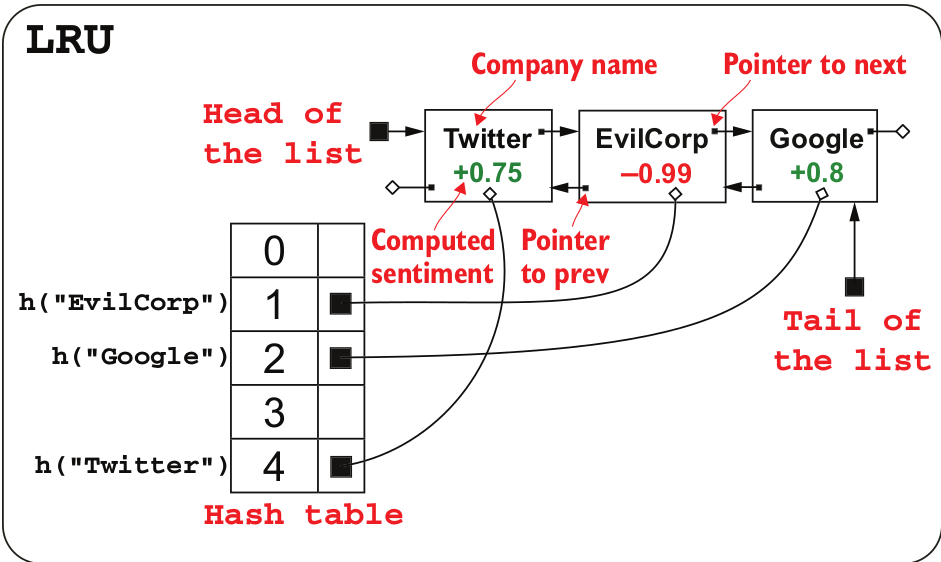
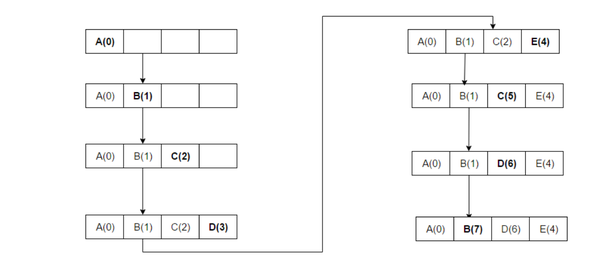
I implemented a thread-safe LRU cache two years back.
LRU is typically implemented with a HashMap and LinkedList. You can google the implementation detail. There are a lot of resources about it(Wikipedia have a good explanation too).
In order to be thread-safe, you need put lock whenever you modify the state of the LRU.
I will paste my C++ code here for your reference.
Here is the implementation.
/***
A template thread-safe LRU container.
Typically LRU cache is implemented using a doubly linked list and a hash map.
Doubly Linked List is used to store list of pages with most recently used page
at the start of the list. So, as more pages are added to the list,
least recently used pages are moved to the end of the list with page
at tail being the least recently used page in the list.
Additionally, this LRU provides time-to-live feature. Each entry has an expiration
datetime.
***/
#ifndef LRU_CACHE_H
#define LRU_CACHE_H
#include <iostream>
#include <list>
#include <boost/unordered_map.hpp>
#include <boost/shared_ptr.hpp>
#include <boost/make_shared.hpp>
#include <boost/date_time/posix_time/posix_time.hpp>
#include <boost/thread/mutex.hpp>
template <typename KeyType, typename ValueType>
class LRUCache {
private:
typedef boost::posix_time::ptime DateTime;
// Cache-entry
struct ListItem {
ListItem(const KeyType &key,
const ValueType &value,
const DateTime &expiration_datetime)
: m_key(key), m_value(value), m_expiration_datetime(expiration_datetime){}
KeyType m_key;
ValueType m_value;
DateTime m_expiration_datetime;
};
typedef boost::shared_ptr<ListItem> ListItemPtr;
typedef std::list<ListItemPtr> LruList;
typedef typename std::list<ListItemPtr>::iterator LruListPos;
typedef boost::unordered_map<KeyType, LruListPos> LruMapper;
// A mutext to ensuare thread-safety.
boost::mutex m_cache_mutex;
// Maximum number of entries.
std::size_t m_capacity;
// Stores cache-entries from latest to oldest.
