What's different between UTF-8 and UTF-8 with BOM?
What's the difference between UTF-8 and UTF-8 with BOM?
Asked Answered
UTF-8 can be auto-detected better by contents than by BOM. The method is simple: try to read the file (or a string) as UTF-8 and if that succeeds, assume that the data is UTF-8. Otherwise assume that it is CP1252 (or some other 8 bit encoding). Any non-UTF-8 eight bit encoding will almost certainly contain sequences that are not permitted by UTF-8. Pure ASCII (7 bit) gets interpreted as UTF-8, but the result is correct that way too. –
Irremissible
Scanning large files for UTF-8 content takes time. A BOM makes this process much faster. In practice you often need to do both. The culprit nowadays is that still a lot of text content isn't Unicode, and I still bump into tools that say they do Unicode (for instance UTF-8) but emit their content a different codepage. –
Lisettelisha
@Irremissible I don't really think that "better" fits in this case. It depends on the environment. If you are sure that all UTF-8 files are marked with a BOM than checking the BOM is the "better" way, because it is faster and more reliable. –
Soler
UTF-8 does not have a BOM. When you put a U+FEFF code point at the start of a UTF-8 file, special care must be made to deal with it. This is just one of those Microsoft naming lies, like calling an encoding "Unicode" when there is no such thing. –
Massimo
@Irremissible There is no method which works all the time. Metadata can be wrong - it may say Latin1 but actually be UTF-8 or vice-versa. Data can be corrupted, or wrongly generated, so just because it is invalid UTF-8 doesn't mean it isn't best interpreted as "UTF-8 with a bit of corruption". Often that is what it will be. BOM helps distinguish between "corrupted/Invalid UTF-8" and "corrupted/invalid Latin1" –
Miliaria
You generally do not want this unless you have a specific need. It can be echoed into your HTML from a PHP fragment for instance. The modern Mainframe (and AIX) is little endian UTF-8 aware, even if this is not "native". So long as you standardise you should be OK. –
Jeddy
"The modern Mainframe (and AIX) is little endian UTF-8 aware" UTF-8 doesn't have an endedness! there is no shuffling of bytes around to put pairs or groups of four into the right "order" for a particular system! To detect a UTF-8 byte sequence it may be useful to note that the first byte of a multi-byte sequence "codepoint" (the bytes that are NOT "plain" ASCII ones) has the MS bit set and all one to three more successively less significant bits followed by a reset bit. The total number of those set bits is one less bytes that are in that codepoint and they will ALL have the MSB set... –
Ancient
There is no difference, as utf-8 has no BOM. Utf-8 + BOM is utf-8+ BOM, a not standard: used my microsoft, and maybe some others. –
Calcariferous
In case this helps anyone else, I've noticed that (for websites at least), in IIS on Windows servers, always save your files as UTF-8 with a BOM (and regular notepad does this when you select it in the Encoding drop down menu in the "Save As" dialog). But on Unix servers, I always save my files as UTF-8 without a BOM (because I had encoding issues when my apache server would read my PHP files if they had the BOM). Notepad++ has a great "Encoding" menu to help convert from one to the other. –
Anode
Reading this discussion about the (supposed) utility to add a BOM, I wonder: As most other codepages do not have or (supposedly) need a codepage identification, why UTF does? Why the only codepage(s) that must be changed is (are) UTF? Why not a BOM (or equivalent to detect encoding) for windows-1252 or DOS-852 or ISO 8859-1? That is a very unfair requirement. One that only Microsoft wants to impose. :-( –
Ferdinande
@Arrow "byte order" is for when you have two or more bytes representing a single character, and you need to know which way around they are so you can read them correctly. Windows-1252, ISO-8859-1, etc. are all single-byte encodings, there is only one byte per character, so there is no need for a Byte-Order-Mark to say which way to read them. They aren't intended to detect which encoding is in use; they are used for that because there is otherwise no automatic way to tell at all. But they aren't reliable for it. BOMs on multibyte encodings are not a Microsoft thing, only UTF8+BOM is. –
Eurasian
Fact 1: UTF-8 is a byte oriented encoding transmitted in network order, has no "byte order", needs no "byte order". Fact 2: windows use of UCS-2, quite similar to UTF-16, is a multi-byte encoding for which Microsoft specify no BOM. Get your facts right @Eurasian . –
Ferdinande
@Arrow "get my facts right"? What facts did I get wrong? Your facts don't contradict anything I said. –
Eurasian
You are the one introducing the "byte order" concept, not me (my initial comment does not address that). But UTF-8 needs no byte order detection or description. It is formed by a sequence of bytes. So, there is no need for a Byte-Order-Mark in UTF-8. ... For identification: UTF-8 being the most reliable encoding to correctly be detected (when UNICODE codepoints above 128 are used) needs no BOM. ... Again: Fact-1: UTF-8 needs no "byte order". Fact-2: Microsoft use a (supposedly) 2 byte encoding without BOM, Why is BOM needed in other encodings? @Eurasian –
Ferdinande
utf-8 is a byte stream so it really doesn't have a byte order but in this case, the 3-byte BOM acts as a signature anyway. Software should know if the encoding is ANSI or utf-8. In case utf-8 content is treated as ANSI encoding, the resulting characters will be wrong because bytes of sequences are treated as if they were single characters, whiich is wrong. On the other hand, if software treats ANSI encoded files as utf-8 there will be errors because of broken or incomplete sequences. –
Geomancer
@Arrow You are arguing against things I never said. Encodings which /need/ a BOM need it to /tell you the byte order/. Encodings which don't /need/ a BOM do not need it to tell you the byte order. UTF-8 has an optional BOM in the spec which can be abused to detect use of UTF-8. This is not "changing the standard", which is why it's different from classic codepages. It's not about detecting the byte order of UTF-8, and I never said that. YOU introduced byte order when you said "the (supposed) utility to add a BOM". Where do Microsoft use 2-byte/no BOM? DOTNet uses 2-byte+BOM for one example. –
Eurasian
At least there is a good point for bom : Apps like rar/zip makers don't waste time for scanning the whole files before packing them so packing the files without bom would most likely result in data lose. –
Alongside
The UTF-8 BOM is a sequence of bytes at the start of a text stream (0xEF, 0xBB, 0xBF) that allows the reader to more reliably guess a file as being encoded in UTF-8.
Normally, the BOM is used to signal the endianness of an encoding, but since endianness is irrelevant to UTF-8, the BOM is unnecessary.
According to the Unicode standard, the BOM for UTF-8 files is not recommended:
2.6 Encoding Schemes
... Use of a BOM is neither required nor recommended for UTF-8, but may be encountered in contexts where UTF-8 data is converted from other encoding forms that use a BOM or where the BOM is used as a UTF-8 signature. See the “Byte Order Mark” subsection in Section 16.8, Specials, for more information.
