Hopefully I'm reading this wrong but in the XGBoost library documentation, there is note of extracting the feature importance attributes using feature_importances_ much like sklearn's random forest.
However, for some reason, I keep getting this error: AttributeError: 'XGBClassifier' object has no attribute 'feature_importances_'
My code snippet is below:
from sklearn import datasets
import xgboost as xg
iris = datasets.load_iris()
X = iris.data
Y = iris.target
Y = iris.target[ Y < 2] # arbitrarily removing class 2 so it can be 0 and 1
X = X[range(1,len(Y)+1)] # cutting the dataframe to match the rows in Y
xgb = xg.XGBClassifier()
fit = xgb.fit(X, Y)
fit.feature_importances_
It seems that you can compute feature importance using the Booster object by calling the get_fscore attribute. The only reason I'm using XGBClassifier over Booster is because it is able to be wrapped in a sklearn pipeline. Any thoughts on feature extractions? Is anyone else experiencing this?
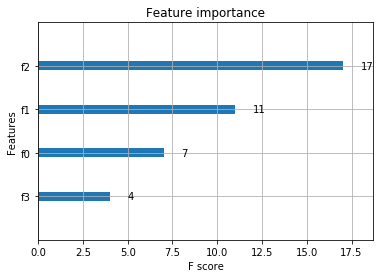
pip freeze, i havexgboost==0.4a30– Hedwigget_fscoremethod is bound to theBoosterobject rather thanXGBClassifierfrom my understanding. See the doc here – Hedwig0.4a30right? It appears so looking at their repo – Hedwigfeature_importances_via booster() are you able to get the column names accurately ? In my case, it throws a KeyError that not certain features are not present in the data. – GloriXGBClassifierfeature importance with names directly: xgboosting.com/… – Methanol