I stumbled upon a Stack Overflow question, How does differential execution work?, which has a VERY long and detailed answer. All of it made sense... but when I was done I still had no idea what the heck differential execution actually is. What is it really?
What is differential execution?
Asked Answered
You may ask for further explanation commenting on that answers ... –
Wendell
Still want me to try to get it across? What did you have in mind as a possible explanation? –
Absorption
REVISED. This is my Nth attempt to explain it.
Suppose you have a simple deterministic procedure that executes repeatedly, always following the same sequence of statement executions or procedure calls. The procedure calls themselves write anything they want sequentially to a FIFO, and they read the same number of bytes from the other end of the FIFO, like this:**

The procedures being called are using the FIFO as memory, because what they read is the same as what they wrote on the prior execution. So if their arguments happen to be different this time from last time, they can see that, and do anything they want with that information.
To get it started, there has to be an initial execution in which only writing happens, no reading. Symmetrically, there should be a final execution in which only reading happens, no writing. So there is a "global" mode register containing two bits, one that enables reading and one that enables writing, like this:

The initial execution is done in mode 01, so only writing is done. The procedure calls can see the mode, so they know there is no prior history. If they want to create objects they can, and put the identifying information in the FIFO (no need to store in variables).
The intermediate executions are done in mode 11, so both reading and writing happen, and the procedure calls can detect data changes. If there are objects to be kept up to date, their identifying information is read from and written to the FIFO, so they can be accessed and, if necessary, modified.
The final execution is done in mode 10, so only reading happens. In that mode, the procedure calls know they are just cleaning up. If there were any objects being maintained, their identifiers are read from the FIFO, and they can be deleted.
But real procedures do not always follow the same sequence. They contain IF statements (and other ways of varying what they do). How can that be handled?
The answer is a special kind of IF statement (and its terminating ENDIF statement). Here's how it works. It writes the boolean value of its test expression, and it reads the value that the test expression had last time. That way, it can tell if the test expression has changed, and take action. The action it takes is to temporarily alter the mode register.

Specifically, x is the prior value of the test expression, read from the FIFO (if reading is enabled, else 0), and y is the current value of the test expression, written to the FIFO (if writing is enabled). (Actually, if writing is not enabled, the test expression is not even evaluated, and y is 0.) Then x,y simply MASKs the mode register r,w. So if the test expression has changed from True to False, the body is executed in read-only mode. Conversely if it has changed from False to True, the body is executed in write-only mode. If the result is 00, the code inside the IF..ENDIF statement is skipped. (You might want to think a bit about whether this covers all cases - it does.)
It may not be obvious, but these IF..ENDIF statements can be arbitrarily nested, and they can be extended to all other kinds of conditional statements like ELSE, SWITCH, WHILE, FOR, and even calling pointer-based functions. It is also the case that the procedure can be divided into sub-procedures to any extent desired, including recursive, as long as the mode is obeyed.
(There is a rule that must be followed, called the erase-mode rule, which is that in mode 10 no computation of any consequence, such as following a pointer or indexing an array, should be done. Conceptually, the reason is that mode 10 exists only for the purpose of getting rid of stuff.)
So it is an interesting control structure that can be exploited to detect changes, typically data changes, and take action on those changes.
Its use in graphical user interfaces is to keep some set of controls or other objects in agreement with program state information. For that use, the three modes are called SHOW(01), UPDATE(11), and ERASE(10). The procedure is initially executed in SHOW mode, in which controls are created, and information relevant to them populates the FIFO. Then any number of executions are made in UPDATE mode, where the controls are modified as necessary to stay up to date with program state. Finally, there is an execution in ERASE mode, in which the controls are removed from the UI, and the FIFO is emptied.
