How do I write JSON data stored in the dictionary data to a file?
f = open('data.json', 'wb')
f.write(data)
This gives the error:
TypeError: must be string or buffer, not dict
How do I write JSON data stored in the dictionary data to a file?
f = open('data.json', 'wb')
f.write(data)
This gives the error:
TypeError: must be string or buffer, not dict
data is a Python dictionary. It needs to be encoded as JSON before writing.
Use this for maximum compatibility (Python 2 and 3):
import json
with open('data.json', 'w') as f:
json.dump(data, f)
On a modern system (i.e. Python 3 and UTF-8 support), you can write a nicer file using:
import json
with open('data.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
See json documentation.
json.dump writes to a file or file-like object, whereas json.dumps returns a string. –
Ouzo [{"name":"Jack", "age":34}, {"name":"Joe", "age":54}], not "[{"name":"Jack", "age":34}, , {"name":"Joe", "age":54}]". I just used context manager with f.write(json_string), instead of json.dumps(json_string) and it works. Because the json string that I produced is coming from dataframe.to_json(). –
Axle To get utf8-encoded file as opposed to ascii-encoded in the accepted answer for Python 2 use:
import io, json
with io.open('data.txt', 'w', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False))
The code is simpler in Python 3:
import json
with open('data.txt', 'w') as f:
json.dump(data, f, ensure_ascii=False)
On Windows, the encoding='utf-8' argument to open is still necessary.
To avoid storing an encoded copy of the data in memory (result of dumps) and to output utf8-encoded bytestrings in both Python 2 and 3, use:
import json, codecs
with open('data.txt', 'wb') as f:
json.dump(data, codecs.getwriter('utf-8')(f), ensure_ascii=False)
The codecs.getwriter call is redundant in Python 3 but required for Python 2
Readability and size:
The use of ensure_ascii=False gives better readability and smaller size:
>>> json.dumps({'price': '€10'})
'{"price": "\\u20ac10"}'
>>> json.dumps({'price': '€10'}, ensure_ascii=False)
'{"price": "€10"}'
>>> len(json.dumps({'абвгд': 1}))
37
>>> len(json.dumps({'абвгд': 1}, ensure_ascii=False).encode('utf8'))
17
Further improve readability by adding flags indent=4, sort_keys=True (as suggested by dinos66) to arguments of dump or dumps. This way you'll get a nicely indented sorted structure in the json file at the cost of a slightly larger file size.
unicode is superfluous - the result of json.dumps is already a unicode object. Note that this fails in 3.x, where this whole mess of output file mode has been cleaned up, and json always uses character strings (and character I/O) and never bytes. –
Ouzo I would answer with slight modification with aforementioned answers and that is to write a prettified JSON file which human eyes can read better. For this, pass sort_keys as True and indent with 4 space characters and you are good to go. Also take care of ensuring that the ascii codes will not be written in your JSON file:
with open('data.txt', 'w') as out_file:
json.dump(json_data, out_file, sort_keys = True, indent = 4,
ensure_ascii = False)
# -*- coding: utf-8 -*-
import json
# Make it work for Python 2+3 and with Unicode
import io
try:
to_unicode = unicode
except NameError:
to_unicode = str
# Define data
data = {'a list': [1, 42, 3.141, 1337, 'help', u'€'],
'a string': 'bla',
'another dict': {'foo': 'bar',
'key': 'value',
'the answer': 42}}
# Write JSON file
with io.open('data.json', 'w', encoding='utf8') as outfile:
str_ = json.dumps(data,
indent=4, sort_keys=True,
separators=(',', ': '), ensure_ascii=False)
outfile.write(to_unicode(str_))
# Read JSON file
with open('data.json') as data_file:
data_loaded = json.load(data_file)
print(data == data_loaded)
Explanation of the parameters of json.dump:
indent: Use 4 spaces to indent each entry, e.g. when a new dict is started (otherwise all will be in one line),sort_keys: sort the keys of dictionaries. This is useful if you want to compare json files with a diff tool / put them under version control.separators: To prevent Python from adding trailing whitespacesHave a look at my utility package mpu for a super simple and easy to remember one:
import mpu.io
data = mpu.io.read('example.json')
mpu.io.write('example.json', data)
{
"a list":[
1,
42,
3.141,
1337,
"help",
"€"
],
"a string":"bla",
"another dict":{
"foo":"bar",
"key":"value",
"the answer":42
}
}
.json
For your application, the following might be important:
See also: Comparison of data serialization formats
In case you are rather looking for a way to make configuration files, you might want to read my short article Configuration files in Python
For those of you who are trying to dump greek or other "exotic" languages such as me but are also having problems (unicode errors) with weird characters such as the peace symbol (\u262E) or others which are often contained in json formated data such as Twitter's, the solution could be as follows (sort_keys is obviously optional):
import codecs, json
with codecs.open('data.json', 'w', 'utf8') as f:
f.write(json.dumps(data, sort_keys = True, ensure_ascii=False))
I don't have enough reputation to add in comments, so I just write some of my findings of this annoying TypeError here:
Basically, I think it's a bug in the json.dump() function in Python 2 only - It can't dump a Python (dictionary / list) data containing non-ASCII characters, even you open the file with the encoding = 'utf-8' parameter. (i.e. No matter what you do). But, json.dumps() works on both Python 2 and 3.
