Boyer-Moore is probably the fastest non-indexed text-search algorithm known. So I'm implementing it in C# for my Black Belt Coder website.
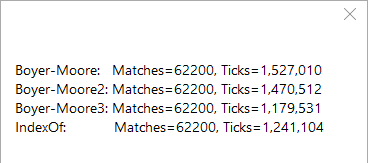
I had it working and it showed roughly the expected performance improvements compared to String.IndexOf(). However, when I added the StringComparison.Ordinal argument to IndexOf, it started outperforming my Boyer-Moore implementation. Sometimes, by a considerable amount.
I wonder if anyone can help me figure out why. I understand why StringComparision.Ordinal might speed things up, but how could it be faster than Boyer-Moore? Is it because of the the overhead of the .NET platform itself, perhaps because array indexes must be validated to ensure they're in range, or something else altogether. Are some algorithms just not practical in C#.NET?
Below is the key code.
// Base for search classes
abstract class SearchBase
{
public const int InvalidIndex = -1;
protected string _pattern;
public SearchBase(string pattern) { _pattern = pattern; }
public abstract int Search(string text, int startIndex);
public int Search(string text) { return Search(text, 0); }
}
/// <summary>
/// A simplified Boyer-Moore implementation.
///
/// Note: Uses a single skip array, which uses more memory than needed and
/// may not be large enough. Will be replaced with multi-stage table.
/// </summary>
class BoyerMoore2 : SearchBase
{
private byte[] _skipArray;
public BoyerMoore2(string pattern)
: base(pattern)
{
// TODO: To be replaced with multi-stage table
_skipArray = new byte[0x10000];
for (int i = 0; i < _skipArray.Length; i++)
_skipArray[i] = (byte)_pattern.Length;
for (int i = 0; i < _pattern.Length - 1; i++)
_skipArray[_pattern[i]] = (byte)(_pattern.Length - i - 1);
}
public override int Search(string text, int startIndex)
{
int i = startIndex;
// Loop while there's still room for search term
while (i <= (text.Length - _pattern.Length))
{
// Look if we have a match at this position
int j = _pattern.Length - 1;
while (j >= 0 && _pattern[j] == text[i + j])
j--;
if (j < 0)
{
// Match found
return i;
}
// Advance to next comparision
i += Math.Max(_skipArray[text[i + j]] - _pattern.Length + 1 + j, 1);
}
// No match found
return InvalidIndex;
}
}
EDIT: I've posted all my test code and conclusions on the matter at http://www.blackbeltcoder.com/Articles/algorithms/fast-text-search-with-boyer-moore.
IndexOf()using Boyer-Moore and talk about issues with Unicode (which I've already developed code to correctly handle). – KeshiakesiaStringComparison.Ordinalallows it to perform a direct comparision. – Keshiakesiachar*. Some internal string routines do that. – Bashful