tcmalloc/jemalloc are improved memory allocators, and memory pool is also introduced for better memory allocation. So what are the differences between them and how to choose them in my application?
What are the differences between (and reasons to choose) tcmalloc/jemalloc and memory pools?
Why not try them both and see which one works better for you? There is no right answer to this question without us having a lot more information about your use-case. –
Carburet
First your application has to be doing a lot of allocations /deallocaitons. Then it has to be really performance critical . Then you have to profile it and prove that the heap allocation is actually your bottleneck. Only then it makes sense to start trying different allocators. Your stock one might be already good enough. –
Prepotent
As long as you do not handle thousands of allocations per second it is pointless to use any of them. They are build for specific purposes. Do not confuse them with a memory pool which is a static memory allocation, where the behavior has to be handled with unique logic that fist your program. –
Sarcoma
Summary from this doc
Tcmalloc
tcmalloc is a memory management library open sourced by Google as an alternative to glibc malloc. It has been used in well-known software such as chrome and safari. According to the official test report, ptmalloc takes about 300 nanoseconds to execute malloc and free on a 2.8GHz P4 machine (for small objects). The TCMalloc version takes about 50 nanoseconds for the same operation.
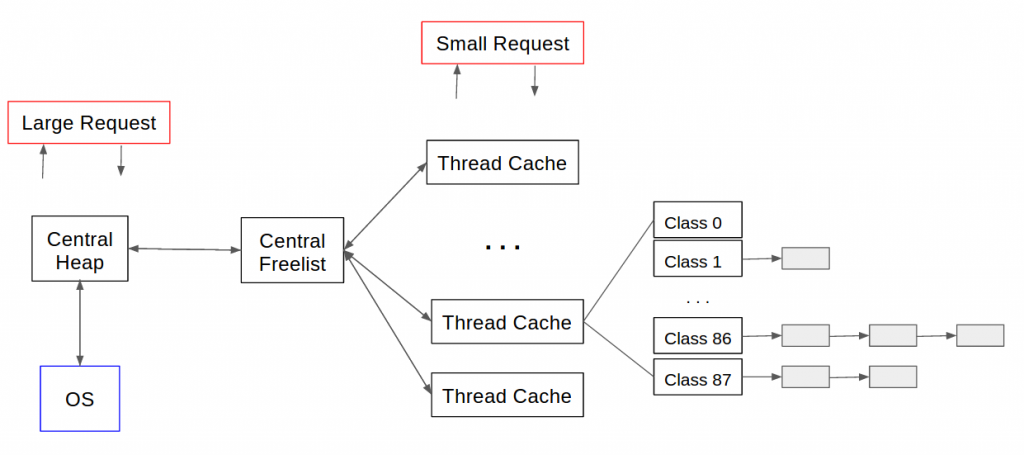
- Small object allocation
- tcmalloc allocates a thread-local ThreadCache for each thread. Small memory is allocated from ThreadCache. In addition, there is a central heap (CentralCache). When ThreadCache is not enough, it will get space from CentralCache and put it in ThreadCache.
- Small objects (<=32K) are allocated from ThreadCache, and large objects are allocated from CentralCache. The space allocated by large objects is aligned with 4k pages, and multiple pages can also be cut into multiple small objects and divided into ThreadCache
- CentralCache allocation management
- Large objects (>32K) are first aligned with 4k and then allocated from CentralCache.
- When there is no free space in the page linked list of the best fit, the page space is always larger. If all 256 linked lists are traversed, the allocation is still not successful. Use sbrk, mmap,/dev/mem to allocate from the system.
- The contiguous pages managed by tcmalloc PageHeap are called span. If span is not allocated, span is a linked list element in PageHeap.
- Recycle
- When an object is free, the page number is calculated according to the address alignment, and then the corresponding span is found through the central array.
- If it is a small object, span will tell us its size class, and then insert the object into the ThreadCache of the current thread. If ThreadCache exceeds a budget value (default 2MB) at this time, the garbage collection mechanism will be used to move unused objects from ThreadCache to CentralCache's central free lists.
- If it is a large object, span will tell us the page number range where the object is locked. Assuming that this range is [p,q], first search for the span where pages p-1 and q+1 are located. If these adjacent spans are also free, merge them into the span where [p,q] is located, and then recycle this span To PageHeap.
- The central free lists of CentralCache are similar to the FreeList of ThreadCache, but it adds a first-level structure.
![enter image description here]()
- TEMERAIRE is an enhancement of TCMalloc, which is specifically designed to be hugepage-aware.
- This enhancement addresses the need for improved memory allocation in large-scale data centers by optimizing hugepage coverage, reducing fragmentation, and enhancing overall application performance.
- Small object allocation
Jemalloc
jemalloc was launched by facebook, and it was first implemented by freebsd's libc malloc. At present, it is widely used in various components of firefox and facebook server.
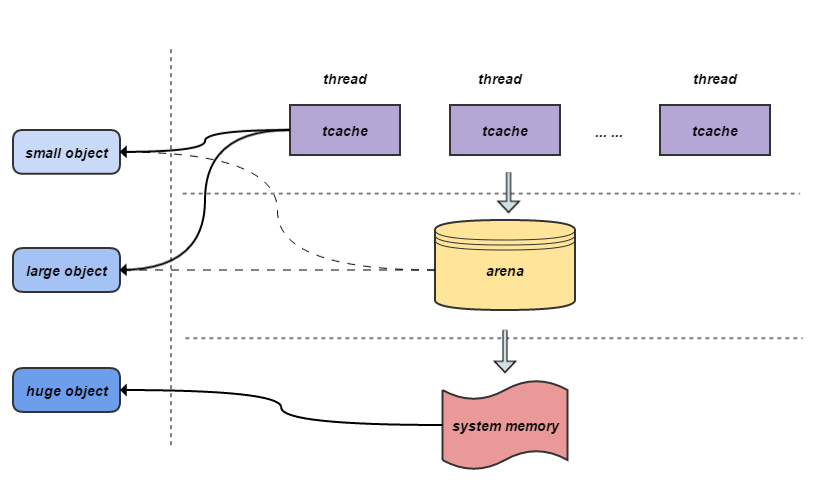
- memory management
- Similar to tcmalloc, each thread also uses thread-local cache without lock when it is less than 32KB.
- Jemalloc uses the following size-class classifications on 64bits systems: Small: [8], [16, 32, 48, …, 128], [192, 256, 320, …, 512], [768, 1024, 1280, …, 3840] Large: [4 KiB, 8 KiB, 12 KiB, …, 4072 KiB] Huge: [4 MiB, 8 MiB, 12 MiB, …]
- Small/large objects need constant time to find metadata, and huge objects are searched in logarithmic time through the global red-black tree.
- The virtual memory is logically divided into chunks (the default is 4MB, 1024 4k pages), and the application thread allocates arenas at the first malloc through the round-robin algorithm. Each arena is independent of each other and maintains its own chunks. Chunk cuts pages into small/large objects. The memory of free() is always returned to the arena to which it belongs, regardless of which thread calls free().
![enter image description here]()
- memory management
Compare
- The biggest advantage of jemalloc is its powerful multi-core/multi-thread allocation capability. The more cores the CPU has, the more program threads, and the faster jemalloc allocates
- When allocating a lot of small memory, the space for recording meta data of jemalloc will be slightly more than tcmalloc.
- When allocating large memory allocations, there will also be less memory fragmentation than tcmalloc.
- Jemalloc classifies memory allocation granularity more finely, it leads to less lock contention than ptmalloc.
- TEMERAIRE enhancement is beneficial in scenarios where high-performance memory allocation is crucial, and where optimizing for hugepages can lead to significant efficiency gains in large-scale environments
Answer about tcmalloc probably needs an update. 1) The default is a per-cpu cache of small objects now (as opposed to ThreadCache). 2) probably its biggest selling point is it's huge page aware and puts an enormous amount of effort (at the cost of allocation speed) to maintain the systems huge pages and minimize TLB overhead of the application. –
Jeanniejeannine
@Noah, Thank you very much for your comment. One more question, the huge page aware could be done by tcmalloc ? –
Lubalubba
Yes. See this paper –
Jeanniejeannine
It depends upon requirement of your program. If your program has more dynamic memory allocations, then you need to choose a memory allocator, from available allocators, which would generate most optimal performance out of your program.
For good memory management you need to meet the following requirements at minimum:
- Check if your system has enough memory to process data.
- Are you albe to allocate from the available memory ?
- Returning the used memory / deallocated memory to the pool (program or operating system)
The ability of a good memory manager can be tested on basis of (at the bare minimum) its efficiency in retriving / allocating and returning / dellaocating memory. (There are many more conditions like cache locality, managing overhead, VM environments, small or large environments, threaded environment etc..)
With respect to tcmalloc and jemalloc there are many people who have done comparisions. With reference to one of the comparisions:
tcmalloc scores over all other in terms of CPU cycles per allocation if the number of threads are less. jemalloc is very close to tcmalloc but better than ptmalloc (std glibc implementation).
In terms of memory overhead jemalloc is the best, seconded by ptmalloc, followed by tcmalloc.
Overall it can be said that jemalloc scores over others. You can also read more about jemalloc here:
I have just quoted from tests done and published by other people and have not tested it myself. I hope this could be a good starting point for you and use it to test and select the most optimal for your application.
© 2022 - 2024 — McMap. All rights reserved.