To illustrate this, following up phihag's answer: the code in his answer breaks in Python 2 with exception TypeError: must be unicode, not str, if data contains non-ASCII characters. (Python 2.7.6, Debian):
import json
data = {u'\u0430\u0431\u0432\u0433\u0434': 1} #{u'абвгд': 1}
with open('data.txt', 'w') as outfile:
json.dump(data, outfile)
It however works fine in Python 3.
unicode() part. I just realised for io package in Python 2, write() needs unicode, not str. –
Aplasia Write a data in file using JSON use json.dump() or json.dumps() used. write like this to store data in file.
import json
data = [1,2,3,4,5]
with open('no.txt', 'w') as txtfile:
json.dump(data, txtfile)
this example in list is store to a file.
json.dump(data, open('data.txt', 'wb'))
f = open('1.txt', 'w'); f.write('a'); input(). Run it and then SYGTERM it (Ctrl-Z then kill %1 on linux, Ctrl-Break on Windows). 1.txt will have 0 bytes. It is because the writing was buffered and the file was neither flushed not closed at the moment when SYGTERM occurred. with block guarantees that the file always gets closed just like 'try/finally' block does but shorter. –
Totter To write the JSON with indentation, "pretty print":
import json
outfile = open('data.json')
json.dump(data, outfile, indent=4)
Also, if you need to debug improperly formatted JSON, and want a helpful error message, use import simplejson library, instead of import json (functions should be the same)
open('data.json') open the file in read only mode? –
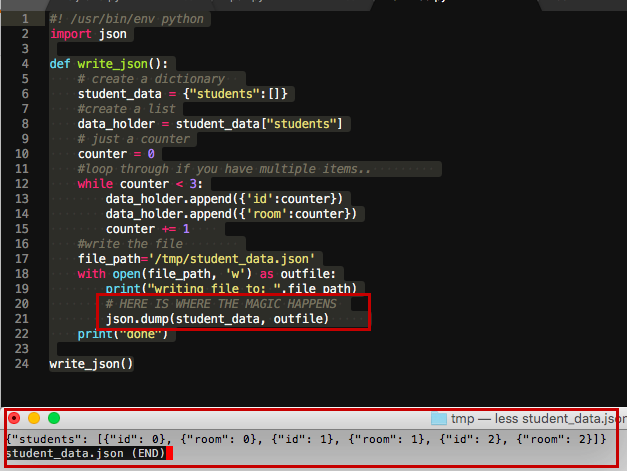
Lippold All previous answers are correct here is a very simple example:
#! /usr/bin/env python
import json
def write_json():
# create a dictionary
student_data = {"students":[]}
#create a list
data_holder = student_data["students"]
# just a counter
counter = 0
#loop through if you have multiple items..
while counter < 3:
data_holder.append({'id':counter})
data_holder.append({'room':counter})
counter += 1
#write the file
file_path='/tmp/student_data.json'
with open(file_path, 'w') as outfile:
print("writing file to: ",file_path)
# HERE IS WHERE THE MAGIC HAPPENS
json.dump(student_data, outfile)
outfile.close()
print("done")
write_json()
Before write a dictionary into a file as a json, you have to turn that dict onto json string using json library.
import json
data = {
"field1":{
"a": 10,
"b": 20,
},
"field2":{
"c": 30,
"d": 40,
},
}
json_data = json.dumps(json_data)
And also you can add indent to json data to look prettier.
json_data = json.dumps(json_data, indent=4)
If you want to sort keys before turning into json,
json_data = json.dumps(json_data, sort_keys=True)
You can use the combination of these two also.
