The Basic Idea
Why do people use dressers to store their clothing? Besides looking trendy and stylish, they have the advantage that every article of clothing has a place where it's supposed to be. If you're looking for a pair of socks, you just check the sock drawer. If you're looking for a shirt, you check the drawer that has your shirts in it. It doesn't matter, when you're looking for socks, how many shirts you have or how many pairs of pants you own, since you don't need to look at them. You just look in the sock drawer and expect to find socks there.
At a high level, a hash table is a way of storing things that is (kinda sorta ish) like a dresser for clothing. The basic idea is the following:
- You get some number of locations (drawers) where items can be stored.
- You come up with some rule that tells you which location (drawer) each item belongs.
- When you need to find something, you use that rule to determine which drawer to look into.
The advantage of a system like this is that, assuming your rule isn't too complicated and you have an appropriate number of drawers, you can find what you're looking for pretty quickly by simply looking in the right place.
When you're putting your clothes away, the "rule" you use might be something like "socks go in the top left drawer, and shirts go in the large middle drawer, etc." When you're storing more abstract data, though, we use something called a hash function to do this for us.
A reasonable way to think about a hash function is as a black box. You put data in one side, and a number called the hash code comes out of the other. Schematically, it looks something like this:
+---------+
|\| hash |/| --> hash code
data --> |/| function|\|
+---------+
All hash functions are deterministic: if you put the same data into the function multiple times, you'll always get the same value coming out the other side. And a good hash function should look more or less random: small changes to the input data should give wildly different hash codes. For example, the hash codes for the string "pudu" and for the string "kudu" will likely be wildly different from one another. (Then again, it's possible that they're the same. After all, if a hash function's outputs should look more or less random, there's a chance we get the same hash code twice.)
How exactly do you build a hash function? For now, let's go with "decent people shouldn't think too much about that." Mathematicians have worked out better and worse ways to design hash functions, but for our purposes we don't really need to worry too much about the internals. It's plenty good to just think of a hash function as a function that's
- deterministic (equal inputs give equal outputs), but
- looks random (it's hard to predict one hash code given another).