It might not be recommended but from my experience in Hebrew conversions the BOM is sometimes crucial for UTF-8 recognition in Excel, and may make the difference between Jibrish and Hebrew –
Alumroot
It might not be recommended but it did wonders to my powershell script when trying to output "æøå" –
Stumpage
Regardless of it not being recommended by the standard, it's allowed, and I greatly prefer having something to act as a UTF-8 signature rather the alternatives of assuming or guessing. Unicode-compliant software should/must be able to deal with its presence, so I personally encourage its use. –
Workable
@Workable there's another alternative to guessing and assuming: properly storing encoding metadata. UTF-8 BOM is a hacky attempt at this, but because this metadata is stored inside the main data stream it is actually equivalent to guessing. For example there's nothing that says my ISO 8859-1 encoded plain text file can't start with the characters "", which is indistinguishable from the UTF-8 BOM. A proper way to indicate plain text file encoding would be, for example, a file system attribute. –
Zermatt
@bames53: Yes, in an ideal world storing the encoding of text files as file system metadata would be a better way to preserve it. But most of us living in the real world can't change the file system of the OS(s) our programs get run on -- so using the Unicode standard's platform-independent BOM signature seems like the best and most practical alternative IMHO. –
Workable
@Workable NTFS supports arbitrary file attributes as do the file systems used with Linux and OS X. OS X in fact uses an extended attribute for text encoding and has a scheme for persisting such attributes even on file systems that don't natively support them, such as FAT32 and inside zip files. The BOM isn't so much a more practical solution as it is a dumb one (it's still just guessing, afterall) with viral properties that let it build up a lot of inertia. –
Zermatt
@bames53: Each OS has a different way to access and interpret the metadata and is a condition that can only be expected to continue and likely become worse in the future. Using the utf-8 BOM may technically be guessing, but in reality it's very unlikely to ever be wrong for a text file. Obviously our opinions differ on what "practical" means... –
Workable
@Workable Just yesterday I ran into a file with a UTF-8 BOM that wasn't UTF-8 (it was CP936). What's unfortunate is that the ones responsible for the immense amount of pain cause by the UTF-8 BOM are largely oblivious to it. –
Zermatt
@barnes53 - A file system attribute wouldn't apply to an HTTP request or response that begins with a BOM. (This situation is in fact what brought me to this question.) –
Capitate
When working in a Tomcat server and having UTF-8 French properties files with BOM, somehow the browser apends an interrogation sign "?" at the beginning of the file, this renders that specific property file useless in production environment and breaks the Javascript code. Our only workaround to date has been to save the UTF-8 file without BOM for the French javascript files. Strange behavior, shallow workaround. :( –
Endurable
@Endurable Looks like the web server is not sending the correct encoding. Look at your config. –
Miliaria
I'm not the final word here, but methinks you're interpreting standards-speak in its informal sense. For a standards body to recommend something, that means they formally make a normative indication of preferred usage. To not recommend something is to explicitly not provide an opinion on it. "Neither required nor recommended" does not mean that the Unicode standard recommends that you not use a UTF-8 signature for UTF-8 files---it simply means they are not taking a stand one way or the other. –
Thumbsdown
I've found some encoding detection libraries can only guess UTF-8 properly when a BOM is present. Otherwise, the heuristics seem to not be 100% accurate. –
Reduce
Also note that Windows seem to default to using a BOM for UTF-8, and a lot of Microsoft programs to not attempt heuristic detection, so if the BOM is missing it won't decode the file properly. –
Reduce
BOM should be considered compulsory, not recommending is one of the major failings of the Unicode standard, and probably the top reason why utf-8 is still problematic after all these years. –
Grizzly
@GarretWilson I agree with your interpretation that it simply means they are not taking a stand one way or the other. But that also means that including a BOM that solves no real problem is, at the very least, superfluous. And carry several unwanted ill consequences. At least this ones. –
Ferdinande
@Alumroot about Excel, this is a Microsoft product (Microsoft is also not recommended). Some times when doing something that is not recommended it becomes necessary to do something else that is not recommended. The paragraph in the standard that says that the BOM is sometimes encountered, was added as a response to Microsoft's use of the BOM. –
Calcariferous
@Workable Actually, in an ideal world every file should have a unique signature of a pre-defined byte length, including text files (one per encoding). That way heuristics wouldn't be necessary. Just like in the HTTP protocol with content types. –
Lesson
@EricGrange - Your comment makes me suspect that you have never experienced the many problems that a UTF-8 BOM can cause. It is very common to have output built up by concatenating strings; if those strings were encoded with a BOM, you now have a BOM in the middle of your output. And that's only the start of the issues. There is no need to specify byte order in UTF-8, and using the BOM as an encoding detector is problematic for other reasons. –
Klagenfurt
+rmunn the problem you describe is actually trivial to solve since the BOM is a special sequence with no other meaning, always having a BOM introduces no ambiguity as it can be safely detected. A stored string without BOM can on the other hand only be known to be UTF-8 through metadata and conventions. Both of which are fragile, filesystems notably fail on both, as the only metadata is typically the file extensions, which only loosely hints at content encoding. With compulsory BOM implementations could be made safe 100% of the time, without BOM, there is only guesswork and prayer... –
Grizzly
@EricGrange The UTF-8 BOM does have a somewhat severe problem, although that problem isn't actually caused by the BOM itself. Namely, since it's neither required nor recommended, there's a surprising amount of code that can handle UTF-8 without BOM, but chokes on the BOM itself. So, it's likely that they don't recommended it because of this known problem, but the problem is caused specifically by it not being recommended, effectively being a self-feeding cycle. –
Quay
(Another part of the reason is likely that while code still in active development can be updated to use the BOM if required, outdated ones typically cannot, which can cause problems in situations where they're necessary and can't be replaced.) –
Quay
Apart from that, it can theoretically cause false positives with files in other encoding schemes that unfortunately start with the UTF-8 BOM (such as an ISO-8859-1 file starting with
ABC), but that situation isn't too likely to come about outside of malice or poorly designed software. I personally think it makes detecting UTF-8 more efficient, though I'm honestly not very good at working with Unicode yet. –
Quay @bames53: Yes, the UTF-8 BOM may be misinterpreted as "real" characters . But the same is true for the UTF-16 BOM (big endian), which may be misinterpreted as "real" characters þÿ. To be consistent, one should either be in favor of BOMs in general, or against them in general. Given that we definitely cannot eliminate BOMs in UTF-16, we should also accept them in UTF-8. –
Petty
@MarcSigrist We don't need BOMs in UTF-16 either. The rules are that UTF-16BE or UTF-16LE aren't allowed to have a BOM. For UTF-16 the rule is that in the absence of a BOM endianness matches the medium storing the data (e.g. in memory on a little endian machine use little endian, over a network connection use the network byte order) and in the absence of such a higher level protocol then use big endian. This is discussed in 3.10 of the Unicode Standard. –
Zermatt
@GarretWilson I see other examples of 'It's not recommended' in the Unicode standard where it clearly means "we recommend that you do not..." For example see the last bullet point of P8 in 3.6. The comments on the UTF-8 BOM may not be as clear cut but some examples seem to lean more that way. E.g "[Use of a UTF-8 BOM is not] recommended by the Unicode Standard, but its presence does not affect conformance to the UTF-8 encoding scheme." This makes more sense as "we recommend against it, but it doesn't render the stream non-conformant." Otherwise the 'but' clause is silly and redundant. –
Zermatt
autohotkey.com/boards/… –
Stripy
Ha! Current unicode.org is currently offline. My natural human love of poetic justice wonders if it is due to a unicode error :-) –
Bourgeon
Yesterday i create few files for my webpages, and while viewing on web page their text were not in correct symbols (characters). today desperately i hit the "Add BOM" and then it was the only thing that worked. so it seem it is still required. :| –
Trahurn
Not only excel but even the rar/zip files because if the fast compression process –
Alongside
Another problem with BOM is when appending files. I'm used to being able go generate a new text file by, on file system level, appending one text file to another. This fails if using BOM. –
Pagination
The other excellent answers already answered that:
- There is no official difference between UTF-8 and BOM-ed UTF-8
- A BOM-ed UTF-8 string will start with the three following bytes.
EF BB BF - Those bytes, if present, must be ignored when extracting the string from the file/stream.
But, as additional information to this, the BOM for UTF-8 could be a good way to "smell" if a string was encoded in UTF-8... Or it could be a legitimate string in any other encoding...