Refer the json documentation here for much more features
Finally you can write into a json file
f = open('data.json', 'wb')
f.write(json_data)
For people liking oneliners (hence with statement is not an option), a cleaner method than leaving a dangling opened file descriptor behind can be to use write_text from pathlib and do something like below:
pathlib.Path("data.txt").write_text(json.dumps(data))
This can be handy in some cases in contexts where statements are not allowed like:
[pathlib.Path(f"data_{x}.json").write_text(json.dumps(x)) for x in [1, 2, 3]]
I'm not claiming it should be preferred to with (and it's likely slower), just another option.
if you are trying to write a pandas dataframe into a file using a json format i'd recommend this
destination='filepath'
saveFile = open(destination, 'w')
saveFile.write(df.to_json())
saveFile.close()
The accepted answer is fine. However, I ran into "is not json serializable" error using that.
Here's how I fixed it
with open("file-name.json", 'w') as output:
output.write(str(response))
Although it is not a good fix as the json file it creates will not have double quotes, however it is great if you are looking for quick and dirty.
The JSON data can be written to a file as follows
hist1 = [{'val_loss': [0.5139984398465246],
'val_acc': [0.8002029867684085],
'loss': [0.593220705309384],
'acc': [0.7687131817929321]},
{'val_loss': [0.46456472964199463],
'val_acc': [0.8173602046780344],
'loss': [0.4932038113037539],
'acc': [0.8063946213802453]}]
Write to a file:
with open('text1.json', 'w') as f:
json.dump(hist1, f)
This is just an extra hint at the usage of json.dumps (this is not an answer to the problem of the question, but a trick for those who have to dump numpy data types):
If there are NumPy data types in the dictionary, json.dumps() needs an additional parameter, credits go to TypeError: Object of type 'ndarray' is not JSON serializable, and it will also fix errors like TypeError: Object of type int64 is not JSON serializable and so on:
class NumpyEncoder(json.JSONEncoder):
""" Special json encoder for np types """
def default(self, obj):
if isinstance(obj, (np.int_, np.intc, np.intp, np.int8,
np.int16, np.int32, np.int64, np.uint8,
np.uint16, np.uint32, np.uint64)):
return int(obj)
elif isinstance(obj, (np.float_, np.float16, np.float32,
np.float64)):
return float(obj)
elif isinstance(obj, (np.ndarray,)):
return obj.tolist()
return json.JSONEncoder.default(self, obj)
And then run:
import json
#print(json.dumps(my_data[:2], indent=4, cls=NumpyEncoder)))
with open(my_dir+'/my_filename.json', 'w') as f:
json.dumps(my_data, indent=4, cls=NumpyEncoder)))
You may also want to return a string instead of a list in case of a np.array() since arrays are printed as lists that are spread over rows which will blow up the output if you have large or many arrays. The caveat: it is more difficult to access the items from the dumped dictionary later to get them back as the original array. Yet, if you do not mind having just a string of an array, this makes the dictionary more readable. Then exchange:
elif isinstance(obj, (np.ndarray,)):
return obj.tolist()
with:
elif isinstance(obj, (np.ndarray,)):
return str(obj)
or just:
else:
return str(obj)
json.dump and json.dumps, I cannot take the time to test this now and I guess I tested this anyway. This answer shall not replace the accepted answer, but add this special case (not special at all, numpy datatypes are common). –
Upraise dumps instead of dump here so that you can use the parameters), and the class that makes numpy exports possible is just added. Nothing against downvoting for the right sake, but please think this over. –
Upraise © 2022 - 2024 — McMap. All rights reserved.
pathlibwith one line:Path("data.json").write_text(json.dumps(data))– Afroasian