Can you explain the concepts of, and relationship between, Covering Indexes and Covered Queries in Microsoft's SQL Server?
What are Covering Indexes and Covered Queries in SQL Server?
Asked Answered
A covering index is one which can satisfy all requested columns in a query without performing a further lookup into the clustered index.
There is no such thing as a covering query.
Have a look at this Simple-Talk article: Using Covering Indexes to Improve Query Performance.
It's worth noting that the article you linked to refers to a Covering Query. They appear to define it as a query that selects columns that were INCLUDEd into a Covering Index - that is, an index which is not the Clustering Index, that has the column values repeated in its leaf node. Also worth noting a Covering Index has an obvious performance penalty for INSERT/UPDATE. –
Lucre
@ChrisMoschini, Then what's a covered query? Same as covering query? –
Surtout
@Surtout Yes, they are the same. –
Lucre
You cannot say that smth is a "covering index" without specifying a query that it covers. Imagine a table of products, with columns:
id, name, shop_id, price. If you index on shop_id, price, then you cover the query that calculates the average price of products of shop X, but you don't cover the query that picks the names of those products, since name is not part of the index. –
Selsyn @nitsas: I'm well aware of what a covering index is. Read the first line of my answer again "A covering index is one which can satisfy all requested columns in a query" - which part of that is unclear? –
Farkas
The part "There is no such thing as a covering query." reads like there's no such thing as a covering/covered query. So I tried to clear it up for other readers. I wasn't talking to you specifically. Let me add a conclusion to my previous comment: "So when we're talking about a covering index, it comes together with a set of queries that it covers. I guess you can call these queries covered queries." –
Selsyn
your comment adds nothing. There are covering indexes and covered queries. There are NO covering queries. –
Farkas