For example, the data [EF BB BF 41 42 43] could either be:
- The legitimate ISO-8859-1 string "ABC"
- The legitimate UTF-8 string "ABC"
So while it can be cool to recognize the encoding of a file content by looking at the first bytes, you should not rely on this, as show by the example above
Encodings should be known, not divined.
sorry sir, but I don't quite understand the example you just gave. If I got a string [EF BB BF 41 42 43], how could I interpret it? Using ISO-8859-1 or UTF-8? Because just as your example said, both will give a legitimate string: "ABC" and "ABC". –
Hogue
@Hogue : You understood correctly. The string [EF BB BF 41 42 43] is just a bunch of bytes. You need external information to choose how to interpret it. If you believe those bytes were encoded using ISO-8859-1, then the string is "ABC". If you believe those bytes were encoded using UTF-8, then it is "ABC". If you don't know, then you must try to find out. The BOM could be a clue. The absence of invalid character when decoded as UTF-8 could be another... In the end, unless you can memorize/find the encoding somehow, an array of bytes is just an array of bytes. –
Obit
@Obit While "" is valid latin-1, it is very unlikely that a text file begins with that combination. The same holds for the ucs2-le/be markers ÿþ and þÿ. Also you can never know. –
Sulphathiazole
@user Indeed, it is very unlikely, but perfectly valid. You can't say it's not Latin-1 with 100% certainty. –
Outfielder
@Outfielder It is probably linguistically invalid: First ï (which is ok), then some quotation mark without space in-between (not ok). ¿ indicates it is Spanish but ï is not used in Spanish. Conclusion: It is not latin-1 with a certainty well above the certainty without it. –
Sulphathiazole
@user Sure, it doesn't necessarily make sense. But if your system relies on guessing, that's where uncertainties come in. Some malicious user submits text starting with these 3 letters on purpose, and your system suddenly assumes it's looking at UTF-8 with a BOM, treats the text as UTF-8 where it should use Latin-1, and some Unicode injection takes place. Just a hypothetical example, but certainly possible. You can't judge a text encoding by its content, period. –
Outfielder
@Outfielder Did I say that it is UTF-8? I only said what it is not. After I have guessed, I will validate data so it conforms to UTF-8 encoding rules (can be done while reading). If not and the text was stored along the way, fallback to another 8-bit encoding. If the text was not stored, reject the input. It is much like the checksum in found in a PNG. –
Sulphathiazole
@user No, you didn't. But I'm saying that if you look at the content of a string to determine its encoding, there's a possibility you'll get into weird situations. For example that your system may not be able to correctly accept a Latin-1 file that starts with the characters "". While it is arguably very unlikely this ever happens (I'm not contesting that), it's nonetheless a possibility. And I prefer to write correct code instead of code which may break if.... –
Outfielder
If it looks and smells like... UTF-8.. it's probably UTF-8. Why make your life more difficult thinking about convoluted edge cases? –
Welker
"Encodings should be known, not divined." The heart and soul of the problem. +1, good sir. In other words: either standardize your content and say, "We're always using this encoding. Period. Write it that way. Read it that way," or develop an extended format that allows for storing the encoding as metadata. (The latter probably needs some "bootstrap standard encoding," too. Like saying "The part that tells you the encoding is always ASCII.") –
Poussette
What if the text is some weird unicode characters which requires >1 bytes for a single code point, shouldn't now be BOM ? –
Runic
@RoyiNamir : The presence or absence of BOM doesn't affect use of legal unicode characters in UTF-8, weird or not. Could you clarify the question, please? –
Obit
@Obit Sure.This is the byte representation for "a". There is only one byte in utf-8 for "a" - so there is no need for BOM here. But what about this char? there are 4 bytes here. Shouldn't be any BOM here? I hope my question is clear now. –
Runic
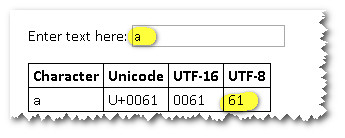{kind=link}
{kind=link}
@RoyiNamir : While the BOM can "help" the user to suspect a file is in Unicode instead of, say, ISO-8859-1, you can't be 100% sure of that. Let's say I send you a simple text file with the four bytes of your chinese (?) glyph, telling you it is UTF-8. Then, you can decode it without relying on the BOM. Other case, if I send you a ISO-8859-1 file with, as the first characters, the very same bytes of the BOM, then you still must decode it as ISO-8859-1. Not UTF-8. Only if I send you a text file without telling you its encoding, having the three bytes of the BOM will guide you. Or misguide you. –
Obit
"Encodings should be known, not divined." Tell that to wackos who use JSON :( ietf.org/rfc/rfc4627.txt –
Legation
@RoyiNamir - In the example you gave (i.imgur.com/7u1zLrS.png), there is still no need for a BOM in UTF-8, because its byte order is defined by the standard. Whether you're on a little-endian or big-endian system, the character 𠬠 (U+20B20) will always have just one valid UTF-8 encoding, the four-byte sequence
F0 A0 AC A0. The byte order of those bytes is strictly defined by the UTF-8 standard, so there is no need for any byte-order mark in UTF-8. (Its use as an encoding identifier is a different question; I'm specifically saying that it is not needed to identify byte order.) –
Klagenfurt Of a trillion text files, I doubt if a single (non-malicious) one started with the UTF-8 BOM that wasn't intended to be a UTF-8 BOM. And any maliciousness has to be handled anyway, BOM or no BOM. So, sanitize your input, and if there's a BOM maybe you can use that to speed your processing slightly. I don't see the problem. –
Appetency
@deceze: I've encountered text files that actually had no encoding. PHP is a nasty beast and you can indeed have an output ladder where different paths lead to different encodings being output and constants in both of them. –
Peignoir
@Peignoir There’s no such thing as a text file without an encoding. An indeterminable encoding maybe, but not no encoding. –
Outfielder
@deceze: Editing the output strings in the file required closing the editor, switching your session encoding, and opening the file again to do both sets. Half the strings would always look liker garbage. –
Peignoir
@Peignoir That short description is not sufficient to illuminate what’s going on there, but it surely sounds like the editor is mistreating encodings, not that the file has “no encoding”. –
Outfielder
Those bytes, if present, must be ignored Isn't the BOM also zero width non-breaking space (ZWNBS)? If so, shouldn't it be interpreted as that unicode character, and written out as that character in whatever encoding is correct? Ignored seems like the wrong term to use here. –
Piss "It is known." ~Irri and/or Jhiqui –
Holmic
@PaulDraper. JSON allows only five encodings. It also has a structured format, so that the first two bytes are necessarily ASCII. (This may not be true if you allow scalar JSON.) Taking these two rules together, it is perfectly possible to unambiguously determine the character set. –
Hypsometry
@TRiG, I don't disagree they can be divined. But it's rarely done correctly. AFAIK Python doesn't do JSON encoding detection. Heck, even Node.js and Browser JS (which if anyone should get it right, they should) don't do JSON encoding detection. You have to know the encoding and decode to text before invoking parsers. –
Legation
How I learned to stop worrying and love the BOM. –
Unwitting
There are at least three problems with putting a BOM in UTF-8 encoded files.
- Files that hold no text are no longer empty because they always contain the BOM.
- Files that hold text within the ASCII subset of UTF-8 are no longer themselves ASCII because the BOM is not ASCII, which makes some existing tools break down, and it can be impossible for users to replace such legacy tools.
- It is not possible to concatenate several files together because each file now has a BOM at the beginning.
And, as others have mentioned, it is neither sufficient nor necessary to have a BOM to detect that something is UTF-8:
- It is not sufficient because an arbitrary byte sequence can happen to start with the exact sequence that constitutes the BOM.
