Since no one else has given a direct answer to the question that was asked, I'll do it.
The answer is that with POSIX grep, it's impossible to literally satisfy this request:
grep "<Regex for 'doesn't contain hede'>" input
The reason is that with no flags, POSIX grep is only required to work with Basic Regular Expressions (BREs), which are simply not powerful enough for accomplishing that task, because of lack of alternation in subexpressions. The only kind of alternation it supports involves providing multiple regular expressions separated by newlines, and that doesn't cover all regular languages, e.g. there's no finite collection of BREs that matches the same regular language as the extended regular expression (ERE) ^(ab|cd)*$.
However, GNU grep implements extensions that allow it. In particular, \| is the alternation operator in GNU's implementation of BREs. If your regular expression engine supports alternation, parentheses and the Kleene star, and is able to anchor to the beginning and end of the string, that's all you need for this approach. Note however that negative sets [^ ... ] are very convenient in addition to those, because otherwise, you need to replace them with an expression of the form (a|b|c| ... ) that lists every character that is not in the set, which is extremely tedious and overly long, even more so if the whole character set is Unicode.
Thanks to formal language theory, we get to see how such an expression looks like. With GNU grep, the answer would be something like:
grep "^\([^h]\|h\(h\|eh\|edh\)*\([^eh]\|e[^dh]\|ed[^eh]\)\)*\(\|h\(h\|eh\|edh\)*\(\|e\|ed\)\)$" input
(found with Grail and some further optimizations made by hand).
You can also use a tool that implements EREs, like egrep, to get rid of the backslashes, or equivalently, pass the -E flag to POSIX grep (although I was under the impression that the question required avoiding any flags to grep whatsoever):
egrep "^([^h]|h(h|eh|edh)*([^eh]|e[^dh]|ed[^eh]))*(|h(h|eh|edh)*(|e|ed))$" input
Here's a script to test it (note it generates a file testinput.txt in the current directory). Several of the expressions presented in other answers fail this test.
#!/bin/bash
REGEX="^\([^h]\|h\(h\|eh\|edh\)*\([^eh]\|e[^dh]\|ed[^eh]\)\)*\(\|h\(h\|eh\|edh\)*\(\|e\|ed\)\)$"
# First four lines as in OP's testcase.
cat > testinput.txt <<EOF
hoho
hihi
haha
hede
h
he
ah
head
ahead
ahed
aheda
ahede
hhede
hehede
hedhede
hehehehehehedehehe
hedecidedthat
EOF
diff -s -u <(grep -v hede testinput.txt) <(grep "$REGEX" testinput.txt)
In my system it prints:
Files /dev/fd/63 and /dev/fd/62 are identical
as expected.
For those interested in the details, the technique employed is to convert the regular expression that matches the word into a finite automaton, then invert the automaton by changing every acceptance state to non-acceptance and vice versa, and then converting the resulting FA back to a regular expression.
As everyone has noted, if your regular expression engine supports negative lookahead, the regular expression is much simpler. For example, with GNU grep:
grep -P '^((?!hede).)*$' input
However, this approach has the disadvantage that it requires a backtracking regular expression engine. This makes it unsuitable in installations that are using secure regular expression engines like RE2, which is one reason to prefer the generated approach in some circumstances.
Using Kendall Hopkins' excellent FormalTheory library, written in PHP, which provides a functionality similar to Grail, and a simplifier written by myself, I've been able to write an online generator of negative regular expressions given an input phrase (only alphanumeric and space characters currently supported, and the length is limited): http://www.formauri.es/personal/pgimeno/misc/non-match-regex/
For hede it outputs:
^([^h]|h(h|e(h|dh))*([^eh]|e([^dh]|d[^eh])))*(h(h|e(h|dh))*(ed?)?)?$
which is equivalent to the above.
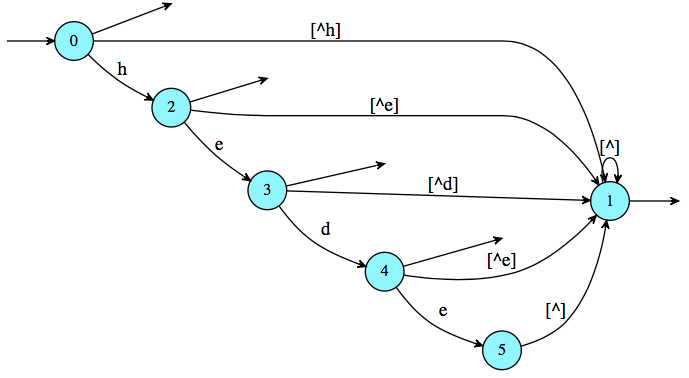

([^h]*(h([^e]|$)|he([^d]|$)|hed([^e]|$)))*? The idea is simple. Keep matching until you see the start of the unwanted string, then only match in the N-1 cases where the string is unfinished (where N is the length of the string). These N-1 cases are "h followed by non-e", "he followed by non-d", and "hed followed by non-e". If you managed to pass these N-1 cases, you successfully didn't match the unwanted string so you can start looking for[^h]*again – Cyrilcyrill^([^h]*(h([^e]|$)|he([^d]|$)|hed([^e]|$))?)*$this fails when instances of "hede" are preceded by partial instances of "hede" such as in "hhede". – Heavyladen