The previous answers are really great, I would like to point out a few more additions:
Object Segmentation
one of the reasons that this has fallen out of favor in the research community is because it is problematically vague. Object segmentation used to simply mean finding a single or small number of objects in an image and draw a boundary around them, and for most purposes you can still assume it means this. However, it also began to be used to mean segmentation of blobs that might be objects, segmentation of objects from the background (more commonly now called background subtraction or background segmentation or foreground detection), and even in some cases used interchangeably with object recognition using bounding boxes (this quickly stopped with the advent of deep neural network approaches to object recognition, but beforehand object recognition could also mean simply labeling an entire image with the object in it).
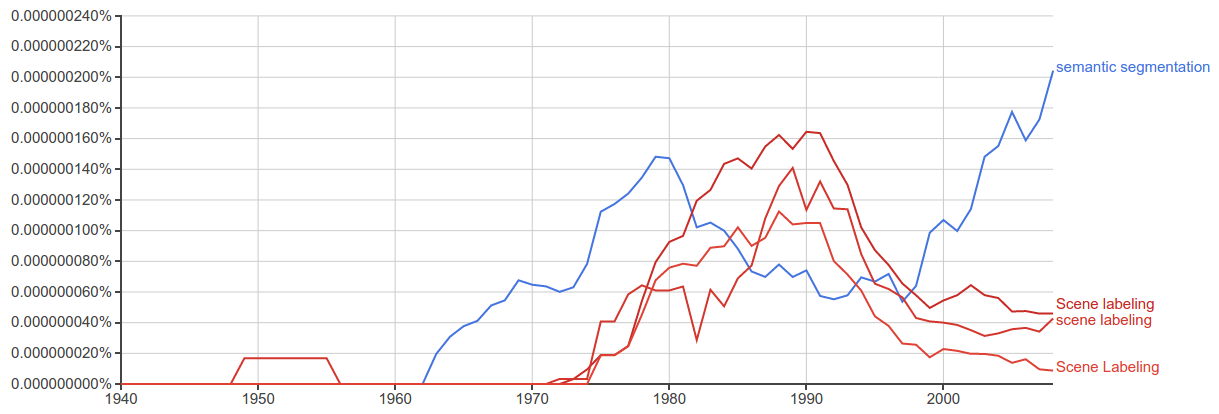
What makes "segmentation" "semantic"?
Simpy, each segment, or in the case of deep methods each pixel, is given a class label based on a category. Segmentation in general is just the division of the image by some rule. Meanshift segmentation, for example, from a very high level divide the data according to the changes in the energy of the image. Graph cut based segmentation is similarly not learned but directly derived from the properties of each image separate from the rest. More recent (neural network based) methods use pixels that are labeled to learn to identify the local features which are associated with specific classes, and then classify each pixel based on which class has the highest confidence for that pixel. In this way, "pixel-labeling" is actually more honest name for the task, and the "segmentation" component is emergent.
Instance Segmentation
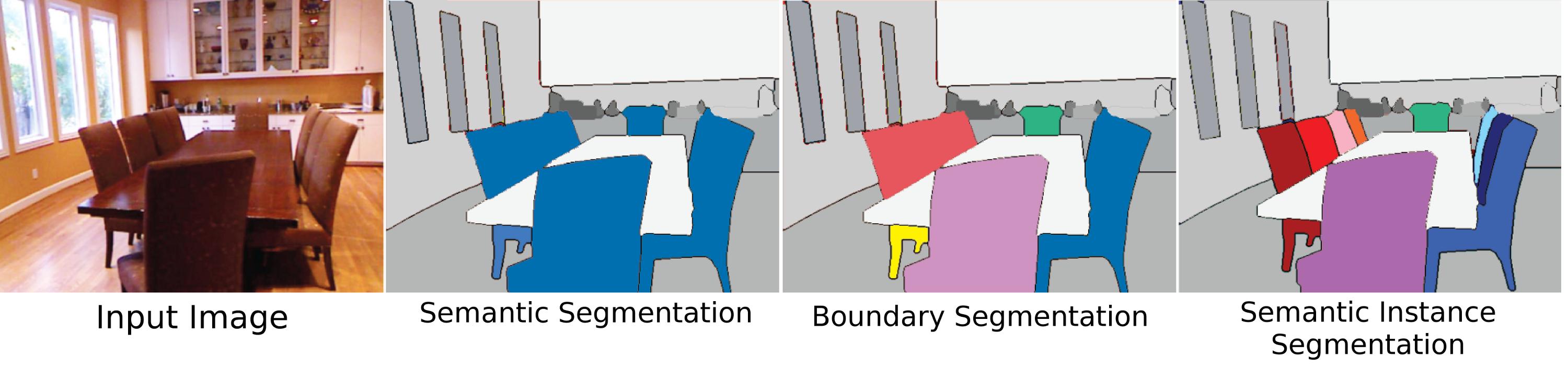
Arguably the most difficult, relevant, and original meaning of Object Segmentation, "instance segmentation" means the segmentation of the individual objects within a scene, regardless of if they are the same type. However, one of the reason this is so difficult is because from a vision perspective (and in some ways a philosophical one) what makes an "object" instance is not entirely clear. Are body parts objects? Should such "part-objects" be segmented at all by an instance segmentation algorithm? Should they be only segmented if they are seen separate from the whole? What about compound objects should two things clearly adjoined but separable be one object or two (is a rock glued to the top of a stick an ax, a hammer, or just a stick and a rock unless properly made?). Also, it isn't clear how to distinguish instances. Is a will a separate instance from the other walls it is attached to? What order should instances be counted in? As they appear? Proximity to the viewpoint? In spite of these difficulties, segmentation of objects is still a big deal because as humans we interact with objects all the time regardless of their "class label" (using random objects around you as paper weights, sitting on things that are not chairs), and so some dataset do attempt to get at this problem, but the main reason there isn't much attention given to the problem yet is because it isn't well enough defined.
![enter image description here]()
Scene Parsing/Scene labeling
Scene Parsing is the strictly segmentation approach to scene labeling, which also has some vagueness problems of its own. Historically, scene labeling meant to divide the entire "scene" (image) up into segments and give them all a class label. However, it was also used to mean giving class labels to areas of the image without explicitly segmenting them. With respect to segmentation, "semantic segmentation" does not imply dividing the entire scene. For semantic segmentation, the algorithm is intended to segment only the objects it knows, and will be penalized by its loss function for labeling pixels that don't have any label. For example the MS-COCO dataset is a dataset for semantic segmentation where only some objects are segmented.
![MS-COCO sample images]()