- It is not necessary because you can just read the bytes as if they were UTF-8; if that succeeds, it is, by definition, valid UTF-8.
@cheers-and-hth-alf I have now clarified the statement above; they are facts, no logic involved. –
Whorehouse
After the edit of points 1 and 2 these two points are no longer up-front self-contradictory. This is an improvement. I'll discuss each point in turn. –
Purulence
Re point 1 "Files that hold no text are no longer empty because they always contain the BOM", this (1) conflates the OS filesystem level with the interpreted contents level, plus it (2) incorrectly assumes that using BOM one must put a BOM also in every otherwise empty file. The practical solution to (1) is to not do (2). Essentially the complaint reduces to "it's possible to impractically put a BOM in an otherwise empty file, thus preventing the most easy detection of logically empty file (by checking file size)". Still good software should be able to deal with it, since it has a purpose. –
Purulence
Re point 2, "Files that hold ASCII text is no longer themselves ASCII", this conflates ASCII with UTF-8. An UTF-8 file that holds ASCII text is not ASCII, it's UTF-8. Similarly, an UTF-16 file that holds ASCII text is not ASCII, it's UTF-16. And so on. ASCII is a 7-bit single byte code. UTF-8 is an 8-bit variable length extension of ASCII. If "tools break down" due to >127 values then they're just not fit for an 8-bit world. One simple practical solution is to use only ASCII files with tools that break down for non-ASCII byte values. A probably better solution is to ditch those ungood tools. –
Purulence
Re point 3, "It is not possible to concatenate several files together because each file now has a BOM at the beginning" is just wrong. I have no problem concatenating UTF-8 files with BOM, so it's clearly possible. I think maybe you meant the Unix-land
cat won't give you a clean result, a result that has BOM only at the start. If you meant that, then that's because cat works at the byte level, not at the interpreted contents level, and in similar fashion cat can't deal with photographs, say. Still it doesn't do much harm. That's because the BOM encodes a zero-width non-breaking space. –
Purulence Re the final statement, "And as others have mentioned, it is neither sufficient nor necessary to have a BOM to detect that something is UTF-8." is wrong. In some situations it isn't necessary, but in other situations it is necessary. For example, the Visual C++ compiler requires a BOM at the start of a source code file in order to correctly identify its encoding as UTF-8. –
Purulence
@Cheersandhth.-Alf This answer is correct. You are merely pointing out Microsoft bugs. –
Massimo
Without BOM, it is not 100% sure that you can detect it as utf-8! Check if every Byte is < 128 and if not, check if it is a valid utf-8 sequence? Okay, that sounds good, but be aware that the first assumption might already be wrong. If the file is utf-16 encoded and you examine just the hi-byte and low-byte of a 16bit value, you might find values < 127 on the hi- and lo-bytes but the word might still be higher than 127! You can even find a startbyte and proper following byte but this could also be a 16 bit wide value of a character encoded in utf-16. –
Geomancer
@brighty: The situation isn't improved any by adding a bom though. –
Rajiv
Another problem with BOM... regexes don't recognize it as the beginning of the string or even the beginning of a line –
Cupulate
Statement 1 and 3 are (partially) wrong. The BOM is Unicode character
ZERO WIDTH NO-BREAK SPACE. A file which contains only a BOM is not empty, it contains one normal (but invisible) character. In a text file you can put as many ZERO WIDTH NO-BREAK SPACE characters as you like. However, the Byte Order Mark (BOM) FAQ says: in the middle of a file [...] U+FEFF should normally not occur. For backwards compatibility it should be treated as ZERO WIDTH NON-BREAKING SPACE (ZWNBSP), and is then part of the content of the file or string. –
Calorimeter @Massimo The answer may be somewhat correct, but your comment is plain wrong, technically. The treatment of BOM is simply not specific to any vendor. It sounds like that you assume C++'s polymorphic class as a POD (and the BOM is an analog implementation detail like a virtual pointer) and thus bitten by unexpected behavior. Then, it's certainly your bug, not C++'s. –
Aesthete
@Cheersandhth.-Alf "An UTF-8 file that holds ASCII text is not ASCII, it's UTF-8 ... UTF-8 is an 8-bit variable length extension of ASCII." Make up your mind? If UTF-8 is an 8-bit variable length extension of ASCII, then a UTF-8 file where every MSB is zero is ASCII, otherwise it wouldn't be an extension. –
Supersaturate
@WernfriedDomscheit - the use of U+FEFF as a ZERO WIDTH NO-BREAK SPACE is deprecated, and was already so in 2018 when you wrote your comment. U+2060 WORD JOINER is used for that purpose. Aside from this response to Wernfried, much of the debate in this comment thread is misplaced; ASCII is a character set comparable to Unicode being a character set — UTF-8 is an encoding, a method to store, transmit, or otherwise represent "something", where that something is in this case almost always Unicode characters.
U+FEFF is a character in the Unicode character set, it is not a UTF-8 thing –
Steverson Here are examples of the BOM usage that actually cause real problems and yet many people don't know about it.
BOM breaks scripts
Shell scripts, Perl scripts, Python scripts, Ruby scripts, Node.js scripts or any other executable that needs to be run by an interpreter - all start with a shebang line which looks like one of those:
#!/bin/sh
#!/usr/bin/python
#!/usr/local/bin/perl
#!/usr/bin/env node
It tells the system which interpreter needs to be run when invoking such a script. If the script is encoded in UTF-8, one may be tempted to include a BOM at the beginning. But actually the "#!" characters are not just characters. They are in fact a magic number that happens to be composed out of two ASCII characters. If you put something (like a BOM) before those characters, then the file will look like it had a different magic number and that can lead to problems.
See Wikipedia, article: Shebang, section: Magic number:
The shebang characters are represented by the same two bytes in extended ASCII encodings, including UTF-8, which is commonly used for scripts and other text files on current Unix-like systems. However, UTF-8 files may begin with the optional byte order mark (BOM); if the "exec" function specifically detects the bytes 0x23 and 0x21, then the presence of the BOM (0xEF 0xBB 0xBF) before the shebang will prevent the script interpreter from being executed. Some authorities recommend against using the byte order mark in POSIX (Unix-like) scripts,[14] for this reason and for wider interoperability and philosophical concerns. Additionally, a byte order mark is not necessary in UTF-8, as that encoding does not have endianness issues; it serves only to identify the encoding as UTF-8. [emphasis added]
BOM is illegal in JSON
Implementations MUST NOT add a byte order mark to the beginning of a JSON text.
BOM is redundant in JSON
Not only it is illegal in JSON, it is also not needed to determine the character encoding because there are more reliable ways to unambiguously determine both the character encoding and endianness used in any JSON stream (see this answer for details).
BOM breaks JSON parsers
Not only it is illegal in JSON and not needed, it actually breaks all software that determine the encoding using the method presented in RFC 4627:
Determining the encoding and endianness of JSON, examining the first four bytes for the NUL byte:
00 00 00 xx - UTF-32BE
00 xx 00 xx - UTF-16BE
xx 00 00 00 - UTF-32LE
xx 00 xx 00 - UTF-16LE
xx xx xx xx - UTF-8
Now, if the file starts with BOM it will look like this:
00 00 FE FF - UTF-32BE
FE FF 00 xx - UTF-16BE
FF FE 00 00 - UTF-32LE
FF FE xx 00 - UTF-16LE
EF BB BF xx - UTF-8
Note that:
- UTF-32BE doesn't start with three NULs, so it won't be recognized
- UTF-32LE the first byte is not followed by three NULs, so it won't be recognized
- UTF-16BE has only one NUL in the first four bytes, so it won't be recognized
- UTF-16LE has only one NUL in the first four bytes, so it won't be recognized
Depending on the implementation, all of those may be interpreted incorrectly as UTF-8 and then misinterpreted or rejected as invalid UTF-8, or not recognized at all.