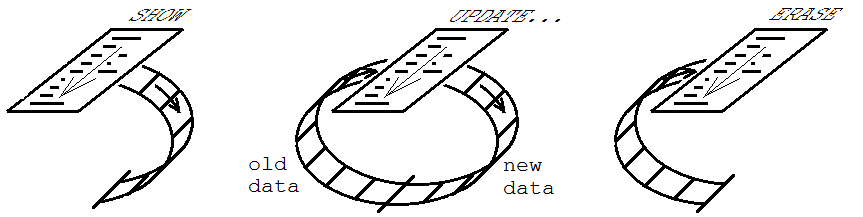
The benefit of doing this is that, once you've written the procedure to create all the controls, as a function of the program's state, you don't have to write anything else to keep it updated or clean up afterward. Anything you don't have to write means less opportunity to make mistakes. (There is a straightforward way to handle user input events without having to write event handlers and create names for them. This is explained in one of the videos linked below.)
In terms of memory management, you don't have to make up variable names or data structure to hold the controls. It only uses enough storage at any one time for the currently visible controls, while the potentially visible controls can be unlimited. Also, there is never any concern about garbage collection of previously used controls - the FIFO acts as an automatic garbage collector.
In terms of performance, when it is creating, deleting, or modifying controls, it is spending time that needs to be spent anyway. When it is simply updating controls, and there is no change, the cycles needed to do the reading, writing, and comparison are microscopic compared to altering controls.
Another performance and correctness consideration, relative to systems that update displays in response to events, is that such a system requires that every event be responded to, and none twice, otherwise the display will be incorrect, even though some event sequences may be self-canceling. Under differential execution, update passes may be performed as often or as seldom as desired, and the display is always correct at the end of a pass.
Here is an extremely abbreviated example where there are 4 buttons, of which buttons 2 and 3 are conditional on a boolean variable.
- In the first pass, in Show mode, the boolean is false, so only buttons 1 and 4 appear.
- Then the boolean is set to true and pass 2 is performed in Update mode, in which buttons 2 and 3 are instantiated and button 4 is moved, giving the same result as if the boolean had been true on the first pass.
- Then the boolean is set false and pass 3 is performed in Update mode, causing buttons 2 and 3 to be removed and button 4 to move back up to where it was before.
- Finally pass 4 is done in Erase mode, causing everything to disappear.
(In this example, the changes are undone in the reverse order as they were done, but that is not necessary. Changes can be made and unmade in any order.)
Note that, at all times, the FIFO, consisting of Old and New concatenated together, contains exactly the parameters of the visible buttons plus the boolean value.
The point of this is to show how a single "paint" procedure can also be used, without change, for arbitrary automatic incremental updating and erasing.
I hope it is clear that it works for arbitrary depth of sub-procedure calls, and arbitrary nesting of conditionals, including switch, while and for loops, calling pointer-based functions, etc.
If I have to explain that, then I'm open to potshots for making the explanation too complicated.

Finally, there are couple crude but short videos posted here.
** Technically, they have to read the same number of bytes they wrote last time. So, for example, they might have written a string preceded by a character count, and that's OK.
ADDED: It took me a long time to be sure this would always work.
I finally proved it.
It is based on a Sync property, roughly meaning that at any point in the program the number of bytes written on the prior pass equals the number read on the subsequent pass.
The idea behind the proof is to do it by induction on program length.
The toughest case to prove is the case of a section of program consisting of s1 followed by an IF(test) s2 ENDIF, where s1 and s2 are subsections of the program, each satisfying the Sync property.
To do it in text-only is eye-glazing, but here I've tried to diagram it:

It defines the Sync property, and shows the number of bytes written and read at each point in the code, and shows that they are equal. The key points are that 1) the value of the test expression (0 or 1) read on the current pass must equal the value written on the prior pass, and 2) the condition of Sync(s2) is satisfied. This satisfies the Sync property for the combined program.
