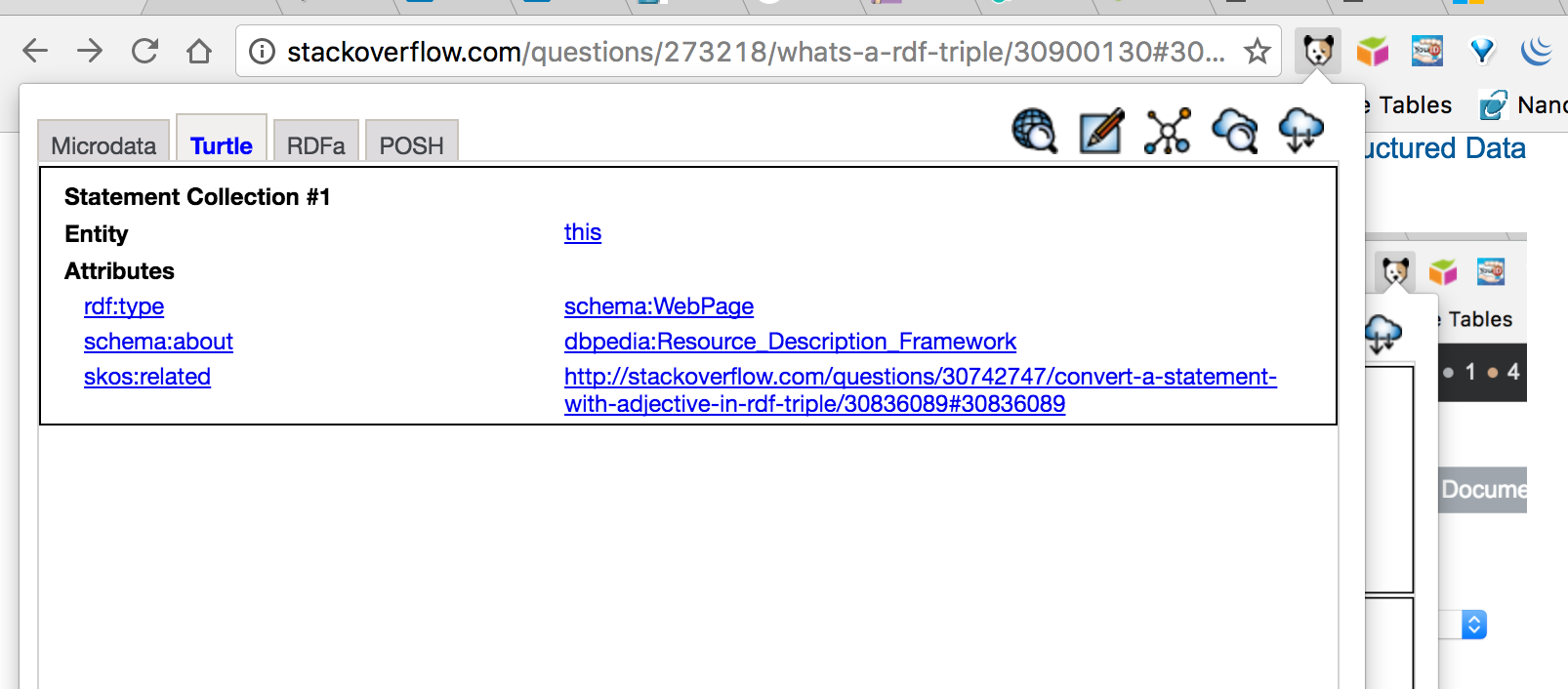
{
<#this> a schema:WebPage .
<#this> schema:about dbpedia:Resource_Description_Framework .
<#this> skos:related <https://mcmap.net/q/275562/-convert-a-statement-with-adjective-in-rdf-triple/30836089#30836089> .
}
I've used braces to enclose the examples so that this post turns into a live RDF-based Linked Data demonstration, courtesy of relative HTTP URIs and the # based fragment identifier (indexical).
Results of the RDF statements embedded in this post, courtesy of nanotation (embedding RDF statements wherever text is accepted):
- Basic Entity Description Page -- Each Statement is identified by a hyperlink that resolves to its description (subject, predicate, object parts)
- Deeper Faceted Browsing Page -- Alternative view that lends itself to deeper exploration and discovery by following-your-nose through the hyperlinks that constitute the data web or web of linked data.
- Description of an embedded statement -- About a specific RDF statement.
Here's the visualization generated from the triples embedded in this post (using our Structured Data Sniffer Browser Extension, using RDF-Turtle Notation:
How exactly did you generate RDF for this post? The link1 you mentioned. Please can you let me know. I am not able to generate such output for arbitrary wikipedia page .e.g en.wikipedia.org/wiki/Giraffe –
Bathurst
I use a concept called nanotation to embed RDF-triples wherever text is accepted. [1] kidehen.blogspot.com/2014/07/nanotation.html -- About Nanotation. –
Leprous
Note, that it can get a bit more complicated. RDF triples can also be considered Subjects or Objects, so you can have something like: Bart -> said -> ( triples -> can be -> objects)
This is not strictly correct. RDF provides a vocabulary to express reification to talk about RDF triples (w3.org/TR/2004/REC-rdf-primer-20040210/#reification). However, there is an interesting extension to RDF that was presented earlier this year called RDF*, along with a query language (SPARQL*), that allowed exactly this. Here's a reference to the paper for anyone who's interested: olafhartig.de/files/Hartig_AMW2017_RDFStar.pdf –
Brainsick
I'm going to have to agree with A Pa in part, even though he was down-voted.