Additionally, if the implementation tests for valid JSON as I recommend, it will reject even the input that is indeed encoded as UTF-8, because it doesn't start with an ASCII character < 128 as it should according to the RFC.
Other data formats
BOM in JSON is not needed, is illegal and breaks software that works correctly according to the RFC. It should be a nobrainer to just not use it then and yet, there are always people who insist on breaking JSON by using BOMs, comments, different quoting rules or different data types. Of course anyone is free to use things like BOMs or anything else if you need it - just don't call it JSON then.
For other data formats than JSON, take a look at how it really looks like. If the only encodings are UTF-* and the first character must be an ASCII character lower than 128 then you already have all the information needed to determine both the encoding and the endianness of your data. Adding BOMs even as an optional feature would only make it more complicated and error prone.
Other uses of BOM
As for the uses outside of JSON or scripts, I think there are already very good answers here. I wanted to add more detailed info specifically about scripting and serialization, because it is an example of BOM characters causing real problems.
rfc7159 which supersedes rfc4627 actually suggests supporting BOM may not be so evil. Basically not having a BOM is just an ambiguous kludge so that old Windows and Unix software that are not Unicode-aware can still process utf-8. –
Grizzly
Sounds like JSON needs updating in order to support it, same with Perl scripts, Python scripts, Ruby scripts, Node.js. Just because these platforms opted to not include support, doesn't necessarily kill the use for BOM. Apple has been trying to kill Adobe for a few years now, and Adobe is still around. But an enlightening post. –
Interfuse
@EricGrange, you seem to be very strongly supporting BOM, but fail to realize that this would render the all-ubiquitous, universally useful, optimal-minimum "plain text" format a relic of the pre-UTF8 past! Adding any sort of (in-band) header to the plain text stream would, by definition, impose a mandatory protocol to the simplest text files, making it never again the "simplest"! And for what gain? To support all the other, ancient CP encodings that also didn't have signatures, so you might mistake them with UTF-8? (BTW, ASCII is UTF-8, too. So, a BOM to those, too? ;) Come on.) –
Melvinmelvina
This answer is the reason why I came up to this question! I creat my bash scripts in Windows and experience a lot of problems when publishing those scripts to Linux! Same thing with jason files. –
Clap
Ideally, @Sz., in a world where all text formats have signatures, the signatures for non-plain-text formats would consist of
00 and >7F bytes only. This way, plain text could remain completely unchanged, as its signature would be "first non-zero byte is valid ASCII character". –
Quay (Note that this would break for some files that contain 8-bit extended ASCII variants but are treated as plain text anyways, especially ISO/IEC 8859 and Win-1252. I'm unsure how to prevent this without breaking the guarantee that any file containing only pure, unextended, 7-bit ASCII would be treated as plain text with no signature, apart from storing the signature as metadata instead (which introduces a different sort of complexity).) –
Quay
I wish I could vote this answer up about fifty times. I also want to add that at this point, UTF-8 has won the standards war, and nearly all text being produced on the Internet is UTF-8. Some of the most popular programming languages (such as C# and Java) use UTF-16 internally, but when programmers using those languages write files to output streams, they almost always encode them as UTF-8. Therefore, it no longer makes sense to have a BOM to mark a UTF-8 file; UTF-8 should be the default you use when reading, and only try other encodings if UTF-8 decoding fails. –
Klagenfurt
@Sz those legacy optimal-minimum utilities really are relics: they will happily savage utf-8 encoding and cut in the middle of codepoints. They can only be used if your "utf-8 files" are plain English (ie. ASCII), otherwise they are text-corruption in waiting. –
Grizzly
@Klagenfurt not really, popular environments like Eclipse still regularly fail/corrupt accented characters in Java files when the source file does not have a BOM... –
Grizzly
@EricGrange - Really? A quick Google search suggests the opposite to me: stackoverflow.com/questions/2905582/… is about how a UTF-8 BOM is showing up as a character in Eclipse (i.e., Eclipse thinks there shouldn't be a BOM there and doesn't know what to do with it), and dzone.com/articles/what-does-utf-8-bom-mean says "In Eclipse, if we set default encoding with UTF-8, it would use normal UTF-8 without the Byte Order Mark (BOM)". Got any links to places where people are discussing Eclipse failing when a UTF-8 BOM is omitted? –
Klagenfurt
This is from experience, we have Java files edited both locally (France) and by a contractor in Tunisia, synch'ed with git, with french comments. Files without BOM regularly end up with savaged accented characters. We now have a script that is launched regularly to fix the encoding and prefix with BOM newer files, then recommit where required (outside Eclipse, previously the files were fixed manually with Notepad++). The files then usually have no further issues. I have not investigated exactly which part of the toolchain was at fault, maybe Eclipse is just the canary in the coal mine. –
Grizzly
@EricGrange - If you ever do decide to chase down the fault in the toolchain, I suspect
git blame will prove highly useful in identifying who introduced a commit with garbled characters, at which point you can email them and ask them what tool they routinely use, and to check that tool's settings. It should be defaulting to UTF-8, not "Latin-1" or a different single-byte codepage. There is no excuse for any tool not to default to reading UTF-8 first (in the absence of a BOM, that is), then trying other codepages if a text file doesn't decode correctly as UTF-8. Hope this helps! –
Klagenfurt @EricGrange, your answer, if you really studied it, is a bit disingenuous. You didn't include a link for rfc7159. Had you done so, people could have read: "Implementations MUST NOT add a byte order mark to the beginning of a JSON text. In the interests of interoperability, implementations that parse JSON texts MAY ignore the presence of a byte order mark rather than treating it as an error." That doesn't "[suggest] supporting BOM may not be so evil", it suggests that wise coders not make their programs break due to the Microsoft-created UTF8-with-BOM. –
Rambling
What's different between UTF-8 and UTF-8 without BOM?
Short answer: In UTF-8, a BOM is encoded as the bytes EF BB BF at the beginning of the file.
Long answer:
Originally, it was expected that Unicode would be encoded in UTF-16/UCS-2. The BOM was designed for this encoding form. When you have 2-byte code units, it's necessary to indicate which order those two bytes are in, and a common convention for doing this is to include the character U+FEFF as a "Byte Order Mark" at the beginning of the data. The character U+FFFE is permanently unassigned so that its presence can be used to detect the wrong byte order.
UTF-8 has the same byte order regardless of platform endianness, so a byte order mark isn't needed. However, it may occur (as the byte sequence EF BB FF) in data that was converted to UTF-8 from UTF-16, or as a "signature" to indicate that the data is UTF-8.
Which is better?
Without. As Martin Cote answered, the Unicode standard does not recommend it. It causes problems with non-BOM-aware software.
