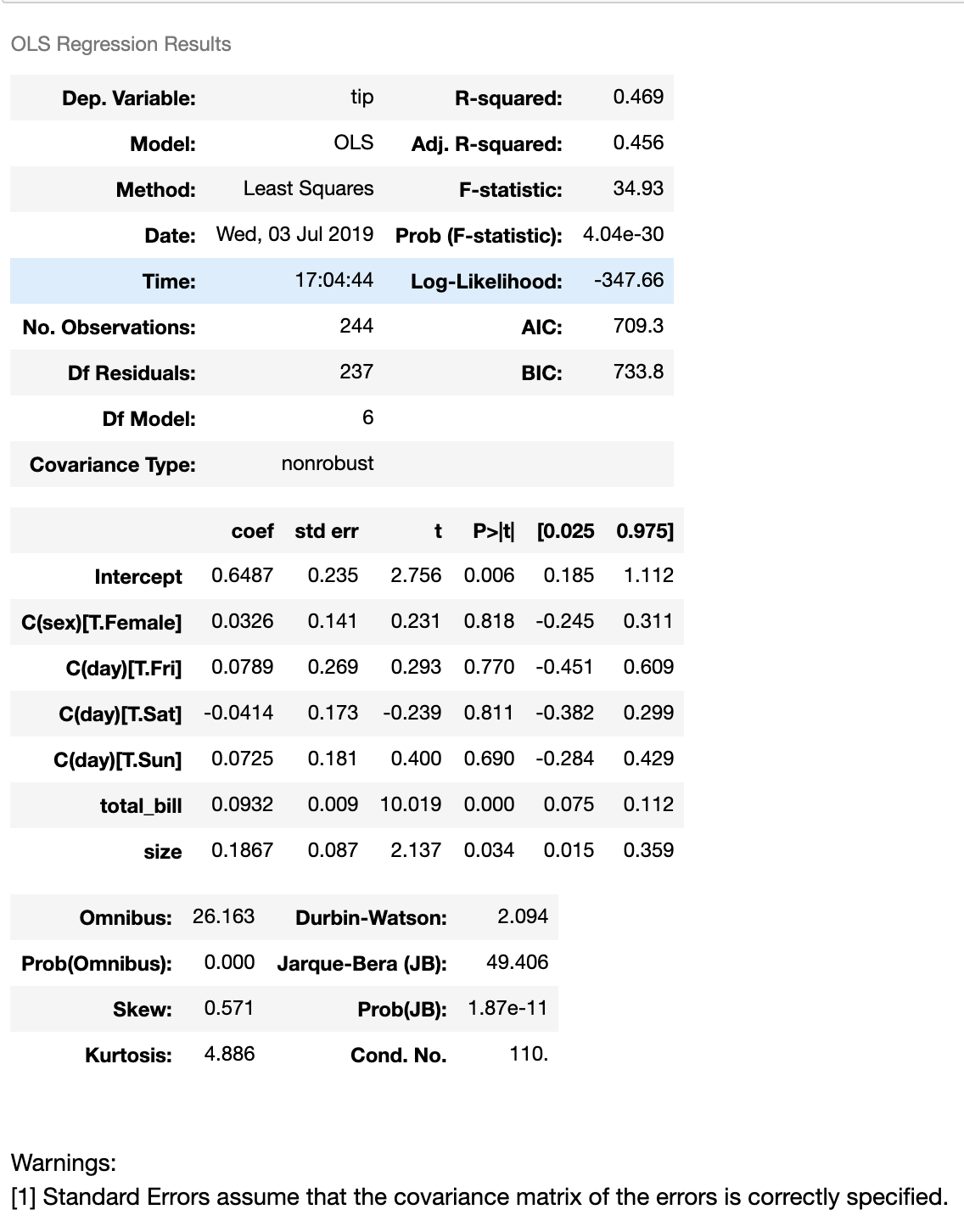
Regression algorithms seem to be working on features represented as numbers. For example:
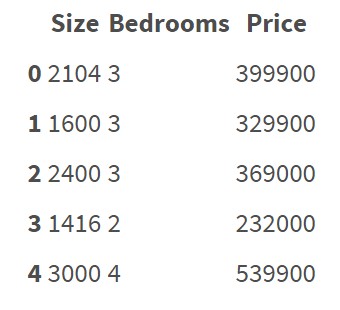
This data set doesn't contain categorical features/variables. It's quite clear how to do regression on this data and predict price.
But now I want to do a regression analysis on data that contain categorical features:
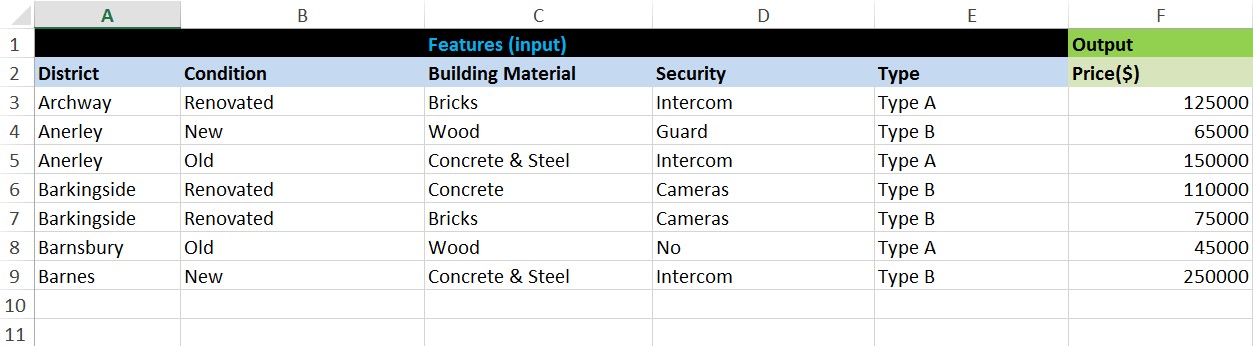
There are 5 features: District, Condition, Material, Security, Type
How can I do a regression on this data? Do I have to transform all the string/categorical data to numbers manually? I mean if I have to create some encoding rules and according to that rules transform all data to numeric values.
Is there any simple way to transform string data to numbers without having to create my own encoding rules manually? Maybe there are some libraries in Python that can be used for that? Are there some risks that the regression model will be somehow incorrect due to "bad encoding"?