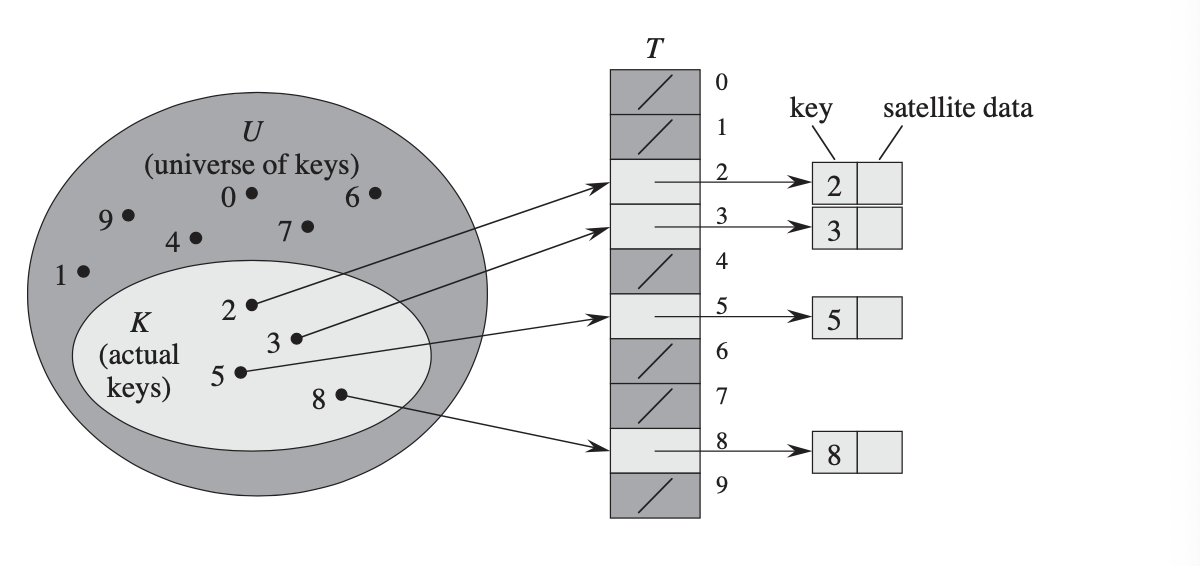
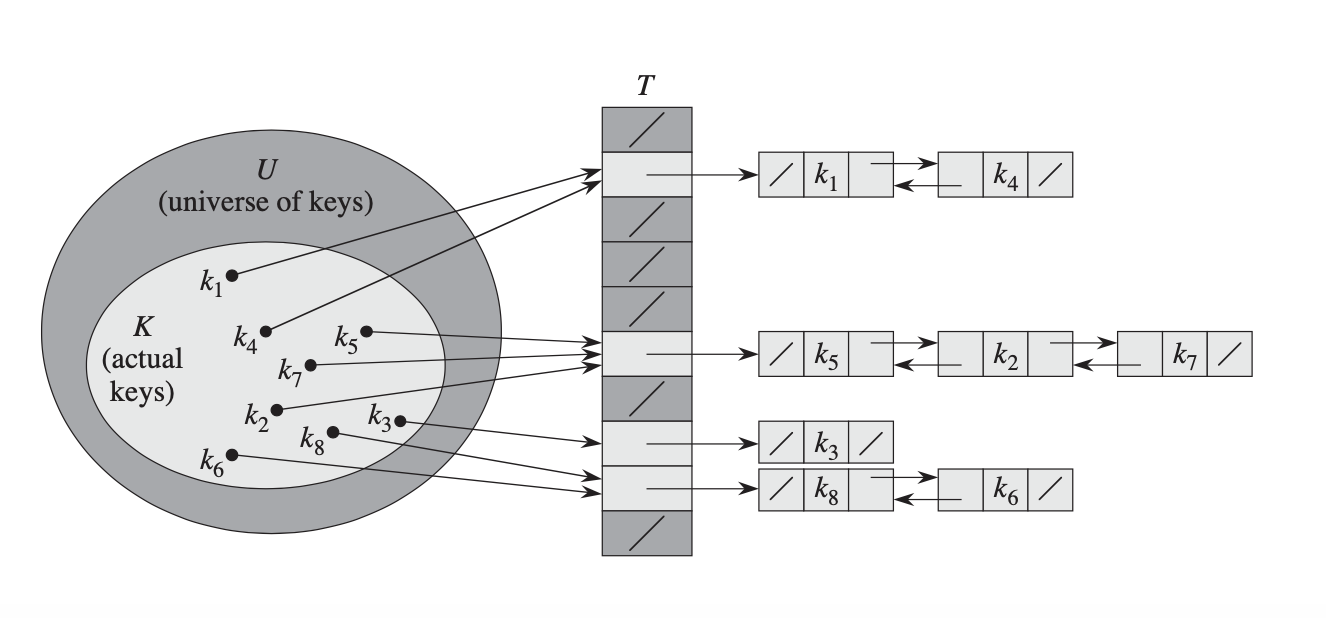
Once we have a hash function, we can build a very simple hash table. We'll make an array of "buckets," which you can think of as being analogous to drawers in our dresser. To store an item in the hash table, we'll compute the hash code of the object and use it as an index in the table, which is analogous to "pick which drawer this item goes in." Then, we put that data item inside the bucket at that index. If that bucket was empty, great! We can put the item there. If that bucket is full, we have some choices of what we can do. A simple approach (called chained hashing) is to treat each bucket as a list of items, the same way that your sock drawer might store multiple socks, and then just add the item to the list at that index.
To look something up in a hash table, we use basically the same procedure. We begin by computing the hash code for the item to look up, which tells us which bucket (drawer) to look in. If the item is in the table, it has to be in that bucket. Then, we just look at all the items in the bucket and see if our item is in there.
What's the advantage of doing things this way? Well, assuming we have a large number of buckets, we'd expect that most buckets won't have too many things in them. After all, our hash function kinda sorta ish looks like it has random outputs, so the items are distributed kinda sorta ish evenly across all the buckets. In fact, if we formalize the notion of "our hash function looks kinda random," we can prove that the expected number of items in each bucket is the ratio of the total number of items to the total number of buckets. Therefore, we can find the items we're looking for without having to do too much work.
The Details
Explaining how "a hash table" works is a bit tricky because there are many flavors of hash tables. This next section talks about a few general implementation details common to all hash tables, plus some specifics of how different styles of hash tables work.
A first question that comes up is how you turn a hash code into a table slot index. In the above discussion, I just said "use the hash code as an index," but that's actually not a very good idea. In most programming languages, hash codes work out to 32-bit or 64-bit integers, and you aren't going to be able to use those directly as bucket indices. Instead, a common strategy is to make an array of buckets of some size m, compute the (full 32- or 64-bit) hash codes for your items, then mod them by the size of the table to get an index between 0 and m-1, inclusive. The use of modulus works well here because it's decently fast and does a decent job spreading the full range of hash codes across a smaller range.