LruList m_list;
// Mapper for key to list-position.
LruMapper m_mapper;
// Default time-to-live being add to entry every time we touch it.
unsigned long m_ttl_in_seconds;
/***
Note : This is a helper function whose function call need to be wrapped
within a lock. It returns true/false whether key exists and
not expires. Delete the expired entry if necessary.
***/
bool containsKeyHelper(const KeyType &key) {
bool has_key(m_mapper.count(key) != 0);
if (has_key) {
LruListPos pos = m_mapper[key];
ListItemPtr & cur_item_ptr = *pos;
// Remove the entry if key expires
if (isDateTimeExpired(cur_item_ptr->m_expiration_datetime)) {
has_key = false;
m_list.erase(pos);
m_mapper.erase(key);
}
}
return has_key;
}
/***
Locate an item in list by key, and move it at the front of the list,
which means make it the latest item.
Note : This is a helper function whose function call need to be wrapped
within a lock.
***/
void makeEntryTheLatest(const KeyType &key) {
if (m_mapper.count(key)) {
// Add original item at the front of the list,
// and update <Key, ListPosition> mapper.
LruListPos original_list_position = m_mapper[key];
const ListItemPtr & cur_item_ptr = *original_list_position;
m_list.push_front(cur_item_ptr);
m_mapper[key] = m_list.begin();
// Don't forget to update its expiration datetime.
m_list.front()->m_expiration_datetime = getExpirationDatetime(m_list.front()->m_expiration_datetime);
// Erase the item at original position.
m_list.erase(original_list_position);
}
}
public:
/***
Cache should have capacity to limit its memory usage.
We also add time-to-live for each cache entry to expire
the stale information. By default, ttl is one hour.
***/
LRUCache(std::size_t capacity, unsigned long ttl_in_seconds = 3600)
: m_capacity(capacity), m_ttl_in_seconds(ttl_in_seconds) {}
/***
Return now + time-to-live
***/
DateTime getExpirationDatetime(const DateTime &now) {
static const boost::posix_time::seconds ttl(m_ttl_in_seconds);
return now + ttl;
}
/***
If input datetime is older than current datetime,
then it is expired.
***/
bool isDateTimeExpired(const DateTime &date_time) {
return date_time < boost::posix_time::second_clock::local_time();
}
/***
Return the number of entries in this cache.
***/
std::size_t size() {
boost::mutex::scoped_lock lock(m_cache_mutex);
return m_mapper.size();
}
/***
Get value by key.
Return true/false whether key exists.
If key exists, input paramter value will get updated.
***/
bool get(const KeyType &key, ValueType &value) {
boost::mutex::scoped_lock lock(m_cache_mutex);
if (!containsKeyHelper(key)) {
return false;
} else {
// Make the entry the latest and update its TTL.
makeEntryTheLatest(key);
// Then get its value.
value = m_list.front()->m_value;
return true;
}
}
/***
Add <key, value> pair if no such key exists.
Otherwise, just update the value of old key.
***/
void put(const KeyType &key, const ValueType &value) {
boost::mutex::scoped_lock lock(m_cache_mutex);
if (containsKeyHelper(key)) {
// Make the entry the latest and update its TTL.
makeEntryTheLatest(key);
// Now we only need to update its value.
m_list.front()->m_value = value;
} else { // Key exists and is not expired.
if (m_list.size() == m_capacity) {
KeyType delete_key = m_list.back()->m_key;
m_list.pop_back();
m_mapper.erase(delete_key);
}
DateTime now = boost::posix_time::second_clock::local_time();
m_list.push_front(boost::make_shared<ListItem>(key, value,
getExpirationDatetime(now)));
m_mapper[key] = m_list.begin();
}
}
};
#endif
Here is the unit tests.