A better way to detect whether a file is UTF-8 is to perform a validity check. UTF-8 has strict rules about what byte sequences are valid, so the probability of a false positive is negligible. If a byte sequence looks like UTF-8, it probably is.
this would also invalidate valid UTF-8 with a single erroneous byte in it, though :/ –
Terreverte
-1 re " It causes problems with non-BOM-aware software.", that's never been a problem for me, but on the contrary, that absence of BOM causes problems with BOM-aware software (in particular Visual C++) has been a problem. So this statement is very platform-specific, a narrow Unix-land point of view, but is misleadingly presented as if it applies in general. Which it does not. –
Purulence
No, UTF-8 has no BOM. This answer is incorrect. See the Unicode Standard. –
Massimo
You can even think you have a pure ASCII file when just looking at the bytes. But this could be a utf-16 file as well where you'd have to look at words and not at bytes. Modern sofware should be aware about BOMs. Still reading utf-8 can fail if detecting invalid sequences, codepoints that can use a smaller sequence or codepoints that are surrogates. For utf-16 reading might fail too when there are orphaned surrogates. –
Geomancer
Wasn't UTF-8 made specifically for unix systems? Having a BOM in UTF-8 is a bastardization of the format. It was specifically made to not break stuff by introducing invisible characters. And if other platforms have issues, there's always UTF-16 –
Selfaddressed
@Alf, I disagree with your interpretation of a non-BOM attitude as "platform-specific, a narrow Unix-land point of view." To me, the only way that the narrow-mindedness could lie with "Unix land" were if MS and Visual C++ came before *NIX, which they didn't. The fact that MS (I assume knowingly) started using a BOM in UTF-8 rather than UTF-16 suggests to me that they promoted breaking
sh, perl, g++, and many other free and powerful tools. Want things to work? Just buy the MS versions. MS created the platform-specific problem, just like the disaster of their \x80-\x95 range. –
Rambling @Rambling What a narrow Unix-land paranoid point of view, assuming Microsoft's motivation was to break open-source tools rather than to distinguish between latin-1 and other encodings that were more common than Unicode at the time. Considering how many people here are advocating the use of a BOM with UTF8 even when they're not working in a Microsoft environment, it's easy to see why Microsoft thought it would be a good idea without resorting to paranoia. –
Blackpoll
Sincere thanks, @Darryl. I wrote with emotion when using, "(I assume knowingly)". Having read your post, I would rewrite my original comment without the parenthetical - you've shown its logical unsoundness. I am curious as to "how many people here are advocating the use of a BOM with UTF8". We've 0 advocates in the top 5 on 2023-11-07 (see WayBack). Using votes on answers only: 56 advocate, 1664 oppose (could argue down to 998 w/ repeats), 37 agnostic. I would be sincerely interested to see high quality arguments for the BOM that don't involve CSV files, where Excel seems to be the problem. –
Rambling
I'm among those that (strongly) prefer NOT to have a BOM in UTF-8. When I glanced through comments when I first ran across this topic I saw more arguments FOR the BOM than I expected to see. I didn't count or calculate ratios, I just came away with the informal impression that more people like including it than I would have expected. –
Blackpoll
UTF-8 with BOM is better identified. I have reached this conclusion the hard way. I am working on a project where one of the results is a CSV file, including Unicode characters.
If the CSV file is saved without a BOM, Excel thinks it's ANSI and shows gibberish. Once you add "EF BB BF" at the front (for example, by re-saving it using Notepad with UTF-8; or Notepad++ with UTF-8 with BOM), Excel opens it fine.
Prepending the BOM character to Unicode text files is recommended by RFC 3629: "UTF-8, a transformation format of ISO 10646", November 2003 at https://www.rfc-editor.org/rfc/rfc3629 (this last info found at: http://www.herongyang.com/Unicode/Notepad-Byte-Order-Mark-BOM-FEFF-EFBBBF.html)
Thanks for this excellent tip in case one is creating UTF-8 files for use by Excel. In other circumstances though, I would still follow the other answers and skip the BOM. –
Wordage
It's also useful if you create files that contain only ASCII and later may have non-ascii added to it. I have just ran into such an issue: software that expects utf8, creates file with some data for user editing. If the initial file contains only ASCII, is opened in some editors and then saved, it ends up in latin-1 and everything breaks. If I add the BOM, it will get detected as UTF8 by the editor and everything works. –
Pick
I have found multiple programming related tools which require the BOM to properly recognise UTF-8 files correctly. Visual Studio, SSMS, SoureTree.... –
Welker
Where do you read a recommendation for using a BOM into that RFC? At most, there's a strong recommendation to not forbid it under certain circumstances where doing so is difficult. –
Rajiv
Excel thinks it's ANSI and shows gibberish then the problem is in Excel. –
Ferdinande
The RFC 3629 say that it is useless:
UTF-8 having a single-octet encoding unit, this last function is useless and the BOM will always appear as the octet sequence EF BB BF. –
Ferdinande LibreOffice Calc has no problem importing UTF without BOM, tab-delimited CSV files. It simply treats it as ASCII. –
Rikki
A particularly amusing problem, too, @sorontar. Notepad (and by extension, Windows' built-in text controls) can detect UTF-8 without signature/BOM, provided the presence of valid, non-ASCII, UTF-8 characters. This has amusing implications when one considers the number of Windows tools that can't do this. –
Quay
Question: What's different between UTF-8 and UTF-8 without a BOM? Which is better?
Here are some excerpts from the Wikipedia article on the byte order mark (BOM) that I believe offer a solid answer to this question.
On the meaning of the BOM and UTF-8:
The Unicode Standard permits the BOM in UTF-8, but does not require or recommend its use. Byte order has no meaning in UTF-8, so its only use in UTF-8 is to signal at the start that the text stream is encoded in UTF-8.
Argument for NOT using a BOM:
The primary motivation for not using a BOM is backwards-compatibility with software that is not Unicode-aware... Another motivation for not using a BOM is to encourage UTF-8 as the "default" encoding.
Argument FOR using a BOM:
The argument for using a BOM is that without it, heuristic analysis is required to determine what character encoding a file is using. Historically such analysis, to distinguish various 8-bit encodings, is complicated, error-prone, and sometimes slow. A number of libraries are available to ease the task, such as Mozilla Universal Charset Detector and International Components for Unicode.
Programmers mistakenly assume that detection of UTF-8 is equally difficult (it is not because of the vast majority of byte sequences are invalid UTF-8, while the encodings these libraries are trying to distinguish allow all possible byte sequences). Therefore not all Unicode-aware programs perform such an analysis and instead rely on the BOM.
In particular, Microsoft compilers and interpreters, and many pieces of software on Microsoft Windows such as Notepad will not correctly read UTF-8 text unless it has only ASCII characters or it starts with the BOM, and will add a BOM to the start when saving text as UTF-8. Google Docs will add a BOM when a Microsoft Word document is downloaded as a plain text file.
On which is better, WITH or WITHOUT the BOM:
The IETF recommends that if a protocol either (a) always uses UTF-8, or (b) has some other way to indicate what encoding is being used, then it “SHOULD forbid use of U+FEFF as a signature.”
My Conclusion:
Use the BOM only if compatibility with a software application is absolutely essential.
Also note that while the referenced Wikipedia article indicates that many Microsoft applications rely on the BOM to correctly detect UTF-8, this is not the case for all Microsoft applications. For example, as pointed out by @barlop, when using the Windows Command Prompt with UTF-8†, commands such type and more do not expect the BOM to be present. If the BOM is present, it can be problematic as it is for other applications.
† The chcp command offers support for UTF-8 (without the BOM) via code page 65001.
I'd better to strict to WITHOUT the BOM. I found that
.htaccess and gzip compression in combination with UTF-8 BOM gives an encoding error Change to Encoding in UTF-8 without BOM follow to a suggestion as explained here solve the problems –
Epinasty 'Another motivation for not using a BOM is to encourage UTF-8 as the "default" encoding.' -- Which is so strong & valid an argument, that you could have actually stopped the answer there!... ;-o Unless you got a better idea for universal text representation, that is. ;) (I don't know how old you are, how many years you had to suffer in the pre-UTF8 era (when linguists desperately considered even changing their alphabets), but I can tell you that every second we get closer to ridding the mess of all the ancient single-byte-with-no-metadata encodings, instead of having "the one" is pure joy.) –
Melvinmelvina
See also this comment about how adding a BOM (or anything!) to the simplest of the text file formats, "plain text", would mean preventing exactly the best universal text encoding format from being "plain", and "simple" (i.e. "overheadless")!... –
Melvinmelvina
BOM is mostly problematic on Linux because many utilities do not really support Unicode to begin with (they will happily truncate in the middle of codepoints for instance). For most other modern software environment, use BOM whenever the encoding is not unambiguous (through specs or metadata). –
Grizzly
This question already has a million-and-one answers and many of them are quite good, but I wanted to try and clarify when a BOM should or should not be used.