(You sometimes see bitwise operators used here. If your table has a size that's a power of two, say, 2k, then computing the bitwise AND of the hash code and then umber 2k - 1 is equivalent to computing a modulus, and it's significantly faster.)
The next question is how to pick the right number of buckets. If you pick too many buckets, then most buckets will be empty or have few elements (good for speed - you only have to check a few items per bucket), but you'll use a bunch of space simply storing the buckets (not so great, though maybe you can afford it). The flip side of this holds true as well - if you have too few buckets, then you'll have more elements per bucket on average, making lookups take longer, but you'll use less memory.
A good compromise is to dynamically change the number of buckets over the lifetime of the hash table. The load factor of a hash table, typically denoted α, is the ratio of the number of elements to the number of buckets. Most hash tables pick some maximum load factor. Once the load factor crosses this limit, the hash table increases its number of slots (say, by doubling), then redistributes the elements from the old table into the new one. This is called rehashing. Assuming the maximum load factor in the table is a constant, this ensures that, assuming you have a good hash function, the expected cost of doing a lookup remains O(1). Insertions now have an amortized expected cost of O(1) because of the cost of periodically rebuilding the table, as is the case with deletions. (Deletions can similarly compact the table if the load factor gets too small.)
Hashing Strategies
Up to this point, we've been talking about chained hashing, which is one of many different strategies for building a hash table. As a reminder, chained hashing kinda sorta looks like a clothing dresser - each bucket (drawer) can hold multiple items, and when you do a lookup you check all of those items.
However, this isn't the only way to build a hash table. There's another family of hash tables that use a strategy called open addressing. The basic idea behind open addressing is to store an array of slots, where each slot can either be empty or hold exactly one item.
In open addressing, when you perform an insertion, as before, you jump to some slot whose index depends on the hash code computed. If that slot is free, great! You put the item there, and you're done. But what if the slot is already full? In that case, you use some secondary strategy to find a different free slot in which to store the item. The most common strategy for doing this uses an approach called linear probing. In linear probing, if the slot you want is already full, you simply shift to the next slot in the table. If that slot is empty, great! You can put the item there. But if that slot is full, you then move to the next slot in the table, etc. (If you hit the end of the table, just wrap back around to the beginning).
Linear probing is a surprisingly fast way to build a hash table. CPU caches are optimized for locality of reference, so memory lookups in adjacent memory locations tend to be much faster than memory lookups in scattered locations. Since a linear probing insertion or deletion works by hitting some array slot and then walking linearly forward, it results in few cache misses and ends up being a lot faster than what the theory normally predicts. (And it happens to be the case that the theory predicts it's going to be very fast!)
Another strategy that's become popular recently is cuckoo hashing. I like to think of cuckoo hashing as the "Frozen" of hash tables. Instead of having one hash table and one hash function, we have two hash tables and two hash functions. Each item can be in exactly one of two places - it's either in the location in the first table given by the first hash function, or it's in the location in the second table given by the second hash function. This means that lookups are worst-case efficient, since you only have to check two spots to see if something is in the table.
Insertions in cuckoo hashing use a different strategy than before. We start off by seeing if either of the two slots that could hold the item are free. If so, great! We just put the item there. But if that doesn't work, then we pick one of the slots, put the item there, and kick out the item that used to be there. That item has to go somewhere, so we try putting it in the other table at the appropriate slot. If that works, great! If not, we kick an item out of that table and try inserting it into the other table. This process continues until everything comes to rest, or we find ourselves trapped in a cycle. (That latter case is rare, and if it happens we have a bunch of options, like "put it in a secondary hash table" or "choose new hash functions and rebuild the tables.")
There are many improvements possible for cuckoo hashing, such as using multiple tables, letting each slot hold multiple items, and making a "stash" that holds items that can't fit anywhere else, and this is an active area of research!
Then there are hybrid approaches. Hopscotch hashing is a mix between open addressing and chained hashing that can be thought of as taking a chained hash table and storing each item in each bucket in a slot near where the item wants to go. This strategy plays well with multithreading. The Swiss table uses the fact that some processors can perform multiple operations in parallel with a single instruction to speed up a linear probing table. Extendible hashing is designed for databases and file systems and uses a mix of a trie and a chained hash table to dynamically increase bucket sizes as individual buckets get loaded. Robin Hood hashing is a variant of linear probing in which items can be moved after being inserted to reduce the variance in how far from home each element can live.
Further Reading
For more information about the basics of hash tables, check out these lecture slides on chained hashing and these follow-up slides on linear probing and Robin Hood hashing. You can learn more about cuckoo hashing here and about theoretical properties of hash functions here.