#include "cxx_unit.h"
#include "lru_cache.h"
struct LruCacheTest
: public FDS::CxxUnit::TestFixture<LruCacheTest>{
CXXUNIT_TEST_SUITE();
CXXUNIT_TEST(LruCacheTest, testContainsKey);
CXXUNIT_TEST(LruCacheTest, testGet);
CXXUNIT_TEST(LruCacheTest, testPut);
CXXUNIT_TEST_SUITE_END();
void testContainsKey();
void testGet();
void testPut();
};
void LruCacheTest::testContainsKey() {
LRUCache<int,std::string> cache(3);
cache.put(1,"1"); // 1
cache.put(2,"2"); // 2,1
cache.put(3,"3"); // 3,2,1
cache.put(4,"4"); // 4,3,2
std::string value_holder("");
CXXUNIT_ASSERT(cache.get(1, value_holder) == false); // 4,3,2
CXXUNIT_ASSERT(value_holder == "");
CXXUNIT_ASSERT(cache.get(2, value_holder) == true); // 2,4,3
CXXUNIT_ASSERT(value_holder == "2");
cache.put(5,"5"); // 5, 2, 4
CXXUNIT_ASSERT(cache.get(3, value_holder) == false); // 5, 2, 4
CXXUNIT_ASSERT(value_holder == "2"); // value_holder is still "2"
CXXUNIT_ASSERT(cache.get(4, value_holder) == true); // 4, 5, 2
CXXUNIT_ASSERT(value_holder == "4");
cache.put(2,"II"); // {2, "II"}, 4, 5
CXXUNIT_ASSERT(cache.get(2, value_holder) == true); // 2, 4, 5
CXXUNIT_ASSERT(value_holder == "II");
// Cache-entries : {2, "II"}, {4, "4"}, {5, "5"}
CXXUNIT_ASSERT(cache.size() == 3);
CXXUNIT_ASSERT(cache.get(2, value_holder) == true);
CXXUNIT_ASSERT(cache.get(4, value_holder) == true);
CXXUNIT_ASSERT(cache.get(5, value_holder) == true);
}
void LruCacheTest::testGet() {
LRUCache<int,std::string> cache(3);
cache.put(1,"1"); // 1
cache.put(2,"2"); // 2,1
cache.put(3,"3"); // 3,2,1
cache.put(4,"4"); // 4,3,2
std::string value_holder("");
CXXUNIT_ASSERT(cache.get(1, value_holder) == false); // 4,3,2
CXXUNIT_ASSERT(value_holder == "");
CXXUNIT_ASSERT(cache.get(2, value_holder) == true); // 2,4,3
CXXUNIT_ASSERT(value_holder == "2");
cache.put(5,"5"); // 5,2,4
CXXUNIT_ASSERT(cache.get(5, value_holder) == true); // 5,2,4
CXXUNIT_ASSERT(value_holder == "5");
CXXUNIT_ASSERT(cache.get(4, value_holder) == true); // 4, 5, 2
CXXUNIT_ASSERT(value_holder == "4");
cache.put(2,"II");
CXXUNIT_ASSERT(cache.get(2, value_holder) == true); // {2 : "II"}, 4, 5
CXXUNIT_ASSERT(value_holder == "II");
// Cache-entries : {2, "II"}, {4, "4"}, {5, "5"}
CXXUNIT_ASSERT(cache.size() == 3);
CXXUNIT_ASSERT(cache.get(2, value_holder) == true);
CXXUNIT_ASSERT(cache.get(4, value_holder) == true);
CXXUNIT_ASSERT(cache.get(5, value_holder) == true);
}
void LruCacheTest::testPut() {
LRUCache<int,std::string> cache(3);
cache.put(1,"1"); // 1
cache.put(2,"2"); // 2,1
cache.put(3,"3"); // 3,2,1
cache.put(4,"4"); // 4,3,2
cache.put(5,"5"); // 5,4,3
std::string value_holder("");
CXXUNIT_ASSERT(cache.get(2, value_holder) == false); // 5,4,3
CXXUNIT_ASSERT(value_holder == "");
CXXUNIT_ASSERT(cache.get(4, value_holder) == true); // 4,5,3
CXXUNIT_ASSERT(value_holder == "4");
cache.put(2,"II");
CXXUNIT_ASSERT(cache.get(2, value_holder) == true); // II,4,5
CXXUNIT_ASSERT(value_holder == "II");
// Cache-entries : {2, "II"}, {4, "4"}, {5, "5"}
CXXUNIT_ASSERT(cache.size() == 3);
CXXUNIT_ASSERT(cache.get(2, value_holder) == true);
CXXUNIT_ASSERT(cache.get(4, value_holder) == true);
CXXUNIT_ASSERT(cache.get(5, value_holder) == true);
}
CXXUNIT_REGISTER_TEST(LruCacheTest);