Background: I'm a linguist, with a PhD in that subject, and I work in computational linguistics.
The statement that "...a sentence that consists of three parts: subject, predicate, object. Basically, this is the fundamental structure of natural language speech" (which A Pa quotes from Kingsley Uyi Idehen's answer) is simply wrong. And it's not just that Kingsley says this, I've heard it from many advocates of RDF triples.
It's wrong for many reasons, for example: Predicates (in English, arguably, and in many other natural languages) consist of a verb (or a verb-like thing) + the object (and perhaps other complements). It is definitely NOT the case that the syntactic structure of English is Subj-Pred-Obj.
Furthermore, not all natural language sentences in English have an object; intransitive verbs, in particular, by definition do not take objects. And weather verbs (among other things) don't even take a "real" subject (the "it" of "it rains" has no reference). And on the other hand, ditransitive verbs like "give" take both a direct and an indirect object. Then there are verbs like "put" that take a locative in addition to the direct object, or "tell" that take an object and a clause. Not to mention adjuncts, like time and manner adverbials.
Yes, of course you can represent embedded clauses as embedded triples (to the extent that you can represent any statement as triples, which as I hope you've made clear, you can't), but what I don't think you can do in RDF (at least I've never seen it done, and it seems like it would take a quadruple) is to have both an object and an embedded clause. Likewise both a direct and an indirect object, or adjuncts.
So whatever the motivation for RDF triples, I wish the advocates would stop pretending that there's a linguistic motivation, or that the triples in any way resemble natural language syntax. Because they don't.
I'm just getting started on this and have done some Google searches on this. Most writeups focus on thw syntax of the query language and/or triples in general. What I never see is an automated way to parse text into these triples –
Debutant
It has been awhile since I worked with RDF, but here it goes :D
A triple is a subject, predicate and object.
The subject is a URI which uniquely identifies something. For example, your openid uniquely identifies you.
The object defines how the subject and object are related.
The predicate is some attribute of the subject. For example a name.
Given that, the triples form a graph S->P. Given more triplets, the graph grows. For example, you can have the same person identified as the subject of a bunch of triples, you can then connect all of the predicates through that unique subject.
RDF Triple is an actual expression that defines a way in which you can represent a relationship between objects. There are three parts to a triple: Subject, Predicate and Object (typically written in the same order). A predicate relates subject to object.
Subject ----Predicate---> Object
More useful information can be found at:
A simple answer can be that an RDF triple is a representation of some knowledge using RDF data model. This model is based upon the idea of making statements about resources (in particular web resources URIs) in the form of subject–predicate–object expressions. RDF is also a standard model for data interchange on the Web. RDF has features that facilitate data merging even if the underlying schemas differ, and it specifically supports the evolution of schemas over time without requiring all the data consumers to be changed. I recommend this article to know how: https://www.w3.org/DesignIssues/RDF-XML.html
One can think of a triple as a type of sentence that states a single "fact" about a resource. First of all to understand RDF Triple you should know that each and every thing in RDF is defined in terms of URI http://www.w3.org/TR/2004/REC-rdf-concepts-20040210/#dfn-URI-referenceor blank node http://www.w3.org/TR/2004/REC-rdf-concepts-20040210/#dfn-blank-node.
An RDF Triple consists of three components :- 1) Subject 2) Predicate 3) Object For ex :- Pranay hasCar Ferrari Here Subject is Pranay, hasCar is a predicate and Ferrari is a object. This are each defined with RDF-URI. For more information you can visit :- http://www.w3.org/TR/owl-ref/
Triple explained by example
Be there a table that relates users and questions.
TABLE dc:creator ------------------------- | Question | User | ------------------------- | 45 | 485527 | | 44 | 485527 | | 40 | 485528 |
This could conceptually be expressed in three RDF triples like...
<question:45> <dc:creator> <user:485527>
<question:44> <dc:creator> <user:485527>
<question:40> <dc:creator> <user:485528>
...so that each row is converted to one triple that relates a user to a question. The general form of each triple can be described as:
<Subject> <Predicate> <Object>
One specialty about RDF is, that you can (or must) use URIs/IRIs to identify entities as well as relations. Find more here. This makes it possible for everyone to reuse already existing relations (predicates) and to publish statements about arbitrary entities in the www.
Example relating a SO answer to its creator:
<https://mcmap.net/q/272393/-what-39-s-a-rdf-triple>
<http://purl.org/dc/terms/creator>
<https://stackoverflow.com/users/1485527>
As a developer, I have struggled for a while until I finally understood what RDF and its tripes was about, mostly because I have always seen the world through code and not through data.
Given this is posted on StackOverflow, here is the Java analogy that finally made it click for me: a RDF triple is to data what a class' method/parameter is to code.
So:
- A class with its package name is the Subject
- A method on this class is the Predicate
- Parameter(s) on the method is the Object, which are themselves represented by classes
- Contexts are import statements to avoid writing the full canonical name of classes
The only point where this analogy breaks down a bit is that Predicates also have namespaces, while methods do not. But the overall relationships created between class instances as Subject and Object when a Predicate is used reflects on the idea of calling a method to do something.
Basically, RDF is to data what OO is to code.
See: http://www.w3.org/TR/2004/REC-rdf-concepts-20040210/#dfn-rdf-triple
An RDF triple contains three components:
- the subject, which is an RDF URI reference or a blank node
- the predicate, which is an RDF URI reference
- the object, which is an RDF URI reference, a literal or a blank node
where literals are essentially strings with optional language tags, and blank nodes are also strings. URIs, literals and blank nodes must be from pair-wise disjoint sets.
© 2022 - 2024 — McMap. All rights reserved.