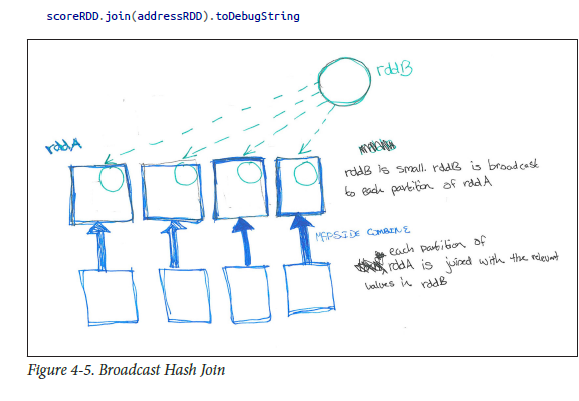
Broadcast Hash Joins (similar to map side join or map-side combine in Mapreduce) :
In SparkSQL you can see the type of join being performed by calling queryExecution.executedPlan. As with core Spark, if one of the tables is much smaller than the other you may want a broadcast hash join. You can hint to Spark SQL that a given DF should be broadcast for join by calling method broadcast on the DataFrame before joining it
Example:
largedataframe.join(broadcast(smalldataframe), "key")
in DWH terms, where largedataframe may be like fact
smalldataframe may be like dimension
As described by my fav book (HPS) pls. see below to have better understanding..
![enter image description here]()
Note : Above broadcast is from import org.apache.spark.sql.functions.broadcast not from SparkContext
Spark also, automatically uses the spark.sql.conf.autoBroadcastJoinThreshold to determine if a table should be broadcast.
Tip : see DataFrame.explain() method
def
explain(): Unit
Prints the physical plan to the console for debugging purposes.
Is there a way to force broadcast ignoring this variable?
sqlContext.sql("SET spark.sql.autoBroadcastJoinThreshold = -1")
NOTE :
Another similar out of box note w.r.t. Hive (not spark) : Similar
thing can be achieved using hive hint MAPJOIN like below...
Select /*+ MAPJOIN(b) */ a.key, a.value from a join b on a.key = b.key
hive> set hive.auto.convert.join=true;
hive> set hive.auto.convert.join.noconditionaltask.size=20971520
hive> set hive.auto.convert.join.noconditionaltask=true;
hive> set hive.auto.convert.join.use.nonstaged=true;
hive> set hive.mapjoin.smalltable.filesize = 30000000; // default 25 mb made it as 30mb
Further Reading : Please refer my article on BHJ, SHJ, SMJ