As mentioned, any use of the UTF BOM (Byte Order Mark) in determining whether a string is UTF-8 or not is educated guesswork. If there is proper metadata available (like charset="utf-8"), then you already know what you're supposed to be using, but otherwise you'll need to test and make some assumptions. This involves checking whether the file a string comes from begins with the hexadecimal byte code, EF BB BF.
If a byte code corresponding to the UTF-8 BOM is found, the probability is high enough to assume it's UTF-8 and you can go from there. When forced to make this guess, however, additional error checking while reading would still be a good idea in case something comes up garbled. You should only assume a BOM is not UTF-8 (i.e. latin-1 or ANSI) if the input definitely shouldn't be UTF-8 based on its source. If there is no BOM, however, you can simply determine whether it's supposed to be UTF-8 by validating against the encoding.
Why is a BOM not recommended?
- Non-Unicode-aware or poorly compliant software may assume it's latin-1 or ANSI and won't strip the BOM from the string, which can obviously cause issues.
- It's not really needed (just check if the contents are compliant and always use UTF-8 as the fallback when no compliant encoding can be found)
When should you encode with a BOM?
If you're unable to record the metadata in any other way (through a charset tag or file system meta), and the programs being used like BOMs, you should encode with a BOM. This is especially true on Windows where anything without a BOM is generally assumed to be using a legacy code page. The BOM tells programs like Office that, yes, the text in this file is Unicode; here's the encoding used.
When it comes down to it, the only files I ever really have problems with are CSV. Depending on the program, it either must, or must not have a BOM. For example, if you're using Excel 2007+ on Windows, it must be encoded with a BOM if you want to open it smoothly and not have to resort to importing the data.
The last section of your answer is 100% correct: the only reason to use a BOM is when you have to interoperate with buggy software that doesn't use UTF-8 as its default to parse unknown files. –
Klagenfurt
BOM tends to boom (no pun intended (sic)) somewhere, someplace. And when it booms (for example, doesn't get recognized by browsers, editors, etc.), it shows up as the weird characters  at the start of the document (for example, HTML file, JSON response, RSS, etc.) and causes the kind of embarrassments like the recent encoding issue experienced during the talk of Obama on Twitter.
It's very annoying when it shows up at places hard to debug or when testing is neglected. So it's best to avoid it unless you must use it.
Yes, just spent hours identifying a problem caused by a file being encoded as UTF-8 instead of UTF-8 without BOM. (The issue only showed up in IE7 so that led me on a quite a goose chase. I used Django's "include".) –
Goldcrest
Future readers: Note that the tweet issue I've mentioned above was not strictly related to BOM, but if it was, then the tweet would be garbled in a similar way, but at the start of the tweet. –
Waly
@Goldcrest No, the problem is that Microsoft has mislead you. What it calls UTF-8 is not UTF-8. What it calls UTF-8 without BOM is what UTF-8 really is. –
Massimo
what does the "sic" add to your "no pun intended" –
Cupulate
@Cupulate I can't recall anymore but I guess the pun might have been intended despite the author's claim :) –
Waly
UTF-8 without BOM has no BOM, which doesn't make it any better than UTF-8 with BOM, except when the consumer of the file needs to know (or would benefit from knowing) whether the file is UTF-8-encoded or not.
The BOM is usually useful to determine the endianness of the encoding, which is not required for most use cases.
Also, the BOM can be unnecessary noise/pain for those consumers that don't know or care about it, and can result in user confusion.
"which has no use for UTF-8 as it is 8-bits per glyph anyway." Er... no, only ASCII-7 glyphs are 8-bits in UTF-8. Anything beyond that is going to be 16, 24, or 32 bits. –
Stefaniestefano
"The BOM is usually useful to determine the endianness of the encoding, which is not required for most use cases."... endianness simply does not apply to UTF-8, regardless of use case –
Cupulate
a consumer that needs to know is broken by design,. –
Needleful
It should be noted that for some files you must not have the BOM even on Windows. Examples are SQL*plus or VBScript files. In case such files contains a BOM you get an error when you try to execute them.
Quoted at the bottom of the Wikipedia page on BOM: http://en.wikipedia.org/wiki/Byte-order_mark#cite_note-2
"Use of a BOM is neither required nor recommended for UTF-8, but may be encountered in contexts where UTF-8 data is converted from other encoding forms that use a BOM or where the BOM is used as a UTF-8 signature"
Do you have any example where software makes a decision of whether to use UTF-8 with/without BOM, based on whether the previous encoding it is encoding from, had a BOM or not?! That seems like an absurd claim –
Defamation
UTF-8 with BOM only helps if the file actually contains some non-ASCII characters. If it is included and there aren't any, then it will possibly break older applications that would have otherwise interpreted the file as plain ASCII. These applications will definitely fail when they come across a non ASCII character, so in my opinion the BOM should only be added when the file can, and should, no longer be interpreted as plain ASCII.
I want to make it clear that I prefer to not have the BOM at all. Add it in if some old rubbish breaks without it, and replacing that legacy application is not feasible.
Don't make anything expect a BOM for UTF-8.
it's not certain that non UTF8-aware applications will fail if they encounter UTF8, the whole point of UTF8 is that many things will just work
wc(1) will give a correct line and octet count, and a correct word count if no unicode-only spacing characters are used. –
Needleful I agree with you @Jasen. Trying to workout if I just delete this old answer. My current opinion is that the answer is simply don't add a BOM. The end user can append one if they have to hack a file to make it work with old software. We shouldn't make software that perpetuates this incorrect behaviour. There is no reason why a file couldn't start with a zero-width-non-joiner that is meant to be interpreted as one. –
Carpenter
I look at this from a different perspective. I think UTF-8 with BOM is better as it provides more information about the file. I use UTF-8 without BOM only if I face problems.
I am using multiple languages (even Cyrillic) on my pages for a long time and when the files are saved without BOM and I re-open them for editing with an editor (as cherouvim also noted), some characters are corrupted.
Note that Windows' classic Notepad automatically saves files with a BOM when you try to save a newly created file with UTF-8 encoding.
I personally save server side scripting files (.asp, .ini, .aspx) with BOM and .html files without BOM.
Thanks for the excellent tip about windows classic Notepad. I already spent some time finding out the exact same thing. My consequence was to always use Notepad++ instead of windows classic Notepad. :-) –
Wordage
You better use madedit. It's the only Editor that - in hex mode - shows one character if you select a utf-8 byte sequence instead of a 1:1 Basis between byte and character. A hex-Editor that is aware about a UTF-8 file should bevave like madedit does! –
Geomancer
@Geomancer I don't think you need one to one for the sake of the BOM. it doesn't matter, it doesn't take much to recognise a utf-8 BOM is efbbbf or fffe (of fffe if read wrong). One can simply delete those bytes. It's not bad though to have a mapping for the rest of the file though, but to also be able to delete byte by byte too –
Defamation
@Defamation Why would you want to delete a utf-8 BOM if the file's content is utf-8 encoded? The BOM is recognized by modern Text Viewers, Text Controls as well as Text Editors. A one to one view of a utf-8 sequence makes no sense, since n bytes result in one character. Of course a text-editor or hex-editor should allow to delete any byte, but this can lead to invalid utf-8 sequences. –
Geomancer
@Geomancer utf-8 with bom is an encoding, and utf-8 without bom is an encoding. The cmd prompt uses utf8 without bom.. so if you have a utf8 file, you run the command
chcp 65001 for utf8 support, it's utf8 without bom. If you do type myfile it will only display properly if there is no bom. If you do echo aaa>a.a or echo אאא>a.a to output the chars to file a.a, and you have chcp 65001, it will output with no BOM. –
Defamation When you want to display information encoded in UTF-8 you may not face problems. Declare for example an HTML document as UTF-8 and you will have everything displayed in your browser that is contained in the body of the document.
