My initial purpose was to verify the HTTP chunked transfer. But accidentally found this inconsistency.
The API is designed to return a file to client. I use HEAD and GET methods against it. Different headers are returned.
For GET, I get these headers: (This is what I expected.)
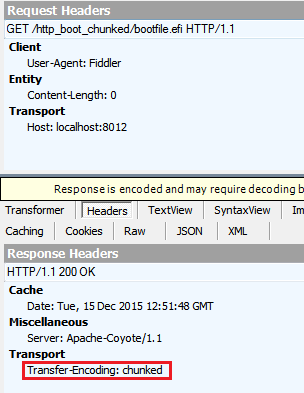
For HEAD, I get these headers:
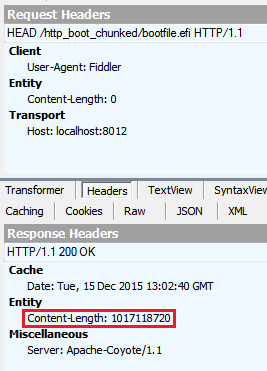
According to this thread, HEAD and GET SHOULD return identical headers but not necessarily.
My question is:
If Transfer-Encoding: chunked is used because the file is dynamically fed to the client and Tomcat server cannot know its size beforehand, how could Tomcat know the Content-Length when HEAD method is used? Does Tomcat just dry-run the handler and count all the file bytes? Why doesn't it simply return the same Transfer-Encoding: chunked header?
Below is my RESTful API implemented with Spring Web MVC:
@RestController
public class ChunkedTransferAPI {
@Autowired
ServletContext servletContext;
@RequestMapping(value = "bootfile.efi", method = { RequestMethod.GET, RequestMethod.HEAD })
public void doHttpBoot(HttpServletResponse response) {
String filename = "/bootfile.efi";
try {
ServletOutputStream output = response.getOutputStream();
InputStream input = servletContext.getResourceAsStream(filename);
BufferedInputStream bufferedInput = new BufferedInputStream(input);
int datum = bufferedInput.read();
while (datum != -1) {
output.write(datum);
datum = bufferedInput.read();
}
output.flush();
output.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
ADD 1
In my code, I didn't explicitly add any headers, then it must be Tomcat that add the Content-Length and Transfer-Encoding headers as it sees fit.
So, what are the rules for Tomcat to decide which headers to send?
ADD 2
Maybe it's related to how Tomcat works. I hope someone can shed some light here. Otherwise, I will debug into the source of Tomcat 8 and share the result. But that may take a while.
Related: