The reason is exactly like what was said in jamesdlin's answers and the comments below it: MBCS is the same as DBCS in Windows and some functions don't work with characters that are longer than 2 bytes
Microsoft said that a UTF-8 locale might break some functions as they were written to assume multibyte encodings used no more than 2 bytes per character, thus code pages with more bytes such as UTF-8 (and also GB 18030, cp54936) could not be set as the locale.
https://en.wikipedia.org/wiki/Unicode_in_Microsoft_Windows#UTF-8
So UTF-8 was allowed in functions like read/write but not when using as a locale
However Microsoft has finally fixed that so now we can use UTF-8 as a locale. In fact MS even started recommending the ANSI APIs (-A) again instead of the Unicode (-W) versions like before. There are some new options in MSVC: /execution-charset:utf-8 and /utf-8 to set the charset, or you can also set the ActiveCodePage property in appxmanifest of the UWP app
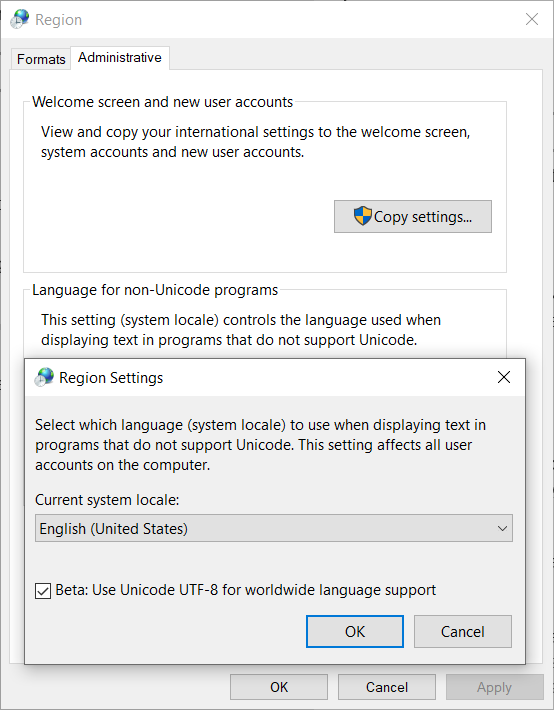
Since Windows 10 insider build 17035, before those options were introduced, a "Beta: Use Unicode UTF-8 for worldwide language support" checkbox had also been added for setting the locale code page to UTF-8
![Beta: Use Unicode UTF-8 for worldwide language support]()
To open that dialog box open start menu, type "region" and select Region settings > Additional date, time & regional settings > Change date, time, or number formats > Administrative
After enabling it you can call setlocale() to change to UTF-8 locale:
Starting in Windows 10 build 17134 (April 2018 Update), the Universal C Runtime supports using a UTF-8 code page. This means that char strings passed to C runtime functions will expect strings in the UTF-8 encoding. To enable UTF-8 mode, use "UTF-8" as the code page when using setlocale. For example, setlocale(LC_ALL, ".utf8") will use the current default Windows ANSI code page (ACP) for the locale and UTF-8 for the code page.
UTF-8 Support
You can also use this in older Windows versions
To use this feature on an OS prior to Windows 10, such as Windows 7, you must use app-local deployment or link statically using version 17134 of the Windows SDK or later. For Windows 10 operating systems prior to 17134, only static linking is supported.
See also
WriteFile(). – Affluence