But this is not the case when we have text, CSV and XML files, either on Windows or Linux.
For example, a text file in Windows or Linux, one of the easiest things imaginable, it is not (usually) UTF-8.
Save it as XML and declare it as UTF-8:
<?xml version="1.0" encoding="UTF-8"?>
It will not display (it will not be be read) correctly, even if it's declared as UTF-8.
I had a string of data containing French letters, that needed to be saved as XML for syndication. Without creating a UTF-8 file from the very beginning (changing options in IDE and "Create New File") or adding the BOM at the beginning of the file
$file="\xEF\xBB\xBF".$string;
I was not able to save the French letters in an XML file.
I know this is an old answer, but I just want to mention that it's wrong. Text files on Linux (can't speak for other Unixes) usually /are/ UTF-8. –
Wares
Is this answer for or against the UTF-8 BOM? I think it is for, but I can't be sure. –
Rambling
One practical difference is that if you write a shell script for Mac OS X and save it as plain UTF-8, you will get the response:
#!/bin/bash: No such file or directory
in response to the shebang line specifying which shell you wish to use:
#!/bin/bash
If you save as UTF-8, no BOM (say in BBEdit) all will be well.
That’s because Microsoft has swapped the meaning of what the standard says. UTF-8 has no BOM: they have created Microsoft UTF-8 which inserts a spurious BOM in front of the data stream and then told you that no, this is actually UTF-8. It is not. It is just extending and corrupting. –
Massimo
The Unicode Byte Order Mark (BOM) FAQ provides a concise answer:
Q: How I should deal with BOMs?
A: Here are some guidelines to follow:
A particular protocol (e.g. Microsoft conventions for .txt files) may require use of the BOM on certain Unicode data streams, such as files. When you need to conform to such a protocol, use a BOM.
Some protocols allow optional BOMs in the case of untagged text. In those cases,
Where a text data stream is known to be plain text, but of unknown encoding, BOM can be used as a signature. If there is no BOM, the encoding could be anything.
Where a text data stream is known to be plain Unicode text (but not which endian), then BOM can be used as a signature. If there is no BOM, the text should be interpreted as big-endian.
Some byte oriented protocols expect ASCII characters at the beginning of a file. If UTF-8 is used with these protocols, use of the BOM as encoding form signature should be avoided.
Where the precise type of the data stream is known (e.g. Unicode big-endian or Unicode little-endian), the BOM should not be used. In particular, whenever a data stream is declared to be UTF-16BE, UTF-16LE, UTF-32BE or UTF-32LE a BOM must not be used.
From http://en.wikipedia.org/wiki/Byte-order_mark:
The byte order mark (BOM) is a Unicode character used to signal the endianness (byte order) of a text file or stream. Its code point is U+FEFF. BOM use is optional, and, if used, should appear at the start of the text stream. Beyond its specific use as a byte-order indicator, the BOM character may also indicate which of the several Unicode representations the text is encoded in.
Always using a BOM in your file will ensure that it always opens correctly in an editor which supports UTF-8 and BOM.
My real problem with the absence of BOM is the following. Suppose we've got a file which contains:
abc
Without BOM this opens as ANSI in most editors. So another user of this file opens it and appends some native characters, for example:
abg-αβγ
Oops... Now the file is still in ANSI and guess what, "αβγ" does not occupy 6 bytes, but 3. This is not UTF-8 and this causes other problems later on in the development chain.
An ensure that spurious bytes appear in the beginning of non BOM-aware software. Yay. –
Bretbretagne
@Bretbretagne Muller: e.g. PHP 5 will throw "impossible" errors when you try to send headers after the BOM. –
Inunction
αβγ is not ascii, but can appear in 8bit-ascii-bassed encodings. The use of a BOM disables a benafit of utf-8, its compatability with ascii (ability to work with lagacy applications where pure ascii is used). –
Calcariferous
This is the wrong answer. A string with a BOM in front of it is something else altogether. It is not supposed to be there and just screws everything up. –
Massimo
Without BOM this opens as ANSI in most editors. I agree absolutely. If this happens you're lucky if you deal with the correct Codepage but indeed it's just a guess, because the Codepage is not part of the file. A BOM is. –
Geomancer
All the editors i use open text files as UTF8, which is according to my localisation settings. broken sofrware is not an excuse for broken behaviour. –
Needleful
As mentioned above, UTF-8 with BOM may cause problems with non-BOM-aware (or compatible) software. I once edited HTML files encoded as UTF-8 + BOM with the Mozilla-based KompoZer, as a client required that WYSIWYG program.
Invariably the layout would get destroyed when saving. It took my some time to fiddle my way around this. These files then worked well in Firefox, but showed a CSS quirk in Internet Explorer destroying the layout, again. After fiddling with the linked CSS files for hours to no avail I discovered that Internet Explorer didn't like the BOMfed HTML file. Never again.
Also, I just found this in Wikipedia:
The shebang characters are represented by the same two bytes in extended ASCII encodings, including UTF-8, which is commonly used for scripts and other text files on current Unix-like systems. However, UTF-8 files may begin with the optional byte order mark (BOM); if the "exec" function specifically detects the bytes 0x23 0x21, then the presence of the BOM (0xEF 0xBB 0xBF) before the shebang will prevent the script interpreter from being executed. Some authorities recommend against using the byte order mark in POSIX (Unix-like) scripts,[15] for this reason and for wider interoperability and philosophical concerns
Here is my experience with Visual Studio, Sourcetree and Bitbucket pull requests, which has been giving me some problems:
So it turns out BOM with a signature will include a red dot character on each file when reviewing a pull request (it can be quite annoying).
If you hover on it, it will show a character like "ufeff", but it turns out Sourcetree does not show these types of bytemarks, so it will most likely end up in your pull requests, which should be ok because that's how Visual Studio 2017 encodes new files now, so maybe Bitbucket should ignore this or make it show in another way, more info here:
I save a autohotkey file with utf-8, the chinese characters become strang.
With utf-8 BOM, works fine.
AutoHotkey will not automatically recognize a UTF-8 file unless it begins with a byte order mark.
UTF with a BOM is better if you use UTF-8 in HTML files and if you use Serbian Cyrillic, Serbian Latin, German, Hungarian or some exotic language on the same page.
That is my opinion (30 years of computing and IT industry).
I find this to be true as well. If you use characters outside of the first 255 ASCII set and you omit the BOM, browsers interpret it as ISO-8859-1 and you get garbled characters. Given the answers above, this is apparently on the browser-vendors doing the wrong thing when they don't detect a BOM. But unless you work at Microsoft Edge/Mozilla/Webkit/Blink, you have no choice but work with the defects these apps have. –
Ultrared
UTF what? UTF-8? UTF-16? Something else? –
Twin
If your server does nt indocate the correct mime type charset parameter you should use the
<meta http-equiv tag in your HTML header. –
Needleful © 2022 - 2024 — McMap. All rights reserved.