I've got a dataframe df_a with id information:
unique_id lacet_number
15 5570613 TLA-0138365
24 5025490 EMP-0138757
36 4354431 DXN-0025343
and another dataframe df_b, with the same number of rows that I know correspond to the rows in df_a:
latitude longitude
0 -93.193560 31.217029
1 -93.948082 35.360874
2 -103.131508 37.787609
What I want to do is simply concatenate the two horizontally (similar to cbind in R) and get:
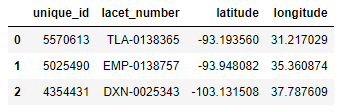
unique_id lacet_number latitude longitude
0 5570613 TLA-0138365 -93.193560 31.217029
1 5025490 EMP-0138757 -93.948082 35.360874
2 4354431 DXN-0025343 -103.131508 37.787609
What I have tried:
df_c = pd.concat([df_a, df_b], axis=1)
which gives me an outer join.
unique_id lacet_number latitude longitude
0 NaN NaN -93.193560 31.217029
1 NaN NaN -93.948082 35.360874
2 NaN NaN -103.131508 37.787609
15 5570613 TLA-0138365 NaN NaN
24 5025490 EMP-0138757 NaN NaN
36 4354431 DXN-0025343 NaN NaN
The problem is that the indices for the two dataframes do not match. I read the documentation for pandas.concat, and saw that there is an option ignore_index. But that only applies to the concatenation axis, in my case the columns and it certainly is not the right choice for me. So my question is: is there a simple way to achieve this?
cbind()is an R function that concatenates dataframes and/or series ('vectors'), by column (pd.concat(..., axis=1)). However pandasconcat()tries to align indices, whereas R'scbind()ignores them. – Bedfellow