I have a dataframe with some NaN values.
Here is a sample dataframe:
sample_df = pd.DataFrame([[1,np.nan,1],[2,2,np.nan], [np.nan, 3, 3], [4,4,4],[np.nan,np.nan,5], [6,np.nan,np.nan]])
It looks like:
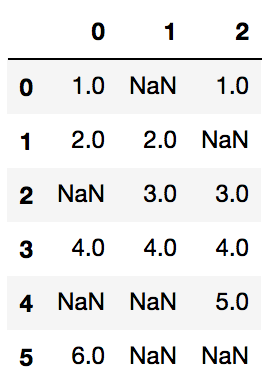
What I did after to get a json:
sample_df.to_json(orient = 'records')
Which gives:
'[{"0":1.0,"1":null,"2":1.0},{"0":2.0,"1":2.0,"2":null},{"0":null,"1":3.0,"2":3.0},{"0":4.0,"1":4.0,"2":4.0},{"0":null,"1":null,"2":5.0},{"0":6.0,"1":null,"2":null}]'
I want to save this dataframe to a json with 2 rows in each json, but with none of the Nan values. Here is how I tried to do it:
df_dict = dict((n, sample_df.iloc[n:n+2, :]) for n in range(0, len(sample_df), 2))
for k, v in df_dict.items():
print(k)
print(v)
for d in (v.to_dict('record')):
for k,v in list(d.items()):
if type(v)==float:
if math.isnan(v):
del d[k]
json.dumps(df_dict)
Output I want:
'[{"0":1.0,"2":1.0},{"0":2.0,"1":2.0}]' -> in one .json file '[{"1":3.0,"2":3.0},{"0":4.0,"1":4.0,"2":4.0}]' -> in second .json file '[{"2":5.0},{"0":6.0}]' -> in third .json file