I've had some success using the PDFTextStripperByArea class to retrieve text contained within a specified rectangle. However, some of the PDFs I an scraping have text that is in slightly different places from page to page. I'm looking for help in how to deal with this.
In the example below, I can open the PDF in Acrobat Edit mode and see multiple text boxes (outlines with thin grey lines). I have indicated two regions (purple and red) that I would like to extract text from. However, instead of just getting the text physically inside the rectangle, I'd like all the text from the overlapping text boxes.
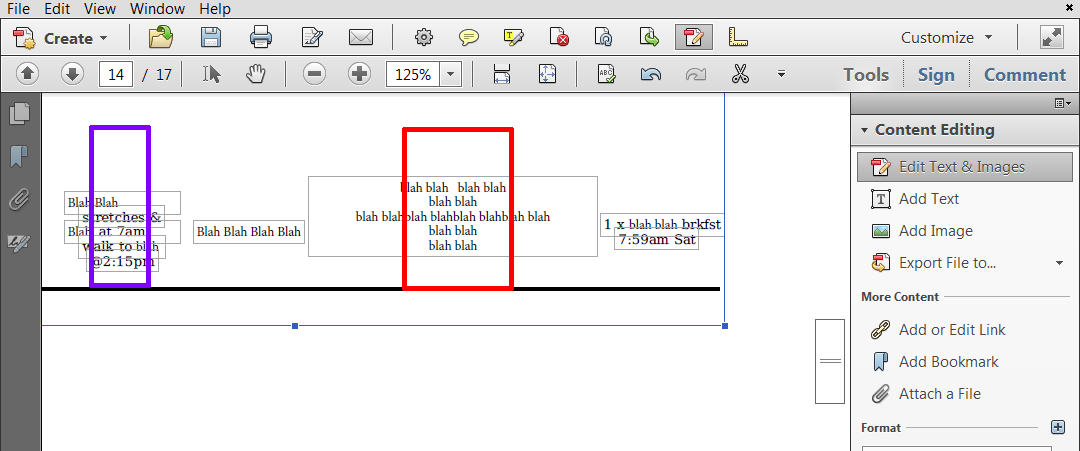
Is there a way to do this?