I think the issue with your explanations is that you delve too deep into implementation details. 01, 10 and 11 are not really important, even the FIFO is not relevant for the main idea, it's just a handy way to store state for the elements. The functionality would be the same if each ui element had its state stored separately and then simply emit the instructions for its rendering. @Gene's "interpreter" explanation actually conveys the idea a bit clearer, IMHO; the data written into the FIFO are basically rendering instructions which will be interpreted. –
Minutes
@Groo: Thanks for your input. It's always a puzzle, how to present it. The real point is it's a domain-specific-language, but to make it work requires a control structure, and there are some hard-headed (which is good) readers who will think it's hooey unless I can explain it. –
Absorption
I read all the stuff I can find and watched the video and will take a shot at a first-principles description.
Overview
This is a DSL-based design pattern for implementing user interfaces and perhaps other state-oriented subsystems in a clean, efficient manner. It focuses on the problem of changing the GUI configuration to match current program state, where that state includes the condition of GUI widgets themselves, e.g. the user selects tabs, radio buttons, and menu items, and widgets appear/disappear in arbitrarily complex ways.
Description
The pattern assumes:
- A global collection C of objects that needs periodic updates.
- A family of types for those objects, where instances have parameters.
- A set of operations on C:
- Add A P - Put a new object A into C with parameters P.
- Modify A P - Change the parameters of object A in C to P.
- Delete A - Remove object A from C.
- An update of C consists of a sequence of such operations to transform C to a given target collection, say C'.
- Given current collection C and target C', the goal is to find the update with minimum cost. Each operation has unit cost.
- The set of possible collections is described in a domain-specific language (DSL) that has the following commands:
- Create A H - Instantiate some object A, using optional hints H, and add it to the global state. (Note no parameters here.)
- If B Then T Else F - Conditionally execute command sequence T or F based on Boolean function B, which can depend on anything in the running program.
In all the examples,
- The global state is a GUI screen or window.
- The objects are UI widgets. Types are button, dropdown box, text field, ...
- Parameters control widget appearance and behavior.
- Each update consists of adding, deleting, and modifying (e.g. relocating) any number of widgets in the GUI.
- The Create commands are making widgets: buttons, dropdown boxes, ...
- The Boolean functions depend on the underlying program state including the condition of GUI controls themselves. So changing a control can affect the screen.
Missing links
The inventor never explicitly states it, but a key idea is that we run the DSL interpreter over the program that represents all possible target collections (screens) every time we expect any combination of the Boolean function values B has changed. The interpreter handles the dirty work of making the collection (screen) consistent with the new B values by emitting a sequence of Add, Delete, and Modify operations.
There is a final hidden assumption: The DSL interpreter includes some algorithm that can provide the parameters for the Add and Modify operations based on the history of Creates executed so far during its current run. In the GUI context, this is the layout algorithm, and the Create hints are layout hints.
Punch line
The power of the technique lies in the way complexity is encapsulated in the DSL interpreter. A stupid interpreter would start by Deleting all the objects (widgets) in the collection (screen), then Add a new one for each Create command as it sees them while stepping through the DSL program. Modify would never occur.
Differential execution is just a smarter strategy for the interpreter. It amounts to keeping a serialized recording of the interpreter's last execution. This makes sense because the recording captures what's currently on the screen. During the current run, the interpreter consults the recording to make decisions about how to bring about the target collection (widget configuration) with operations having least cost. This boils out to never Deleting an object (widget) only to Add it again later for a cost of 2. DE will always Modify instead, which has a cost of 1. If we happen to run the interpreter in some case where the B values have not changed, the DE algorithm will generate no operations at all: the recorded stream already represents the target.
As the interpreter executes commands, it is also setting up the recording for its next run.
An analogous algorithm
The algorithm has the same flavor as minimum edit distance (MED). However DE is a simpler problem than MED because there are no "repeated characters" in the DE serialized execution strings as there are in MED. This means we can find an optimal solution with a straightforward on-line greedy algorithm rather than dynamic programming. That's what the inventor's algorithm does.