I can see why someone would be confused; @MitchWheat the article in your link repeatedly says "covering query"; but I appreciate that they probably meant "covered query"; sounds like some sites use "covered query" and "covering query" interchangeably for better or worse (probably worse). It's also confusing why we focus on "covering query" because the original question was edited to replace "covering query" with "covered query"!; thanks, –
Hamrick
If all the columns requested in the select list of query, are available in the index, then the query engine doesn't have to lookup the table again which can significantly increase the performance of the query. Since all the requested columns are available with in the index, the index is covering the query. So, the query is called a covering query and the index is a covering index.
A clustered index can always cover a query, if the columns in the select list are from the same table.
The following links can be helpful, if you are new to index concepts:
A Covering Index is a Non-Clustered index. Both Clustered and Non-Clustered indexes use B-Tree data structure to improve the search for data, the difference is that in the leaves of a Clustered Index a whole record (i.e. row) is stored physically right there!, but this is not the case for Non-Clustered indexes. The following examples illustrate it:
Example: I have a table with three columns: ID, Fname and Lname.
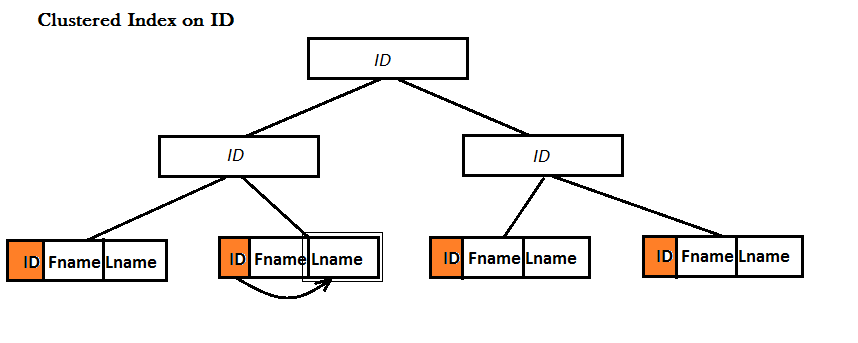
However, for a Non-Clustered index, there are two possibilities: either the table already has a Clustered index or it doesn't:
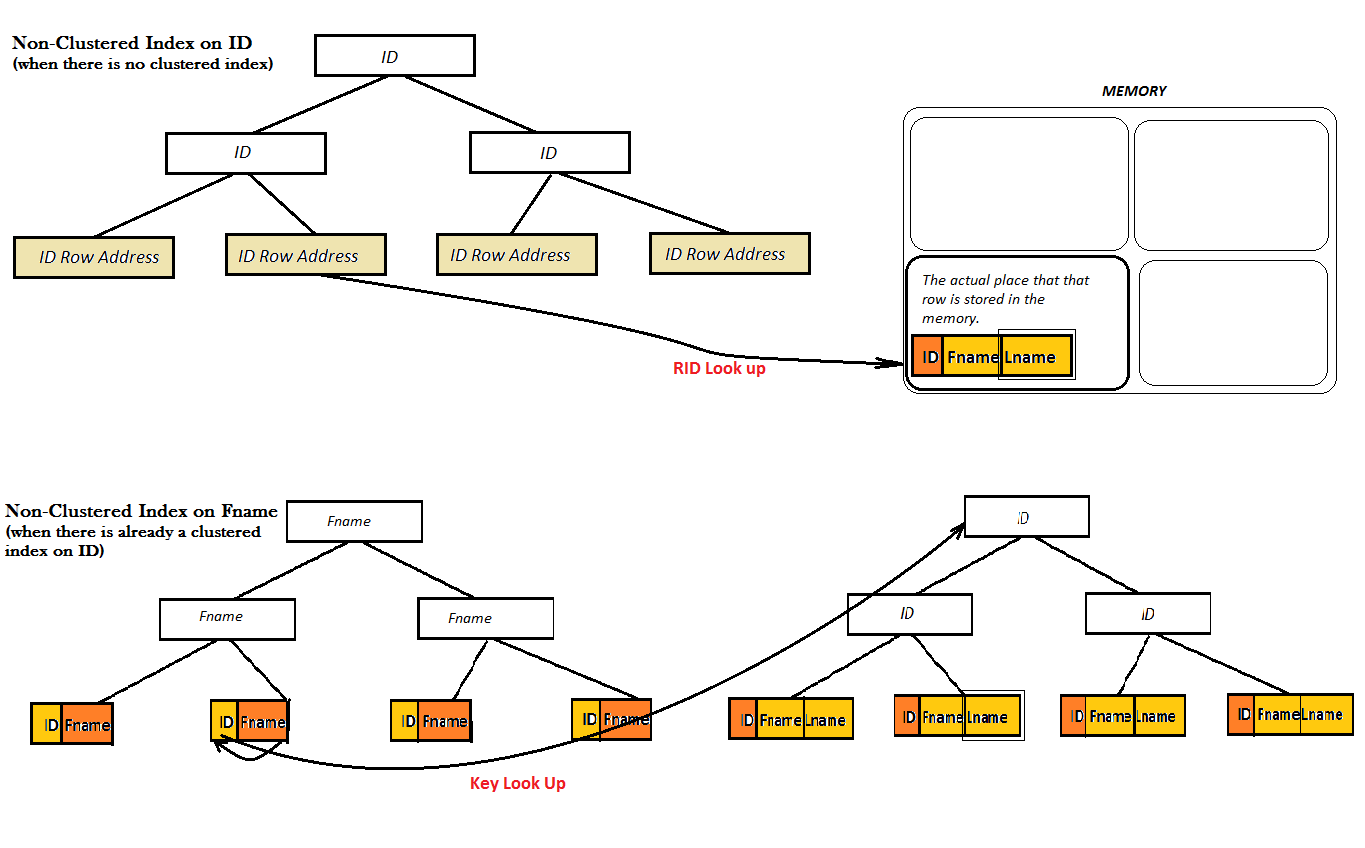
As the two diagrams show, such Non-Clustered indexes do not provide a good performance, because they cannot find the favorite value (i.e. Lname) solely from the B-Tree. Instead they have to do an extra Look Up step (either Key or RID look up) to find the value of Lname. And, this is where covered index comes to the screen. Here, the Non-Clustered index on ID coveres the value of Lname right next to it in the leaves of the B-Tree and there is no need for any type of look up anymore.
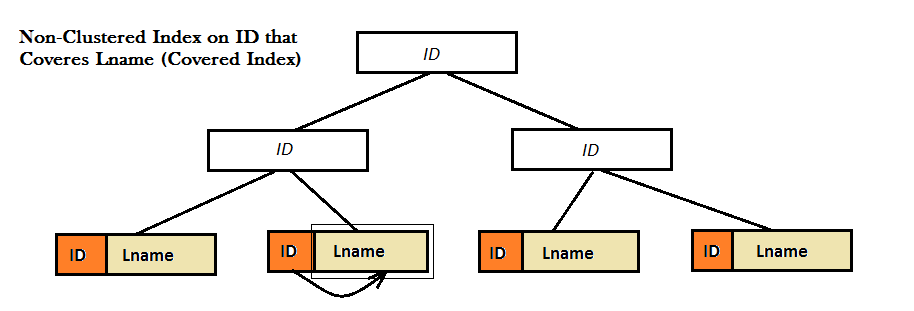
A covered query is a query where all the columns in the query's result set are pulled from non-clustered indexes.
A query is made into a covered query by the judicious arrangement of indexes.
A covered query is often more performant than a non-covered query in part because non-clustered indexes have more rows per page than clustered indexes or heap indexes, so fewer pages need to be brought into memory in order to satisfy the query. They have more rows per page because only part of the table row is part of the index row.
A covering index is an index which is used in a covered query. There is no such thing as an index which, in and of itself, is a covering index. An index may be a covering index with respect to query A, while at the same time not being a covering index with respect to query B.
Since a significant aspect of the performance is "how many pages do I need to bring in to memory to return the full result set", then does that mean that a
LIMIT 1 query does not benefit from the covering optimisation? In most cases, grabbing a single record will require only a single page read (ignoring edge-cases like off-page storage or really wide tables). Even with a non-covered query. –
Padus Here's an article in devx.com that says:
Creating a non-clustered index that contains all the columns used in a SQL query, a technique called index covering
I can only suppose that a covered query is a query that has an index that covers all the columns in its returned recordset. One caveat - the index and query would have to be built as to allow the SQL server to actually infer from the query that the index is useful.
For example, a join of a table on itself might not benefit from such an index (depending on the intelligence of the SQL query execution planner):
PersonID ParentID Name
1 NULL Abe
2 NULL Bob
3 1 Carl
4 2 Dave
Let's assume there's an index on PersonID,ParentID,Name - this would be a covering index for a query like:
SELECT PersonID, ParentID, Name FROM MyTable
But a query like this:
SELECT PersonID, Name FROM MyTable LEFT JOIN MyTable T ON T.PersonID=MyTable.ParentID
Probably wouldn't benifit so much, even though all of the columns are in the index. Why? Because you're not really telling it that you want to use the triple index of PersonID,ParentID,Name.
Instead, you're building a condition based on two columns - PersonID and ParentID (which leaves out Name) and then you're asking for all the records, with the columns PersonID, Name. Actually, depending on implementation, the index might help the latter part. But for the first part, you're better off having other indexes.
a covering index is the one which gives every required column and in which SQL server don't have hop back to the clustered index to find any column. This is achieved using non-clustered index and using INCLUDE option to cover columns. Non-key columns can be included only in non-clustered indexes. Columns can’t be defined in both the key column and the INCLUDE list. Column names can’t be repeated in the INCLUDE list. Non-key columns can be dropped from a table only after the non-key index is dropped first. Please see details here
A covering query is on where all the predicates can be matched using the indices on the underlying tables.
This is the first step towards improving the performance of the sql under consideration.
When I simply recalled that a Clustered Index consists of a key-ordered non-heap list of ALL the columns in the defined table, the lights went on for me. The word "cluster", then, refers to the fact that there is a "cluster" of all the columns, like a cluster of fish in that "hot spot". If there is no index covering the column containing the sought value (the right side of the equation), then the execution plan uses a Clustered Index Seek into the Clustered Index's representation of the requested column because it does not find the requested column in any other "covering" index. The missing will cause a Clustered Index Seek operator in the proposed Execution Plan, where the sought value is within a column inside the ordered list represented by the Clustered Index.
So, one solution is to create a non-clustered index that has the column containing the requested value inside the index. In this way, there is no need to reference the Clustered Index, and the Optimizer should be able to hook that index in the Execution Plan with no hint. If, however, there is a Predicate naming the single column clustering key and an argument to a scalar value on the clustering key, the Clustered Index Seek Operator will still be used, even if there is already a covering index on a second column in the table without an index.
Page 178, High Performance MySQL, 3rd Edition
An index that contains (or "covers") all the data needed to satisfy a query is called a covering index.
When you issue a query that is covered by an index (an indexed-covered query), you'll see "Using Index" in the Extra column in EXPLAIN.
© 2022 - 2024 — McMap. All rights reserved.