Strengths
My take is that this is a good pattern for implementing systems with many complex forms where you want total control over placement of widgets with your own layout algorithm and/or the "if else" logic of what's visible is deeply nested. If there are K nests of "if elses" N deep in the form logic, then there are K*2^N different layouts to get right. Traditional form design systems (at least the ones I've used) don't support larger K, N values very well at all. You tend to end up with large numbers of similar layouts and ad hoc logic to select them that's ugly and hard to maintain. This DSL pattern seems a way to avoid all that. In systems with enough forms to offset the DSL interpreter's cost, it would even be cheaper during initial implementation. Separation of concerns is also a strength. The DSL programs abstract the content of forms while the interpreter is the layout strategy, acting on hints from the DSL. Getting the DSL and layout hint design right seems like a significant and cool problem in itself.
Questionable...
I'm not sure that avoiding Delete/Add pairs in favor of Modify is worth all the trouble in modern systems. The inventor seems most proud of this optimization, but the more important idea is a concise DSL with conditionals to represent forms, with layout complexity isolated in the DSL interpreter.
Recap
The inventor's has so far has focused on deep details of how the interpreter makes its decisions. This is confusing because it's directed at trees while the forest is of greater interest. This is a description of the forest.
Thanks for your attention and good description. Indeed, I think its usefulness comes from it being a DSL, and that's a part of software engineering that needs a lot more emphasis. I would only add 1) that the word "interpreter" is a good word but might be misleading, because the code is compiled - interpreters usually have an order of magnitude performance penalty, and 2) it doesn't claim to find minimum edit distance, merely reasonable. –
Absorption
... also, I'm not sure what you're saying about layout hints. Each control has position and size, and I just compute those on the fly, either as arguments to the primitive procedures, or as "global" variables with side effects. (In computing those on the fly, the erase mode rule must be followed.) BTW, another issue is data binding, which can also be done on the fly, and doesn't require any additional data structure. –
Absorption
@MikeDunlavey Thanks Mike. Hints seemed to make sense for complex forms. Rather than just say "Button A" in the DSL, say "Button in column below Button B" or something similar. Else you lose the nice separation of concerns. Hints are similar to current traditional layout managers like Java Swing's. On the interpreter, you are describing forms in the DSL, and some chunk of code is processing the DSL to do the Adds, Deletes, Modifies. This chunk of code is by definition an interpreter. It's not new: Windows forms sinve v1.0 have the same for dialog resources, but their DSL has no conditionals! –
Auspex
Right, the resource-compiler (RC) language was a good DSL - the problem was all the cruft you had to write around it, killing its value as a DSL, like data moving and event handlers, not to mention having to name everything. What I'm trying to do is embed the DSL in the main language and make it as flexible as the main language. –
Absorption
If you're interested, there's a small implementation in C++ with MFC here. (I'm afraid I've pre-dated the Java bandwagon, though I've been through VB and C# the last several years.) Also, if you're into formal proofs, there's a dry and boring correctness proof at the bottom of my Wikipedia page. –
Absorption
Adding modify operations is definitely worth it as you can implement them as slow transitions. The whole process reminds me of d3's exit/update/enter, except d3 implements "for" loops out of the box (as array data joins) while Mike Dunlavey's algo generalizez to all control structures. –
Herne
@csiz: I finally got around to implementing this in javascript, and will soon put it in github. So far, the two files are really small. I'm a real newbie to js, css, html5, etc., so the web page it makes is painfully simple, but it does all the dynamic update and event handling. –
Absorption
@MikeDunlavey I would like to have a look when you put it on github :) –
Herne
@csiz: It's in GitHub, under my name, repository DiffExecInJS. You just open the temp.htm file. It loads the .js file and runs the contents to make 2 buttons. Then you can increase or decrease the number of buttons, and if you show the console (F12) it will show if you click a middle button. It needs a lot more pizzaz, but it's got the basic works. –
Absorption
© 2022 - 2024 — McMap. All rights reserved.